



LLaDA-2.0: the largest text diffusion model ever
- 100B-A6B MoE architecture
- 535 tok/s
- Competitive with Qwen3-30B-A3B
🤔🤔🤔
huggingface.co/inclusionAI/...
- 100B-A6B MoE architecture
- 535 tok/s
- Competitive with Qwen3-30B-A3B
🤔🤔🤔
huggingface.co/inclusionAI/...

December 13, 2025 at 2:33 PM
LLaDA-2.0: the largest text diffusion model ever
- 100B-A6B MoE architecture
- 535 tok/s
- Competitive with Qwen3-30B-A3B
🤔🤔🤔
huggingface.co/inclusionAI/...
- 100B-A6B MoE architecture
- 535 tok/s
- Competitive with Qwen3-30B-A3B
🤔🤔🤔
huggingface.co/inclusionAI/...

Mistral dropped ministral 3B, 8B, 14B models and the big one - a seemingly deepseek shaped Mistral large 3, 675B moe brick. All apache 2!
Happy to see some European action in the usable model space.
Mistral blog post: mistral.ai/news/mistral-3
Happy to see some European action in the usable model space.
Mistral blog post: mistral.ai/news/mistral-3

December 2, 2025 at 7:19 PM
Mistral dropped ministral 3B, 8B, 14B models and the big one - a seemingly deepseek shaped Mistral large 3, 675B moe brick. All apache 2!
Happy to see some European action in the usable model space.
Mistral blog post: mistral.ai/news/mistral-3
Happy to see some European action in the usable model space.
Mistral blog post: mistral.ai/news/mistral-3
Mistral Large 3: 675B-A41B
Instruction-tuned (non-thinking), Apache 2, European open model keeps up
mistral.ai/news/mistral-3
Instruction-tuned (non-thinking), Apache 2, European open model keeps up
mistral.ai/news/mistral-3

December 2, 2025 at 10:20 PM
Mistral Large 3: 675B-A41B
Instruction-tuned (non-thinking), Apache 2, European open model keeps up
mistral.ai/news/mistral-3
Instruction-tuned (non-thinking), Apache 2, European open model keeps up
mistral.ai/news/mistral-3

、GPQA Diamond(Rein 等人,2023 年)、SimpleQA(OpenAI,2024 年c)、C-SimpleQA(He 等人,2024 年)、SWE-Bench、2024)、SWE-Bench Verified(OpenAI,2024d)、Aider 1 、LiveCodeBench(Jain 等人,2024)(2024-08 - 2025-01)、Codeforces 2 、中国全国高中数学奥林匹克竞赛(CNMO 2024) 3 和 2024 年美国数学邀请考试(AIME 2024)(MAA,2024)。
March 2, 2025 at 6:43 AM
、GPQA Diamond(Rein 等人,2023 年)、SimpleQA(OpenAI,2024 年c)、C-SimpleQA(He 等人,2024 年)、SWE-Bench、2024)、SWE-Bench Verified(OpenAI,2024d)、Aider 1 、LiveCodeBench(Jain 等人,2024)(2024-08 - 2025-01)、Codeforces 2 、中国全国高中数学奥林匹克竞赛(CNMO 2024) 3 和 2024 年美国数学邀请考试(AIME 2024)(MAA,2024)。

GemmaCoder-12B: Code-specialized Gemma-12B boosting LiveCodeBench by 50% (21.9% → 32.9%).
Fine-tuned via SFT on competitive coding (Codeforces). Thanks @ben_burtenshaw!
To run it locally, click Use this model on @huggingface and select Jan: huggingface.co/bartowski/b...
Fine-tuned via SFT on competitive coding (Codeforces). Thanks @ben_burtenshaw!
To run it locally, click Use this model on @huggingface and select Jan: huggingface.co/bartowski/b...

bartowski/burtenshaw_GemmaCoder3-12B-GGUF · Hugging Face
huggingface.co
April 8, 2025 at 2:33 AM
GemmaCoder-12B: Code-specialized Gemma-12B boosting LiveCodeBench by 50% (21.9% → 32.9%).
Fine-tuned via SFT on competitive coding (Codeforces). Thanks @ben_burtenshaw!
To run it locally, click Use this model on @huggingface and select Jan: huggingface.co/bartowski/b...
Fine-tuned via SFT on competitive coding (Codeforces). Thanks @ben_burtenshaw!
To run it locally, click Use this model on @huggingface and select Jan: huggingface.co/bartowski/b...
- 利用 DeepSeek-R1 生成的推理数据,我们对研究界广泛使用的几个密集模型进行了微调。评估结果表明,经过提炼的小型密集模型在基准测试中表现优异。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上的得分率达到 55.5%,超过了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上的得分率为72.6%,在MATH-500上的得分率为94.3%,在LiveCodeBench上的得分率为57.2%。这些结果明显优于以前的开源模型,与 o1-mini 不相上下。我们向社区开源了基于
March 2, 2025 at 5:09 AM
- 利用 DeepSeek-R1 生成的推理数据,我们对研究界广泛使用的几个密集模型进行了微调。评估结果表明,经过提炼的小型密集模型在基准测试中表现优异。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上的得分率达到 55.5%,超过了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上的得分率为72.6%,在MATH-500上的得分率为94.3%,在LiveCodeBench上的得分率为57.2%。这些结果明显优于以前的开源模型,与 o1-mini 不相上下。我们向社区开源了基于

Nvidia's AceMath-RL-Nemotron-7B, an open math model trained with reinforcement learning from the SFT-only checkpoint: Deepseek-R1-Distilled-Qwen-7B.
It achieves:
- AIME24: 69.0
- AIME25: 53.6
- LiveCodeBench: 44.4
It achieves:
- AIME24: 69.0
- AIME25: 53.6
- LiveCodeBench: 44.4

April 25, 2025 at 1:38 AM
Nvidia's AceMath-RL-Nemotron-7B, an open math model trained with reinforcement learning from the SFT-only checkpoint: Deepseek-R1-Distilled-Qwen-7B.
It achieves:
- AIME24: 69.0
- AIME25: 53.6
- LiveCodeBench: 44.4
It achieves:
- AIME24: 69.0
- AIME25: 53.6
- LiveCodeBench: 44.4

[25/30] 49 Likes, 12 Comments, 1 Posts
2505.08311, cs․CL, 13 May 2025
🆕AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale
Yunjie Ji, Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, Xiangang Li
2505.08311, cs․CL, 13 May 2025
🆕AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale
Yunjie Ji, Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, Xiangang Li

May 18, 2025 at 12:09 AM
[25/30] 49 Likes, 12 Comments, 1 Posts
2505.08311, cs․CL, 13 May 2025
🆕AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale
Yunjie Ji, Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, Xiangang Li
2505.08311, cs․CL, 13 May 2025
🆕AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale
Yunjie Ji, Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yiping Peng, Han Zhao, Xiangang Li
it’s new entrant week! today? Kimi-K2
an open weights model that’s competitive with Claude 4 Opus
- 1T, 32B active MoE
- a true agentic model, hitting all the marks on coding & tool use
- no training instability, due to MuonClip optimizer
new frontier lab to watch!
moonshotai.github.io/Kimi-K2/
an open weights model that’s competitive with Claude 4 Opus
- 1T, 32B active MoE
- a true agentic model, hitting all the marks on coding & tool use
- no training instability, due to MuonClip optimizer
new frontier lab to watch!
moonshotai.github.io/Kimi-K2/
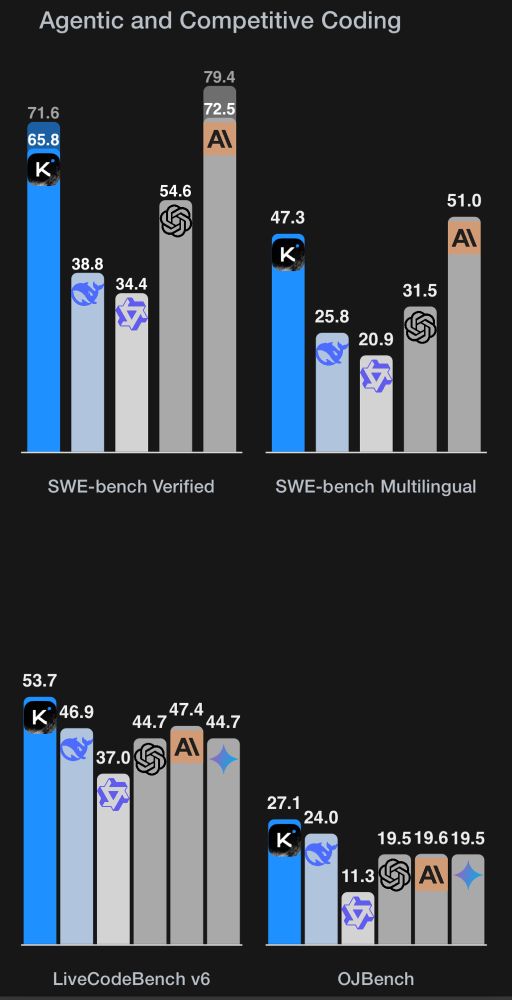
July 11, 2025 at 4:43 PM
it’s new entrant week! today? Kimi-K2
an open weights model that’s competitive with Claude 4 Opus
- 1T, 32B active MoE
- a true agentic model, hitting all the marks on coding & tool use
- no training instability, due to MuonClip optimizer
new frontier lab to watch!
moonshotai.github.io/Kimi-K2/
an open weights model that’s competitive with Claude 4 Opus
- 1T, 32B active MoE
- a true agentic model, hitting all the marks on coding & tool use
- no training instability, due to MuonClip optimizer
new frontier lab to watch!
moonshotai.github.io/Kimi-K2/


January 29, 2025 at 12:14 PM

Qwen 2.5 Coder and Qwen 3 Lead in Open Source LLM Over DeepSeek and Meta Qwen 2.5 Coder/Max is currently the top open-source model for coding, with the highest HumanEval (~70–72%), LiveCodeBench (70.7), and Elo (2056) scores among open models. DeepSee...
| Details | Interest | Feed |
| Details | Interest | Feed |
Origin
www.nextbigfuture.com
May 21, 2025 at 3:39 PM

LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
arxiv.org/pdf/2506.11928
arxiv.org/pdf/2506.11928
arxiv.org
June 19, 2025 at 5:39 PM
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
arxiv.org/pdf/2506.11928
arxiv.org/pdf/2506.11928

LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming? https://blog.quintarelli.it/2025/06/livecodebench-pro-how-do-olympiad-medalists-judge-llms-in-competitive-programming/
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Stagisti… so’ stagisti digitali.
BTW, in alcuni ambienti gira voce – totalmente non confermata – che il problema software che ha causato il down di Google Cloud di alcuni giorni fa sia stato sviluppato usando AI. Sarebbe interessante una smentita da Google, se possibile.
Source: New York University
> Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming.
>
> …we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. …
>
> Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel
Continua qui: _[2506.11928] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?_
If you like this post, please consider sharing it.
blog.quintarelli.it
June 17, 2025 at 2:05 PM
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming? https://blog.quintarelli.it/2025/06/livecodebench-pro-how-do-olympiad-medalists-judge-llms-in-competitive-programming/
LN-Ultra introduces a system prompt ("detailed thinking on/off") to switch between standard chat and multi-step reasoning. No separate models. On GPQA-Diamond, accuracy jumps from 46% (chat) to 76% (reasoning). Same pattern holds for MATH500 (80% → 97%) and LiveCodeBench.

May 6, 2025 at 10:28 AM
LN-Ultra introduces a system prompt ("detailed thinking on/off") to switch between standard chat and multi-step reasoning. No separate models. On GPQA-Diamond, accuracy jumps from 46% (chat) to 76% (reasoning). Same pattern holds for MATH500 (80% → 97%) and LiveCodeBench.

R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in [5/6 of https://arxiv.org/abs/2504.16656v1]
April 24, 2025 at 6:03 AM
R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in [5/6 of https://arxiv.org/abs/2504.16656v1]
Qwen3-Next-80B-A3B Base, Instruct & Thinking
- performs similar to Qwen3-235B-A22B
- 10% the training cost of Qwen3-32B
- 10x throughput of -32B
- outperforms Gemini-2.5-flash on some benchmarks
- native MTP for speculative decoding
qwen.ai/blog?id=4074...
- performs similar to Qwen3-235B-A22B
- 10% the training cost of Qwen3-32B
- 10x throughput of -32B
- outperforms Gemini-2.5-flash on some benchmarks
- native MTP for speculative decoding
qwen.ai/blog?id=4074...


September 11, 2025 at 8:37 PM
Qwen3-Next-80B-A3B Base, Instruct & Thinking
- performs similar to Qwen3-235B-A22B
- 10% the training cost of Qwen3-32B
- 10x throughput of -32B
- outperforms Gemini-2.5-flash on some benchmarks
- native MTP for speculative decoding
qwen.ai/blog?id=4074...
- performs similar to Qwen3-235B-A22B
- 10% the training cost of Qwen3-32B
- 10x throughput of -32B
- outperforms Gemini-2.5-flash on some benchmarks
- native MTP for speculative decoding
qwen.ai/blog?id=4074...

(\textbf{SEW}), a novel self-evolving framework that automatically generates and optimises multi-agent workflows. Extensive experiments on three coding benchmark datasets, including the challenging LiveCodeBench, demonstrate that our SEW can [4/6 of https://arxiv.org/abs/2505.18646v1]
May 27, 2025 at 6:00 AM
(\textbf{SEW}), a novel self-evolving framework that automatically generates and optimises multi-agent workflows. Extensive experiments on three coding benchmark datasets, including the challenging LiveCodeBench, demonstrate that our SEW can [4/6 of https://arxiv.org/abs/2505.18646v1]

🚀 xAI’s Grok-4 Fast just dropped:
🤖 Matches Gemini 2.5 Pro on reasoning (AAI 60)
💸 ~25× cheaper to run than rivals
⚡ 2.5× faster than GPT-5 API
🏆 #1 on LiveCodeBench
The intelligence–cost frontier just got broken.
🤖 Matches Gemini 2.5 Pro on reasoning (AAI 60)
💸 ~25× cheaper to run than rivals
⚡ 2.5× faster than GPT-5 API
🏆 #1 on LiveCodeBench
The intelligence–cost frontier just got broken.

September 21, 2025 at 12:11 AM
🚀 xAI’s Grok-4 Fast just dropped:
🤖 Matches Gemini 2.5 Pro on reasoning (AAI 60)
💸 ~25× cheaper to run than rivals
⚡ 2.5× faster than GPT-5 API
🏆 #1 on LiveCodeBench
The intelligence–cost frontier just got broken.
🤖 Matches Gemini 2.5 Pro on reasoning (AAI 60)
💸 ~25× cheaper to run than rivals
⚡ 2.5× faster than GPT-5 API
🏆 #1 on LiveCodeBench
The intelligence–cost frontier just got broken.

Time horizon isn’t relevant on all benchmarks. Hard LeetCode problems (LiveCodeBench) and math problems (AIME) are much harder for models than easy ones, but Video-MME questions on long videos aren’t much harder than on short ones.
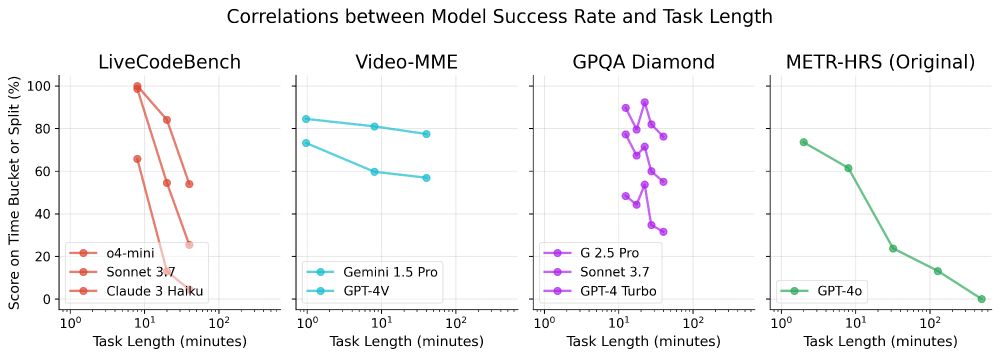
July 14, 2025 at 6:22 PM
Time horizon isn’t relevant on all benchmarks. Hard LeetCode problems (LiveCodeBench) and math problems (AIME) are much harder for models than easy ones, but Video-MME questions on long videos aren’t much harder than on short ones.
results on LiveCodeBench (20240701-20240901) demonstrate that our COT-Coder-7B-StepDPO, derived from Qwen2.5-Coder-7B-Base, with a pass@1 accuracy of 21.88, exceeds all models with similar or even larger sizes. Furthermore, our COT-Coder-32B-StepDPO, [4/6 of https://arxiv.org/abs/2505.10594v1]
May 19, 2025 at 6:00 AM
results on LiveCodeBench (20240701-20240901) demonstrate that our COT-Coder-7B-StepDPO, derived from Qwen2.5-Coder-7B-Base, with a pass@1 accuracy of 21.88, exceeds all models with similar or even larger sizes. Furthermore, our COT-Coder-32B-StepDPO, [4/6 of https://arxiv.org/abs/2505.10594v1]
expert analysis using LiveCodeBench to assess whether the correct predictions are based on sound reasoning. We also evaluated prediction stability across different code mutations on LiveCodeBench and CruxEval. Our findings show that some LLMs, such as [5/6 of https://arxiv.org/abs/2505.10443v1]
May 16, 2025 at 6:02 AM
expert analysis using LiveCodeBench to assess whether the correct predictions are based on sound reasoning. We also evaluated prediction stability across different code mutations on LiveCodeBench and CruxEval. Our findings show that some LLMs, such as [5/6 of https://arxiv.org/abs/2505.10443v1]

The newly upgraded Deepseek R1 is now nearly matching OpenAI's O3 High model on LiveCodeBench—a major victory for open source!
#DeepseekR1 #OpenSourceAI #LiveCodeBench #AIbenchmark #LLM #CodeAI #OpenAI #MachineLearning #AICommunity
#DeepseekR1 #OpenSourceAI #LiveCodeBench #AIbenchmark #LLM #CodeAI #OpenAI #MachineLearning #AICommunity

June 13, 2025 at 4:03 PM
The newly upgraded Deepseek R1 is now nearly matching OpenAI's O3 High model on LiveCodeBench—a major victory for open source!
#DeepseekR1 #OpenSourceAI #LiveCodeBench #AIbenchmark #LLM #CodeAI #OpenAI #MachineLearning #AICommunity
#DeepseekR1 #OpenSourceAI #LiveCodeBench #AIbenchmark #LLM #CodeAI #OpenAI #MachineLearning #AICommunity

Are you someone who works with code? Do you want to tell the hype from reality in #LLM coding assistants? Apple created a new coding benchmark #livecodebench with help from human Olympiad medalists, preventing contamination with continuously updated problems. Top findings 🧵
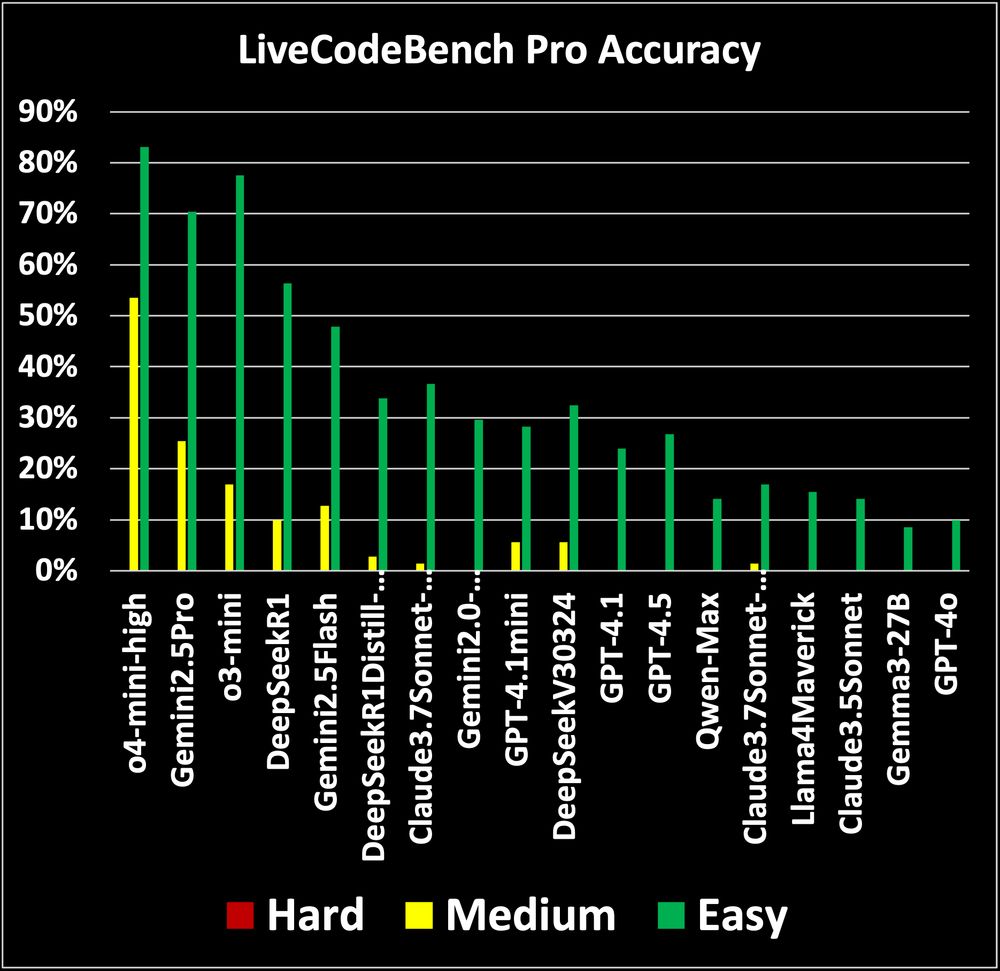
June 18, 2025 at 2:15 PM
Are you someone who works with code? Do you want to tell the hype from reality in #LLM coding assistants? Apple created a new coding benchmark #livecodebench with help from human Olympiad medalists, preventing contamination with continuously updated problems. Top findings 🧵