



Sung Kim
@sungkim.bsky.social
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
You can also find me at threads: @sung.kim.mw
PSA: Don't become a social media influencer.
December 1, 2025 at 1:10 AM
PSA: Don't become a social media influencer.
AI/ML for Biology & Healthcare: A Learning Path
The learning path author have been using to upskill self and be ready to work on biology and healthcare problems with Machine Learning.
Mastering PyTorch: From Linear Regression to Computer Vision: www.iamtk.co/mastering-py...
The learning path author have been using to upskill self and be ready to work on biology and healthcare problems with Machine Learning.
Mastering PyTorch: From Linear Regression to Computer Vision: www.iamtk.co/mastering-py...

Mastering PyTorch: From Linear Regression to Computer Vision
Learning PyTorch: tensors, operations, linear regression, datasets, dataloaders, and computer vision
www.iamtk.co
December 1, 2025 at 1:04 AM
AI/ML for Biology & Healthcare: A Learning Path
The learning path author have been using to upskill self and be ready to work on biology and healthcare problems with Machine Learning.
Mastering PyTorch: From Linear Regression to Computer Vision: www.iamtk.co/mastering-py...
The learning path author have been using to upskill self and be ready to work on biology and healthcare problems with Machine Learning.
Mastering PyTorch: From Linear Regression to Computer Vision: www.iamtk.co/mastering-py...
The Journey of a Token: What Really Happens Inside a Transformer by Iván Palomares Carrascosa
Learn how a transformer converts input tokens into context-aware representations and, ultimately, next-token probabilities.
machinelearningmastery.com/the-journey-...
Learn how a transformer converts input tokens into context-aware representations and, ultimately, next-token probabilities.
machinelearningmastery.com/the-journey-...
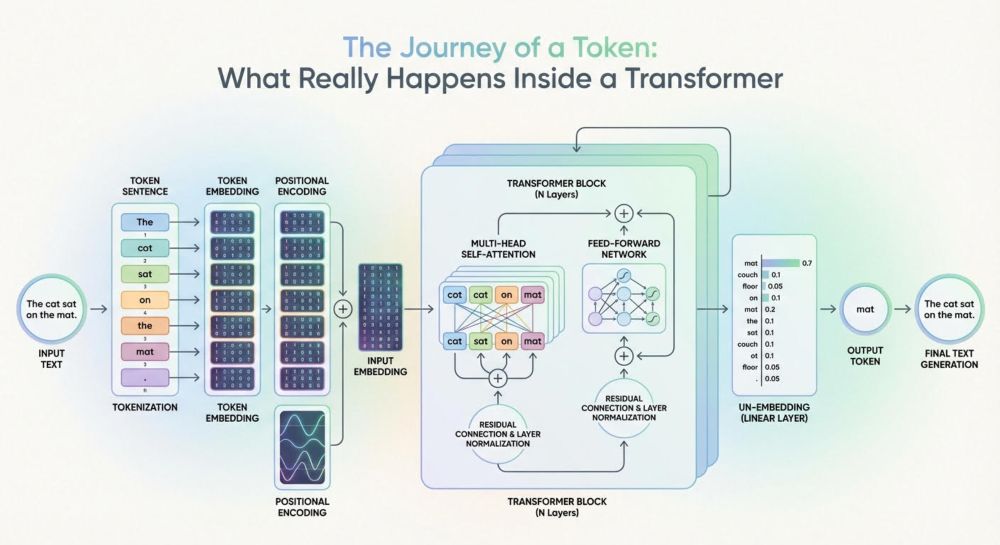
The Journey of a Token: What Really Happens Inside a Transformer - MachineLearningMastery.com
Let’s discover what happens inside a transformer model, that is, how input tokens or parts of an input text sequence turn into generated text outputs, and what is the rationale behind the changes and ...
machinelearningmastery.com
December 1, 2025 at 1:01 AM
The Journey of a Token: What Really Happens Inside a Transformer by Iván Palomares Carrascosa
Learn how a transformer converts input tokens into context-aware representations and, ultimately, next-token probabilities.
machinelearningmastery.com/the-journey-...
Learn how a transformer converts input tokens into context-aware representations and, ultimately, next-token probabilities.
machinelearningmastery.com/the-journey-...
How to prompt Nano Banana Pro by fofr
A guide on prompting Nano Banana Pro
www.fofr.ai/nano-banana-...
A guide on prompting Nano Banana Pro
www.fofr.ai/nano-banana-...

How to prompt Nano Banana Pro
Nano Banana Pro is the most flexible and capable image model available. But when it can do so much, where do you start?
www.fofr.ai
December 1, 2025 at 12:58 AM
How to prompt Nano Banana Pro by fofr
A guide on prompting Nano Banana Pro
www.fofr.ai/nano-banana-...
A guide on prompting Nano Banana Pro
www.fofr.ai/nano-banana-...
Tencent's SSA: Sparse Sparse Attention for efficient LLM processing
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102

December 1, 2025 at 12:57 AM
Tencent's SSA: Sparse Sparse Attention for efficient LLM processing
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
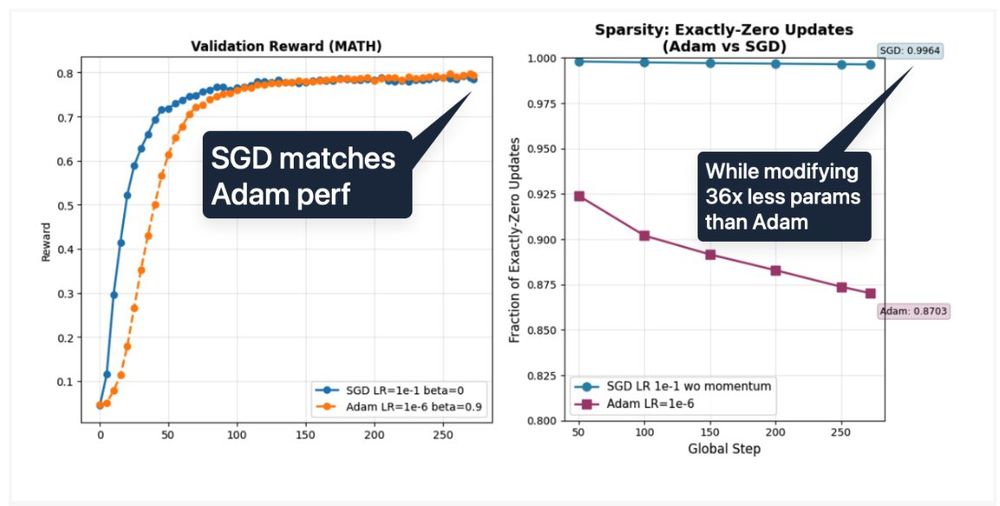
Is AdamW an overkill for RLVR?
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
December 1, 2025 at 12:53 AM
Is AdamW an overkill for RLVR?
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
How prompt caching works - Paged Attention and Automatic Prefix Caching plus practical tips by sankalp
To understand how prompt caching works, we will also need to look at basics of inference engine like vLLM and subsequently how kv-cache re-use is implemented.
sankalp.bearblog.dev/how-prompt-c...
To understand how prompt caching works, we will also need to look at basics of inference engine like vLLM and subsequently how kv-cache re-use is implemented.
sankalp.bearblog.dev/how-prompt-c...

How prompt caching works - Paged Attention and Automatic Prefix Caching plus practical tips
A deep dive into prompt caching - practical tips to improve cache hits and how vLLM's paged attention enables KV-cache reuse across requests via automatic prefix-caching
sankalp.bearblog.dev
December 1, 2025 at 12:50 AM
How prompt caching works - Paged Attention and Automatic Prefix Caching plus practical tips by sankalp
To understand how prompt caching works, we will also need to look at basics of inference engine like vLLM and subsequently how kv-cache re-use is implemented.
sankalp.bearblog.dev/how-prompt-c...
To understand how prompt caching works, we will also need to look at basics of inference engine like vLLM and subsequently how kv-cache re-use is implemented.
sankalp.bearblog.dev/how-prompt-c...
The Stage AI's TheWhisper: High-Performance Speech-to-Text (open-weight)
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).


November 30, 2025 at 2:34 AM
The Stage AI's TheWhisper: High-Performance Speech-to-Text (open-weight)
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
Huawei's Robust Orthogonalized Optimizer (ROOT), which brings two layers of robustness:
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient

November 29, 2025 at 3:22 PM
Huawei's Robust Orthogonalized Optimizer (ROOT), which brings two layers of robustness:
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
Reposted by Sung Kim

And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...

November 27, 2025 at 7:47 AM
And a major open science release from Prime Intellect: they don’t stress it enough but SFT part is beyond post-training. This is a fully documented mid-training with tons of insights/gems on MoE training, asynchronous infra RL, deep research. storage.googleapis.com/intellect-3-...
Free eBook: Learning Deep Representations of Data Distributions by Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?

November 29, 2025 at 3:06 PM
Free eBook: Learning Deep Representations of Data Distributions by Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
ByteDance Seed trained Qwen2-VL-7B-Base model to play Genshin Impact using Lumine, their generalist AI agent that can perceive, reason, and act in real time, completing hours-long missions within complex 3D open-world environments.
November 29, 2025 at 3:02 PM
ByteDance Seed trained Qwen2-VL-7B-Base model to play Genshin Impact using Lumine, their generalist AI agent that can perceive, reason, and act in real time, completing hours-long missions within complex 3D open-world environments.
Is CLIP ideal? No. Can we fix it? Yes!
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.

November 29, 2025 at 2:46 PM
Is CLIP ideal? No. Can we fix it? Yes!
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
The Q, K, V Matrices by Arpit Bhayani
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.

November 29, 2025 at 2:43 PM
The Q, K, V Matrices by Arpit Bhayani
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
Seeing like a software company by sean goedecke
Modern organizations exert control by maximising “legibility”: by altering the system so that all parts of it can be measured, reported on, and so on.
Modern organizations exert control by maximising “legibility”: by altering the system so that all parts of it can be measured, reported on, and so on.
November 29, 2025 at 2:40 PM
Seeing like a software company by sean goedecke
Modern organizations exert control by maximising “legibility”: by altering the system so that all parts of it can be measured, reported on, and so on.
Modern organizations exert control by maximising “legibility”: by altering the system so that all parts of it can be measured, reported on, and so on.
It’s interesting that AI chat growth is stalling in both the U.S. and China. So now AI companies are pivoting to reduce friction in tasks like shopping and take a cut of the transactions, but we’ll see how that goes.
November 29, 2025 at 2:30 PM
It’s interesting that AI chat growth is stalling in both the U.S. and China. So now AI companies are pivoting to reduce friction in tasks like shopping and take a cut of the transactions, but we’ll see how that goes.
I’d like to thank TSMC for locating their fabs right next to Intel, which has conveniently provided a steady pipeline of experienced fab engineers for Intel. 🤣
Intel Is Reportedly Poaching TSMC Arizona Engineers With 20–30% Higher Salaries while providing a workload that is roughly half as heavy.
Intel Is Reportedly Poaching TSMC Arizona Engineers With 20–30% Higher Salaries while providing a workload that is roughly half as heavy.

[News] Beyond Ex-VP Lo, Intel Is Reportedly Poaching TSMC Arizona Engineers With 20–30% Higher Salaries
Former TSMC senior vice president Wei-Jen Lo’s move to Intel—along with allegations that he took sub-2nm documents—has now sparked reports that Intel ...
www.trendforce.com
November 29, 2025 at 1:01 AM
I’d like to thank TSMC for locating their fabs right next to Intel, which has conveniently provided a steady pipeline of experienced fab engineers for Intel. 🤣
Intel Is Reportedly Poaching TSMC Arizona Engineers With 20–30% Higher Salaries while providing a workload that is roughly half as heavy.
Intel Is Reportedly Poaching TSMC Arizona Engineers With 20–30% Higher Salaries while providing a workload that is roughly half as heavy.
November 29, 2025 at 12:18 AM
The Parallel Decoding Trilemma by Daniel Israel
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...

November 28, 2025 at 11:55 PM
The Parallel Decoding Trilemma by Daniel Israel
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Apple’s MacBook will return to using Intel Inside.😁
November 28, 2025 at 11:45 PM
Apple’s MacBook will return to using Intel Inside.😁
StepFun's Step-Audio-R1 (open-weight)
- Test-Time Compute Scaling
- Deep Audio Comprehension
- Real-time responsiveness
- Scalable chain-of-thought reasoning for audio tasks
Comparable to Gemini 3 across major audio reasoning tasks.
huggingface.co/stepfun-ai/S...
- Test-Time Compute Scaling
- Deep Audio Comprehension
- Real-time responsiveness
- Scalable chain-of-thought reasoning for audio tasks
Comparable to Gemini 3 across major audio reasoning tasks.
huggingface.co/stepfun-ai/S...

stepfun-ai/Step-Audio-R1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 28, 2025 at 11:09 PM
StepFun's Step-Audio-R1 (open-weight)
- Test-Time Compute Scaling
- Deep Audio Comprehension
- Real-time responsiveness
- Scalable chain-of-thought reasoning for audio tasks
Comparable to Gemini 3 across major audio reasoning tasks.
huggingface.co/stepfun-ai/S...
- Test-Time Compute Scaling
- Deep Audio Comprehension
- Real-time responsiveness
- Scalable chain-of-thought reasoning for audio tasks
Comparable to Gemini 3 across major audio reasoning tasks.
huggingface.co/stepfun-ai/S...
Moonshot AI's Kimi is entering Powerpoint market, in partnership with Google's Nano Banana Pro?
kimi.com/slides
kimi.com/slides
November 28, 2025 at 11:07 PM
Moonshot AI's Kimi is entering Powerpoint market, in partnership with Google's Nano Banana Pro?
kimi.com/slides
kimi.com/slides
Bitcoin used to market itself as “digital gold,” but now you have a crypto company (Tether) literally buying gold, and in quantities larger than some countries.
You could even argue that crypto is helping drive gold’s price higher.
You could even argue that crypto is helping drive gold’s price higher.

November 28, 2025 at 11:04 PM
Bitcoin used to market itself as “digital gold,” but now you have a crypto company (Tether) literally buying gold, and in quantities larger than some countries.
You could even argue that crypto is helping drive gold’s price higher.
You could even argue that crypto is helping drive gold’s price higher.
I've recently purchased a facial moisturizing cream with salmon sperm. I'm not sure how I should feel about it.
November 28, 2025 at 8:29 AM
I've recently purchased a facial moisturizing cream with salmon sperm. I'm not sure how I should feel about it.
Why (Senior) Engineers Struggle to Build AI Agents by Phil Schmid
It's because traditional software engineering is Deterministic while agent engineering is Probabilistic. The more senior the engineer, the less they tend to trust the reasoning and instruction-following capabilities of the Agent.
It's because traditional software engineering is Deterministic while agent engineering is Probabilistic. The more senior the engineer, the less they tend to trust the reasoning and instruction-following capabilities of the Agent.
November 27, 2025 at 4:48 PM
Why (Senior) Engineers Struggle to Build AI Agents by Phil Schmid
It's because traditional software engineering is Deterministic while agent engineering is Probabilistic. The more senior the engineer, the less they tend to trust the reasoning and instruction-following capabilities of the Agent.
It's because traditional software engineering is Deterministic while agent engineering is Probabilistic. The more senior the engineer, the less they tend to trust the reasoning and instruction-following capabilities of the Agent.