



Sung Kim
@sungkim.bsky.social
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
You can also find me at threads: @sung.kim.mw
PSA: Don't become a social media influencer.
December 1, 2025 at 1:10 AM
PSA: Don't become a social media influencer.
Tencent's SSA: Sparse Sparse Attention for efficient LLM processing
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102

December 1, 2025 at 12:57 AM
Tencent's SSA: Sparse Sparse Attention for efficient LLM processing
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
SSA framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge context windows
Paper: arxiv.org/abs/2511.20102
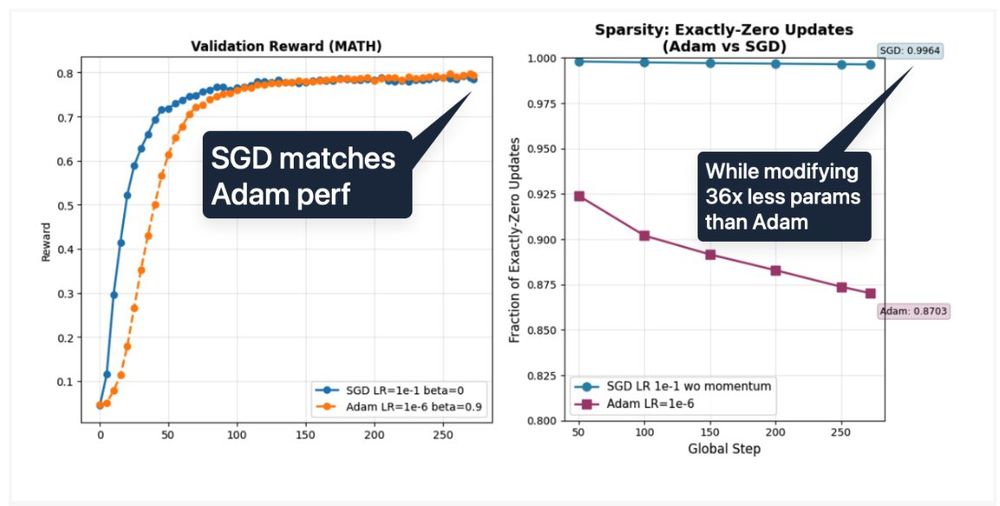
Is AdamW an overkill for RLVR?
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
December 1, 2025 at 12:53 AM
Is AdamW an overkill for RLVR?
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
They found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora)
"Who is Adam? SGD Might Be All We Need For RLVR In LLMs"
www.notion.so/sagnikm/Who-...
November 30, 2025 at 2:34 AM
The Stage AI's TheWhisper: High-Performance Speech-to-Text (open-weight)
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).


November 30, 2025 at 2:34 AM
The Stage AI's TheWhisper: High-Performance Speech-to-Text (open-weight)
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
They have optimized and fine-tuned Whisper models to handle arbitrary audio chunks and compressed them with ANNA, and added streaming inference support for both Apple's M processor and Nvidia GPUs (e.g., L40).
Huawei's Robust Orthogonalized Optimizer (ROOT), which brings two layers of robustness:
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient

November 29, 2025 at 3:22 PM
Huawei's Robust Orthogonalized Optimizer (ROOT), which brings two layers of robustness:
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
- Dimension-robust orthogonalization via adaptive Newton iterations with size-aware coefficients
- Optimization-robust updates using proximal methods that dampen harmful outliers while preserving useful gradient
Free eBook: Learning Deep Representations of Data Distributions by Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?

November 29, 2025 at 3:06 PM
Free eBook: Learning Deep Representations of Data Distributions by Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
How to effectively and efficiently learn a low-dimensional distribution of data in a high-dimensional space and then transform the distribution to a compact and structured representation?
ByteDance Seed trained Qwen2-VL-7B-Base model to play Genshin Impact using Lumine, their generalist AI agent that can perceive, reason, and act in real time, completing hours-long missions within complex 3D open-world environments.
November 29, 2025 at 3:02 PM
ByteDance Seed trained Qwen2-VL-7B-Base model to play Genshin Impact using Lumine, their generalist AI agent that can perceive, reason, and act in real time, completing hours-long missions within complex 3D open-world environments.
Is CLIP ideal? No. Can we fix it? Yes!
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.

November 29, 2025 at 2:46 PM
Is CLIP ideal? No. Can we fix it? Yes!
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
CLIP is a popular method for learning multimodal latent spaces with well-organized semantics. Despite its wide range of applications, CLIP's latent space is known to fail at handling complex visual-textual interactions.
The Q, K, V Matrices by Arpit Bhayani
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.

November 29, 2025 at 2:43 PM
The Q, K, V Matrices by Arpit Bhayani
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
At the core of the attention mechanism in LLMs are three matrices: Query, Key, and Value. These matrices are how transformers actually pay attention to different parts of the input.
November 29, 2025 at 12:18 AM
The Parallel Decoding Trilemma by Daniel Israel
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...

November 28, 2025 at 11:55 PM
The Parallel Decoding Trilemma by Daniel Israel
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Parallel decoding is a fight to increase speed while maintaining fluency and diversity, especially with the proliferation of diffusion language models.
danielmisrael.github.io/posts/2025/1...
Moonshot AI's Kimi is entering Powerpoint market, in partnership with Google's Nano Banana Pro?
kimi.com/slides
kimi.com/slides
November 28, 2025 at 11:07 PM
Moonshot AI's Kimi is entering Powerpoint market, in partnership with Google's Nano Banana Pro?
kimi.com/slides
kimi.com/slides
Bitcoin used to market itself as “digital gold,” but now you have a crypto company (Tether) literally buying gold, and in quantities larger than some countries.
You could even argue that crypto is helping drive gold’s price higher.
You could even argue that crypto is helping drive gold’s price higher.

November 28, 2025 at 11:04 PM
Bitcoin used to market itself as “digital gold,” but now you have a crypto company (Tether) literally buying gold, and in quantities larger than some countries.
You could even argue that crypto is helping drive gold’s price higher.
You could even argue that crypto is helping drive gold’s price higher.
I'm not sure this is better than AST-Grep (ast-grep.github.io), but someone try this tell me which is better.
Fully open source, local semantic code search for Claude Code that works. osgrep -v2 is live!
36% faster answers, 23% cheaper, 70% win rate
Fully open source, local semantic code search for Claude Code that works. osgrep -v2 is live!
36% faster answers, 23% cheaper, 70% win rate

November 27, 2025 at 4:39 PM
I'm not sure this is better than AST-Grep (ast-grep.github.io), but someone try this tell me which is better.
Fully open source, local semantic code search for Claude Code that works. osgrep -v2 is live!
36% faster answers, 23% cheaper, 70% win rate
Fully open source, local semantic code search for Claude Code that works. osgrep -v2 is live!
36% faster answers, 23% cheaper, 70% win rate
Princeton introduces a general hierarchical graph learning method that learns structured, interpretable motion directly from data, no prior structure or assumptions needed.
Project, paper, supplement, and code (???): light.princeton.edu/publication/...
Project, paper, supplement, and code (???): light.princeton.edu/publication/...
November 27, 2025 at 4:35 PM
Princeton introduces a general hierarchical graph learning method that learns structured, interpretable motion directly from data, no prior structure or assumptions needed.
Project, paper, supplement, and code (???): light.princeton.edu/publication/...
Project, paper, supplement, and code (???): light.princeton.edu/publication/...
FreeFlow: A predictor-corrector framework.
1️⃣ Prediction: learns to "ride" the teacher's vector field, constructing the generative path.
2️⃣ Correction: stabilizes the trajectory by actively rectifying compounding errors.
1️⃣ Prediction: learns to "ride" the teacher's vector field, constructing the generative path.
2️⃣ Correction: stabilizes the trajectory by actively rectifying compounding errors.

November 27, 2025 at 4:31 PM
FreeFlow: A predictor-corrector framework.
1️⃣ Prediction: learns to "ride" the teacher's vector field, constructing the generative path.
2️⃣ Correction: stabilizes the trajectory by actively rectifying compounding errors.
1️⃣ Prediction: learns to "ride" the teacher's vector field, constructing the generative path.
2️⃣ Correction: stabilizes the trajectory by actively rectifying compounding errors.
text rendering that are comparable to leading commercial models.
Repo: github.com/Tongyi-MAI/Z-Image
ModelScope: modelscope.ai/models/Tongy...
HuggingFace: huggingface.co/Tongyi-MAI/Z...
Z-Image gallery : modelscope.cn/studios/Tong...
Repo: github.com/Tongyi-MAI/Z-Image
ModelScope: modelscope.ai/models/Tongy...
HuggingFace: huggingface.co/Tongyi-MAI/Z...
Z-Image gallery : modelscope.cn/studios/Tong...

November 27, 2025 at 4:25 PM
text rendering that are comparable to leading commercial models.
Repo: github.com/Tongyi-MAI/Z-Image
ModelScope: modelscope.ai/models/Tongy...
HuggingFace: huggingface.co/Tongyi-MAI/Z...
Z-Image gallery : modelscope.cn/studios/Tong...
Repo: github.com/Tongyi-MAI/Z-Image
ModelScope: modelscope.ai/models/Tongy...
HuggingFace: huggingface.co/Tongyi-MAI/Z...
Z-Image gallery : modelscope.cn/studios/Tong...
Alibaba's Z-Image, an efficient 6-billion-parameter foundation model for image generation
Through systematic optimization, it proves that top-tier performance is achievable without relying on enormous model sizes, delivering strong results in photorealistic generation and bilingual
Through systematic optimization, it proves that top-tier performance is achievable without relying on enormous model sizes, delivering strong results in photorealistic generation and bilingual

November 27, 2025 at 4:25 PM
Alibaba's Z-Image, an efficient 6-billion-parameter foundation model for image generation
Through systematic optimization, it proves that top-tier performance is achievable without relying on enormous model sizes, delivering strong results in photorealistic generation and bilingual
Through systematic optimization, it proves that top-tier performance is achievable without relying on enormous model sizes, delivering strong results in photorealistic generation and bilingual
Paper: arxiv.org/abs/2511.21689
Homepage: research.nvidia.com/labs/lpr/Too...
Model: huggingface.co/nvidia/Orche...
Data: huggingface.co/datasets/nvi...
Code: github.com/NVlabs/ToolO...
Homepage: research.nvidia.com/labs/lpr/Too...
Model: huggingface.co/nvidia/Orche...
Data: huggingface.co/datasets/nvi...
Code: github.com/NVlabs/ToolO...

November 27, 2025 at 4:20 PM
Nvidia's ToolOrchestra, an end-to-end RL training framework for orchestrating tools and agentic workflows
Findings:
👉 Just prompting the agent workflow won’t cut it. It’s not how you build the best agent.
👉 Without learning, workflows plateau fast.
Findings:
👉 Just prompting the agent workflow won’t cut it. It’s not how you build the best agent.
👉 Without learning, workflows plateau fast.

November 27, 2025 at 4:20 PM
Nvidia's ToolOrchestra, an end-to-end RL training framework for orchestrating tools and agentic workflows
Findings:
👉 Just prompting the agent workflow won’t cut it. It’s not how you build the best agent.
👉 Without learning, workflows plateau fast.
Findings:
👉 Just prompting the agent workflow won’t cut it. It’s not how you build the best agent.
👉 Without learning, workflows plateau fast.
SkyRL-Agent, a framework for efficient RL agent training.
⚡ 1.55× faster async rollout dispatch
🛠 Lightweight tool + task integration
🔄 Backend-agnostic (SkyRL-train / VeRL / Tinker)
Repo: github.com/NovaSky-AI/S...
Paper: arxiv.org/abs/2511.16108
⚡ 1.55× faster async rollout dispatch
🛠 Lightweight tool + task integration
🔄 Backend-agnostic (SkyRL-train / VeRL / Tinker)
Repo: github.com/NovaSky-AI/S...
Paper: arxiv.org/abs/2511.16108

November 27, 2025 at 4:16 PM
SkyRL-Agent, a framework for efficient RL agent training.
⚡ 1.55× faster async rollout dispatch
🛠 Lightweight tool + task integration
🔄 Backend-agnostic (SkyRL-train / VeRL / Tinker)
Repo: github.com/NovaSky-AI/S...
Paper: arxiv.org/abs/2511.16108
⚡ 1.55× faster async rollout dispatch
🛠 Lightweight tool + task integration
🔄 Backend-agnostic (SkyRL-train / VeRL / Tinker)
Repo: github.com/NovaSky-AI/S...
Paper: arxiv.org/abs/2511.16108
Nvidia released TiDAR, a hybrid architecture that combines diffusion-based parallel drafting with autoregressive sampling into a single model forward pass.
Paper: www.arxiv.org/abs/2511.089...
Model: ???
Paper: www.arxiv.org/abs/2511.089...
Model: ???

November 26, 2025 at 2:52 PM
Nvidia released TiDAR, a hybrid architecture that combines diffusion-based parallel drafting with autoregressive sampling into a single model forward pass.
Paper: www.arxiv.org/abs/2511.089...
Model: ???
Paper: www.arxiv.org/abs/2511.089...
Model: ???

November 26, 2025 at 2:49 PM
Hands-On Machine Learning with Scikit-Learn and PyTorch added an online appendix on State-Space Models (SSMs)
ageron.github.io/homlp/HOMLP_...
ageron.github.io/homlp/HOMLP_...

November 26, 2025 at 2:47 PM
Hands-On Machine Learning with Scikit-Learn and PyTorch added an online appendix on State-Space Models (SSMs)
ageron.github.io/homlp/HOMLP_...
ageron.github.io/homlp/HOMLP_...