



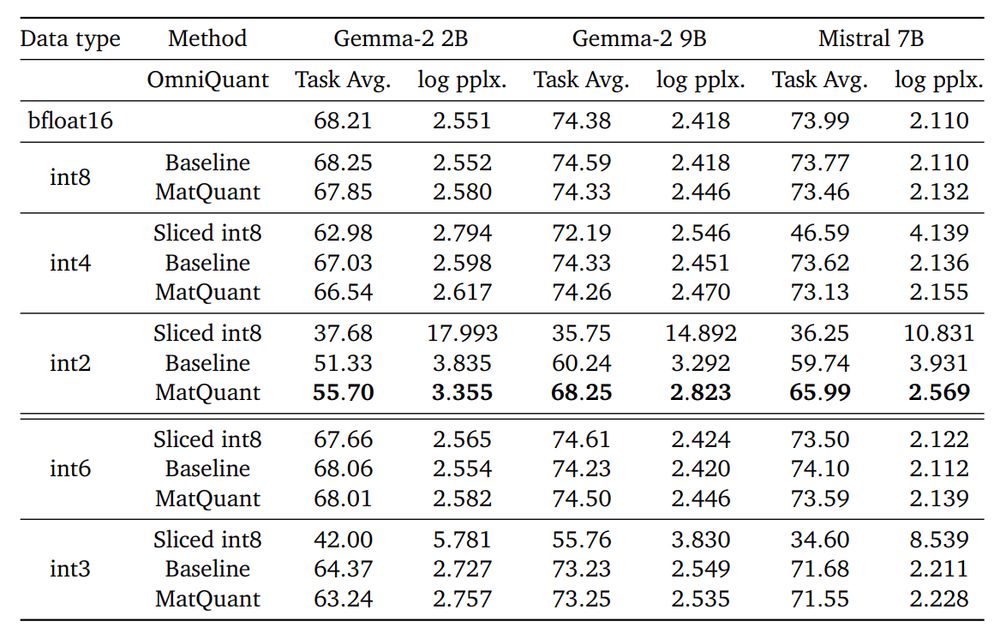
Main results of MatQuant:
• Keeps int8 and int4 accuracy high. They perform just as well as traditional methods, while using a shared structure.
• Massively improves int2 models with up to 8% accuracy boost.
• Lets you extract int6 and int3 models without separate training.
...
• Keeps int8 and int4 accuracy high. They perform just as well as traditional methods, while using a shared structure.
• Massively improves int2 models with up to 8% accuracy boost.
• Lets you extract int6 and int3 models without separate training.
...
February 13, 2025 at 10:36 PM
Main results of MatQuant:
• Keeps int8 and int4 accuracy high. They perform just as well as traditional methods, while using a shared structure.
• Massively improves int2 models with up to 8% accuracy boost.
• Lets you extract int6 and int3 models without separate training.
...
• Keeps int8 and int4 accuracy high. They perform just as well as traditional methods, while using a shared structure.
• Massively improves int2 models with up to 8% accuracy boost.
• Lets you extract int6 and int3 models without separate training.
...

今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
本リポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を紹介することを目的としている。
本モデルは、ステップバイステップの推論と動的なツール呼び出しに優れる思考エージェントであり、複数の主要ベンチマークでSOTAを達成した。
ネイティブINT4量子化と256Kのコンテキストウィンドウにより、効率的な推論性能と高度な思考能力を両立させている。
moonshotai/Kimi-K2-Thinking
本リポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を紹介することを目的としている。
本モデルは、ステップバイステップの推論と動的なツール呼び出しに優れる思考エージェントであり、複数の主要ベンチマークでSOTAを達成した。
ネイティブINT4量子化と256Kのコンテキストウィンドウにより、効率的な推論性能と高度な思考能力を両立させている。

moonshotai/Kimi-K2-Thinking · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 23, 2025 at 10:16 AM
今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
本リポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を紹介することを目的としている。
本モデルは、ステップバイステップの推論と動的なツール呼び出しに優れる思考エージェントであり、複数の主要ベンチマークでSOTAを達成した。
ネイティブINT4量子化と256Kのコンテキストウィンドウにより、効率的な推論性能と高度な思考能力を両立させている。
moonshotai/Kimi-K2-Thinking
本リポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を紹介することを目的としている。
本モデルは、ステップバイステップの推論と動的なツール呼び出しに優れる思考エージェントであり、複数の主要ベンチマークでSOTAを達成した。
ネイティブINT4量子化と256Kのコンテキストウィンドウにより、効率的な推論性能と高度な思考能力を両立させている。

المُلخص:
- تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين.
- يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة ألعاب 1080 بكسل إلى 4K.
- يتضمن Snapdragon 6 Gen 4 دعمًا جديدًا لـ INT4 لتشغيل نماذج LLM المحسّنة في ذاكرة
www.dztechy.com/qualcomm-sna...
- تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين.
- يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة ألعاب 1080 بكسل إلى 4K.
- يتضمن Snapdragon 6 Gen 4 دعمًا جديدًا لـ INT4 لتشغيل نماذج LLM المحسّنة في ذاكرة
www.dztechy.com/qualcomm-sna...

Snapdragon 6 من الجيل الرابع: نقلة نوعية في عالم الهواتف المتوسطة
المُلخص: تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين. يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة
www.dztechy.com
February 25, 2025 at 2:24 PM
المُلخص:
- تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين.
- يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة ألعاب 1080 بكسل إلى 4K.
- يتضمن Snapdragon 6 Gen 4 دعمًا جديدًا لـ INT4 لتشغيل نماذج LLM المحسّنة في ذاكرة
www.dztechy.com/qualcomm-sna...
- تم تصنيع معالج Snapdragon 6 Gen 4 بتقنية 4 نانومتر من TSMC، مما يوفر أداءً وكفاءةً محسنين.
- يتميز بوحدة معالجة رسومات أفضل بنسبة 29%، وترقية دقة ألعاب 1080 بكسل إلى 4K.
- يتضمن Snapdragon 6 Gen 4 دعمًا جديدًا لـ INT4 لتشغيل نماذج LLM المحسّنة في ذاكرة
www.dztechy.com/qualcomm-sna...

So AMD stated that the AIE in Ryzen 7040 / Phoenix Point can achieve "Up to 12 AI TOPS"
Assuming this is INT4, we're probably looking at 8 AIE-ML Tiles @ ~1,46GHz, the slowest Xilinx AIE ever
Make no mistake, this is a low power co-processor much slower than the iGPU
Assuming this is INT4, we're probably looking at 8 AIE-ML Tiles @ ~1,46GHz, the slowest Xilinx AIE ever
Make no mistake, this is a low power co-processor much slower than the iGPU
November 23, 2024 at 1:18 PM
So AMD stated that the AIE in Ryzen 7040 / Phoenix Point can achieve "Up to 12 AI TOPS"
Assuming this is INT4, we're probably looking at 8 AIE-ML Tiles @ ~1,46GHz, the slowest Xilinx AIE ever
Make no mistake, this is a low power co-processor much slower than the iGPU
Assuming this is INT4, we're probably looking at 8 AIE-ML Tiles @ ~1,46GHz, the slowest Xilinx AIE ever
Make no mistake, this is a low power co-processor much slower than the iGPU

December 31, 2024 at 9:31 AM

With int4 we could probably do it for less than 50k haha
February 7, 2025 at 5:15 AM
With int4 we could probably do it for less than 50k haha

💡 Snapdragon 6 Gen 4, il nuovo processore di fascia media di Qualcomm
gomoot.com/snapdragon-6...
#5g #blog #bluetooth 5.4 #cpu #gpu #int4 #kryo #lossless #lpddr5 #news #npu #picks #qualcomm #snapdragon6gen4 #tech #tecnologia #wifi6e
gomoot.com/snapdragon-6...
#5g #blog #bluetooth 5.4 #cpu #gpu #int4 #kryo #lossless #lpddr5 #news #npu #picks #qualcomm #snapdragon6gen4 #tech #tecnologia #wifi6e

Snapdragon 6 Gen 4, il nuovo processore di fascia media
Snapdragon 6 Gen 4, il nuovo processore di Qualcomm introduce AI on-device e migliora prestazioni, efficienza e connettività per gli smartphone di fascia media
gomoot.com
February 12, 2025 at 4:01 PM
💡 Snapdragon 6 Gen 4, il nuovo processore di fascia media di Qualcomm
gomoot.com/snapdragon-6...
#5g #blog #bluetooth 5.4 #cpu #gpu #int4 #kryo #lossless #lpddr5 #news #npu #picks #qualcomm #snapdragon6gen4 #tech #tecnologia #wifi6e
gomoot.com/snapdragon-6...
#5g #blog #bluetooth 5.4 #cpu #gpu #int4 #kryo #lossless #lpddr5 #news #npu #picks #qualcomm #snapdragon6gen4 #tech #tecnologia #wifi6e

💡 Summary:
Googleは、消費者向けのGPUに最適化された新世代のAIモデル「Gemma 3」を発表しました。これにより、手の届くハードウェア上で強力なAI機能を実現します。これらのモデルは、量子化対応トレーニング(QAT)を利用して、性能の質を維持しながらメモリ要件を大幅に削減します。例えば、Gemma 3の27BモデルのVRAM要件は、54GB(BFloat16)から14.1GB(int4)に減少し、NVIDIA RTX 3090のようなGPUで動作可能になります。これらのモデルは、人気のあるツールとの統合が容易に設計されており、 (1/2)
Googleは、消費者向けのGPUに最適化された新世代のAIモデル「Gemma 3」を発表しました。これにより、手の届くハードウェア上で強力なAI機能を実現します。これらのモデルは、量子化対応トレーニング(QAT)を利用して、性能の質を維持しながらメモリ要件を大幅に削減します。例えば、Gemma 3の27BモデルのVRAM要件は、54GB(BFloat16)から14.1GB(int4)に減少し、NVIDIA RTX 3090のようなGPUで動作可能になります。これらのモデルは、人気のあるツールとの統合が容易に設計されており、 (1/2)
April 20, 2025 at 7:43 PM
💡 Summary:
Googleは、消費者向けのGPUに最適化された新世代のAIモデル「Gemma 3」を発表しました。これにより、手の届くハードウェア上で強力なAI機能を実現します。これらのモデルは、量子化対応トレーニング(QAT)を利用して、性能の質を維持しながらメモリ要件を大幅に削減します。例えば、Gemma 3の27BモデルのVRAM要件は、54GB(BFloat16)から14.1GB(int4)に減少し、NVIDIA RTX 3090のようなGPUで動作可能になります。これらのモデルは、人気のあるツールとの統合が容易に設計されており、 (1/2)
Googleは、消費者向けのGPUに最適化された新世代のAIモデル「Gemma 3」を発表しました。これにより、手の届くハードウェア上で強力なAI機能を実現します。これらのモデルは、量子化対応トレーニング(QAT)を利用して、性能の質を維持しながらメモリ要件を大幅に削減します。例えば、Gemma 3の27BモデルのVRAM要件は、54GB(BFloat16)から14.1GB(int4)に減少し、NVIDIA RTX 3090のようなGPUで動作可能になります。これらのモデルは、人気のあるツールとの統合が容易に設計されており、 (1/2)

48+ isnt even necessary for a good coding model these days. 32 becoming common would be fire, like the radeon r9700. with that you can run a competent coding model at int4 or 6 quant
November 30, 2025 at 6:45 PM
48+ isnt even necessary for a good coding model these days. 32 becoming common would be fire, like the radeon r9700. with that you can run a competent coding model at int4 or 6 quant

sigam minha banda galera
Int4: mefuriaband
Tiktok: mefuriaband
www.instagram.com/mefuriaband?...
#sdv #banda #band
Int4: mefuriaband
Tiktok: mefuriaband
www.instagram.com/mefuriaband?...
#sdv #banda #band
September 8, 2024 at 7:48 PM
sigam minha banda galera
Int4: mefuriaband
Tiktok: mefuriaband
www.instagram.com/mefuriaband?...
#sdv #banda #band
Int4: mefuriaband
Tiktok: mefuriaband
www.instagram.com/mefuriaband?...
#sdv #banda #band

To be soecific, the gains for FP16 compute and rasterization are small vs last gen, but INT4 and memory bandwidth are way up.. that's pretty firmly aimed at AI and not gaming
Gamers find to stick with 4090 which should get cheaper
I'm still rocking 3090..
Gamers find to stick with 4090 which should get cheaper
I'm still rocking 3090..
January 12, 2025 at 7:12 AM
To be soecific, the gains for FP16 compute and rasterization are small vs last gen, but INT4 and memory bandwidth are way up.. that's pretty firmly aimed at AI and not gaming
Gamers find to stick with 4090 which should get cheaper
I'm still rocking 3090..
Gamers find to stick with 4090 which should get cheaper
I'm still rocking 3090..

Having fun on the job reporting a bug... "It is bigger than can fit in a int4 or int8 database column. I'm guessing a transcription mistake as 119,912,041,208,212,624,056 pages is larger than the Library of Alexandria, The Vatican Archives, and the Library of Congress COMBINED"
November 26, 2025 at 11:04 PM
Having fun on the job reporting a bug... "It is bigger than can fit in a int4 or int8 database column. I'm guessing a transcription mistake as 119,912,041,208,212,624,056 pages is larger than the Library of Alexandria, The Vatican Archives, and the Library of Congress COMBINED"

Like this, right here:
"But it will have 24 sparse tensor tflops fp16, or 48 sparse tensor tops int8, or 96 Sparse tensor tops int4, out of its tensor cores, per ghz."
...is just lazy. It's a statdump. Nobody's reading that mess, it's not even remotely grammatical.
Try. Harder.
"But it will have 24 sparse tensor tflops fp16, or 48 sparse tensor tops int8, or 96 Sparse tensor tops int4, out of its tensor cores, per ghz."
...is just lazy. It's a statdump. Nobody's reading that mess, it's not even remotely grammatical.
Try. Harder.
October 9, 2024 at 6:18 AM
Like this, right here:
"But it will have 24 sparse tensor tflops fp16, or 48 sparse tensor tops int8, or 96 Sparse tensor tops int4, out of its tensor cores, per ghz."
...is just lazy. It's a statdump. Nobody's reading that mess, it's not even remotely grammatical.
Try. Harder.
"But it will have 24 sparse tensor tflops fp16, or 48 sparse tensor tops int8, or 96 Sparse tensor tops int4, out of its tensor cores, per ghz."
...is just lazy. It's a statdump. Nobody's reading that mess, it's not even remotely grammatical.
Try. Harder.

From the same research paper in which I discovered this fact: "However, inference with sub-INT4 precision is more challenging, *and it is currently a very active area of research*" (emphasis mine).
March 2, 2025 at 3:22 PM
From the same research paper in which I discovered this fact: "However, inference with sub-INT4 precision is more challenging, *and it is currently a very active area of research*" (emphasis mine).
今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
このリポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を提供するものです。
K2 Thinkingは、MoEアーキテクチャに基づき、ステップバイステップの推論と動的ツール呼び出しに特化しています。
256Kの長大なコンテキストとINT4量子化により、高い性能と効率性を両立させ、主要な推論ベンチマークで最先端の結果を示しています。
moonshotai/Kimi-K2-Thinking
このリポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を提供するものです。
K2 Thinkingは、MoEアーキテクチャに基づき、ステップバイステップの推論と動的ツール呼び出しに特化しています。
256Kの長大なコンテキストとINT4量子化により、高い性能と効率性を両立させ、主要な推論ベンチマークで最先端の結果を示しています。
moonshotai/Kimi-K2-Thinking · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 9, 2025 at 10:15 AM
今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
このリポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を提供するものです。
K2 Thinkingは、MoEアーキテクチャに基づき、ステップバイステップの推論と動的ツール呼び出しに特化しています。
256Kの長大なコンテキストとINT4量子化により、高い性能と効率性を両立させ、主要な推論ベンチマークで最先端の結果を示しています。
moonshotai/Kimi-K2-Thinking
このリポジトリは、最新のオープンソース思考モデル「Kimi K2 Thinking」を公開し、その詳細を提供するものです。
K2 Thinkingは、MoEアーキテクチャに基づき、ステップバイステップの推論と動的ツール呼び出しに特化しています。
256Kの長大なコンテキストとINT4量子化により、高い性能と効率性を両立させ、主要な推論ベンチマークで最先端の結果を示しています。

12/1/2024
Elon Musk files injunction against OpenAI to stop its move to become a for-profit company.[1] OpenAI's Altman confident Trump will keep US in AI lead.[2] Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation…
http://bushaicave.com/2024/12/01/12-1-2024/
Elon Musk files injunction against OpenAI to stop its move to become a for-profit company.[1] OpenAI's Altman confident Trump will keep US in AI lead.[2] Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation…
http://bushaicave.com/2024/12/01/12-1-2024/
December 2, 2024 at 4:51 AM
12/1/2024
Elon Musk files injunction against OpenAI to stop its move to become a for-profit company.[1] OpenAI's Altman confident Trump will keep US in AI lead.[2] Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation…
http://bushaicave.com/2024/12/01/12-1-2024/
Elon Musk files injunction against OpenAI to stop its move to become a for-profit company.[1] OpenAI's Altman confident Trump will keep US in AI lead.[2] Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation…
http://bushaicave.com/2024/12/01/12-1-2024/

Grok 3 がもうすぐ来る!
「Grok 3 チャットボットは、10 万個の NVIDIA H100 GPU を搭載した Colossus スーパークラスターでトレーニングされると言われ、主要な AI モデルよりも優れたパフォーマンスを発揮する可能性がある」とのこと。
「Grok 3 チャットボットは、10 万個の NVIDIA H100 GPU を搭載した Colossus スーパークラスターでトレーニングされると言われ、主要な AI モデルよりも優れたパフォーマンスを発揮する可能性がある」とのこと。

January 21, 2025 at 12:35 PM
Grok 3 がもうすぐ来る!
「Grok 3 チャットボットは、10 万個の NVIDIA H100 GPU を搭載した Colossus スーパークラスターでトレーニングされると言われ、主要な AI モデルよりも優れたパフォーマンスを発揮する可能性がある」とのこと。
「Grok 3 チャットボットは、10 万個の NVIDIA H100 GPU を搭載した Colossus スーパークラスターでトレーニングされると言われ、主要な AI モデルよりも優れたパフォーマンスを発揮する可能性がある」とのこと。

for lower dimension counts it will stick to the old default of int8
and if you want to make any customizations, you can now configure any combination of BBQ, int4, int8, float32 + flat or HNSW 4/8
and if you want to make any customizations, you can now configure any combination of BBQ, int4, int8, float32 + flat or HNSW 4/8
August 4, 2025 at 10:01 PM
for lower dimension counts it will stick to the old default of int8
and if you want to make any customizations, you can now configure any combination of BBQ, int4, int8, float32 + flat or HNSW 4/8
and if you want to make any customizations, you can now configure any combination of BBQ, int4, int8, float32 + flat or HNSW 4/8

The more time goes on, the more unbelievable it is that NVIDIA delivered Pascal (hello HBM and unified mem access counters), Volta (ML acceleration, Independent thread scheduling and ATS) and Turing (GSP, int4/int8 on tensor cores, mesh shaders and HW RT) across 3 years.
And Turing still looks […]
And Turing still looks […]
Original post on mastodon.social
mastodon.social
September 9, 2025 at 7:12 PM
The more time goes on, the more unbelievable it is that NVIDIA delivered Pascal (hello HBM and unified mem access counters), Volta (ML acceleration, Independent thread scheduling and ATS) and Turing (GSP, int4/int8 on tensor cores, mesh shaders and HW RT) across 3 years.
And Turing still looks […]
And Turing still looks […]

Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation Model for Human-AI Conversations
https://www.marktechpost.com/2024/11/30/meta-ai-releases-llama-guard-3-1b-int4-a-compact-and-high-performance-ai-moderation-model-for-human-ai-conversations/
#Ai
https://www.marktechpost.com/2024/11/30/meta-ai-releases-llama-guard-3-1b-int4-a-compact-and-high-performance-ai-moderation-model-for-human-ai-conversations/
#Ai

Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation Model for Human-AI Conversations - MarkTechPost
Generative AI systems transform how humans interact with technology, offering groundbreaking natural language processing and content generation capabilities. However, these systems pose significant risks, particularly in generating unsafe or policy-violating content. Addressing this challenge requires advanced moderation tools that ensure outputs are safe and adhere to ethical guidelines. Such tools must be effective and efficient, particularly for deployment on resource-constrained hardware such as mobile devices. One persistent challenge in deploying safety moderation models is their size and computational requirements. While powerful and accurate, large language models (LLMs) demand substantial memory and processing power, making them unsuitable for devices with limited
www.marktechpost.com
December 1, 2024 at 6:30 PM
Meta AI Releases Llama Guard 3-1B-INT4: A Compact and High-Performance AI Moderation Model for Human-AI Conversations
https://www.marktechpost.com/2024/11/30/meta-ai-releases-llama-guard-3-1b-int4-a-compact-and-high-performance-ai-moderation-model-for-human-ai-conversations/
#Ai
https://www.marktechpost.com/2024/11/30/meta-ai-releases-llama-guard-3-1b-int4-a-compact-and-high-performance-ai-moderation-model-for-human-ai-conversations/
#Ai

Enjoy seamless performance with technical optimizations like INT4 quantization, making Kimi K2 faster and more efficient. ⚡
November 7, 2025 at 3:02 PM
Enjoy seamless performance with technical optimizations like INT4 quantization, making Kimi K2 faster and more efficient. ⚡

int4 to the rescue.
January 16, 2025 at 11:57 PM
int4 to the rescue.

- Llama 4 Scout - 17 billion active parameters, 16 experts, 109 billion total parameters, 10M token context window (pre- and post-trained at 256K), fits on a single H100 GPU with Int4 quantization, surpasses Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 on benchmarks
April 5, 2025 at 7:08 PM
- Llama 4 Scout - 17 billion active parameters, 16 experts, 109 billion total parameters, 10M token context window (pre- and post-trained at 256K), fits on a single H100 GPU with Int4 quantization, surpasses Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 on benchmarks
January 20, 2025 at 8:21 PM
今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
最新鋭のオープンソース思考モデルであるKimi K2 Thinkingを紹介し、提供する。
このモデルは、動的なツール呼び出しと多段階のステップバイステップ推論を実現する思考エージェントとして構築され、主要なベンチマークで最高水準の性能を示す。
また、INT4量子化と256Kコンテキストウィンドウにより、高い効率と推論能力を両立させている。
moonshotai/Kimi-K2-Thinking
最新鋭のオープンソース思考モデルであるKimi K2 Thinkingを紹介し、提供する。
このモデルは、動的なツール呼び出しと多段階のステップバイステップ推論を実現する思考エージェントとして構築され、主要なベンチマークで最高水準の性能を示す。
また、INT4量子化と256Kコンテキストウィンドウにより、高い効率と推論能力を両立させている。
moonshotai/Kimi-K2-Thinking · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
November 19, 2025 at 10:19 AM
今日のHuggingFaceトレンド
moonshotai/Kimi-K2-Thinking
最新鋭のオープンソース思考モデルであるKimi K2 Thinkingを紹介し、提供する。
このモデルは、動的なツール呼び出しと多段階のステップバイステップ推論を実現する思考エージェントとして構築され、主要なベンチマークで最高水準の性能を示す。
また、INT4量子化と256Kコンテキストウィンドウにより、高い効率と推論能力を両立させている。
moonshotai/Kimi-K2-Thinking
最新鋭のオープンソース思考モデルであるKimi K2 Thinkingを紹介し、提供する。
このモデルは、動的なツール呼び出しと多段階のステップバイステップ推論を実現する思考エージェントとして構築され、主要なベンチマークで最高水準の性能を示す。
また、INT4量子化と256Kコンテキストウィンドウにより、高い効率と推論能力を両立させている。