



prxtml
@prxtml.bsky.social
I am real, just not actively interactive.
Reposted by prxtml

Thrilled to share the results of a great collaboration from Cinvestav Mérida, Cinvestav Zacatenco, and the University of Toronto:
Grammar-Driven SMILES Standardization with TokenSMILES.
📜 pubs.rsc.org/en/content/a...
[1/6]
Grammar-Driven SMILES Standardization with TokenSMILES.
📜 pubs.rsc.org/en/content/a...
[1/6]

November 21, 2025 at 8:12 PM
Thrilled to share the results of a great collaboration from Cinvestav Mérida, Cinvestav Zacatenco, and the University of Toronto:
Grammar-Driven SMILES Standardization with TokenSMILES.
📜 pubs.rsc.org/en/content/a...
[1/6]
Grammar-Driven SMILES Standardization with TokenSMILES.
📜 pubs.rsc.org/en/content/a...
[1/6]
Reposted by prxtml

The ultimate git cheatsheet
from beginner → advanced → intermediate
from beginner → advanced → intermediate
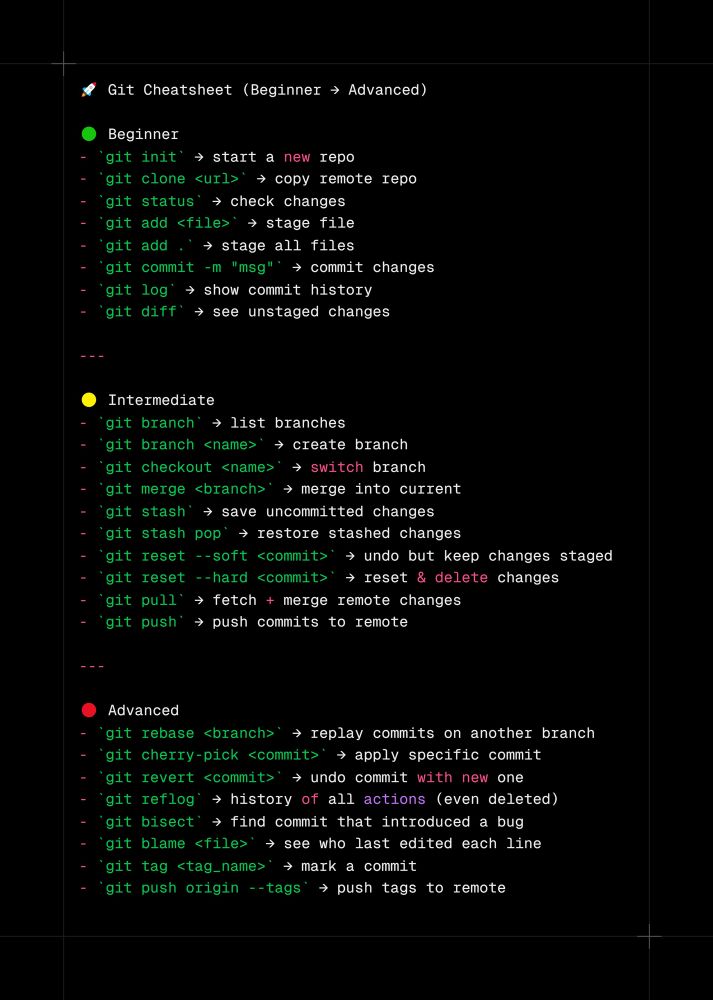
August 29, 2025 at 9:18 AM
The ultimate git cheatsheet
from beginner → advanced → intermediate
from beginner → advanced → intermediate
Reposted by prxtml

Excited to be presenting my paper "Deep Learning is Not So Mysterious or Different" tomorrow at ICML, 11 am - 1:30 pm, East Exhibition Hall A-B, E-500. I made a little video overview as part of the ICML process (viewable from Chrome): recorder-v3.slideslive.com#/share?share...
July 17, 2025 at 12:16 AM
Excited to be presenting my paper "Deep Learning is Not So Mysterious or Different" tomorrow at ICML, 11 am - 1:30 pm, East Exhibition Hall A-B, E-500. I made a little video overview as part of the ICML process (viewable from Chrome): recorder-v3.slideslive.com#/share?share...
Reposted by prxtml

2025 update to my Institutions Active in Technical Games Research ranking, which looks at who publishes in CS+games conferences and journals (AIIDE, FDG, CHI Play, IEEE ToG, etc.)
Institutions Active in Technical Games Research
www.kmjn.org
July 16, 2025 at 4:08 PM
2025 update to my Institutions Active in Technical Games Research ranking, which looks at who publishes in CS+games conferences and journals (AIIDE, FDG, CHI Play, IEEE ToG, etc.)
Reposted by prxtml

Platonists...we're back

A study shows that large language models share geometric similarities in embeddings, hinting at a universal structure. This could transform model efficiency and transfer learning by enabling the use of steering vectors across various architectures. https://arxiv.org/abs/2503.21073

Shared Global and Local Geometry of Language Model Embeddings
ArXiv link for Shared Global and Local Geometry of Language Model Embeddings
arxiv.org
July 17, 2025 at 3:14 AM
Platonists...we're back
Reposted by prxtml

In our upcoming #ICML2025 paper, we introduce the #NumberTokenLoss (NTL) to address this -- see the demo above! NTL is a regression-style loss computed at the token level—no extra regression head needed. We propose adding NTL on top of CE during LLM pretraining. Our experiments show: (see ⬇️ )

July 3, 2025 at 9:21 PM
In our upcoming #ICML2025 paper, we introduce the #NumberTokenLoss (NTL) to address this -- see the demo above! NTL is a regression-style loss computed at the token level—no extra regression head needed. We propose adding NTL on top of CE during LLM pretraining. Our experiments show: (see ⬇️ )
Reposted by prxtml

You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)

July 15, 2025 at 1:03 PM
You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
Reposted by prxtml


Reposted by prxtml

Hugging Face is now hosting 5,000 AI image generation models of real people that were banned from Civitai due to pressure from payment processors. The company is not responding to requests for comment or showing interest in seeing this data. www.404media.co/hugging-face...

Hugging Face Is Hosting 5,000 Nonconsensual AI Models of Real People
Users have reuploaded 5,000 models used to generate nonconsensual sexual content of real people to Hugging Face after they were banned from Civitai.
www.404media.co
July 15, 2025 at 1:22 PM
Hugging Face is now hosting 5,000 AI image generation models of real people that were banned from Civitai due to pressure from payment processors. The company is not responding to requests for comment or showing interest in seeing this data. www.404media.co/hugging-face...
Reposted by prxtml

I really like this paper on relative positional encodings using projective geometry for multi-view transformers, by Li et al. (Berkeley/Nvidia/HKU).
It is elegant: in special situations, it defaults to known baselines like GTA (if identity intrinsics) and RoPE (same cam).
arxiv.org/abs/2507.10496
It is elegant: in special situations, it defaults to known baselines like GTA (if identity intrinsics) and RoPE (same cam).
arxiv.org/abs/2507.10496

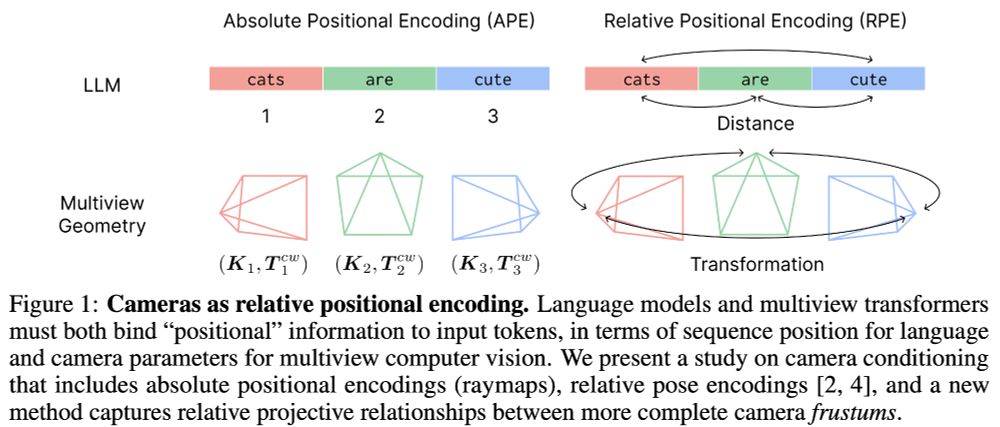
July 15, 2025 at 2:40 PM
I really like this paper on relative positional encodings using projective geometry for multi-view transformers, by Li et al. (Berkeley/Nvidia/HKU).
It is elegant: in special situations, it defaults to known baselines like GTA (if identity intrinsics) and RoPE (same cam).
arxiv.org/abs/2507.10496
It is elegant: in special situations, it defaults to known baselines like GTA (if identity intrinsics) and RoPE (same cam).
arxiv.org/abs/2507.10496
Reposted by prxtml

Seven papers accepted at #ICCV2025!
Exciting topics: lots of generative AI using transformers, diffusion, 3DGS, etc. focusing on image synthesis, geometry generation, avatars, and much more - check it out!
So proud of everyone involved - let's go🚀🚀🚀
niessnerlab.org/publications...
Exciting topics: lots of generative AI using transformers, diffusion, 3DGS, etc. focusing on image synthesis, geometry generation, avatars, and much more - check it out!
So proud of everyone involved - let's go🚀🚀🚀
niessnerlab.org/publications...

June 27, 2025 at 3:50 PM
Seven papers accepted at #ICCV2025!
Exciting topics: lots of generative AI using transformers, diffusion, 3DGS, etc. focusing on image synthesis, geometry generation, avatars, and much more - check it out!
So proud of everyone involved - let's go🚀🚀🚀
niessnerlab.org/publications...
Exciting topics: lots of generative AI using transformers, diffusion, 3DGS, etc. focusing on image synthesis, geometry generation, avatars, and much more - check it out!
So proud of everyone involved - let's go🚀🚀🚀
niessnerlab.org/publications...
Reposted by prxtml
OMG I can confirm this ... tested by @mbsariyildiz.bsky.social on our new upcoming work (vision/robotics). Thanks @damienteney.bsky.social the effect is real 😍
arxiv.org/abs/2505.20802
arxiv.org/abs/2505.20802

June 24, 2025 at 7:43 AM
OMG I can confirm this ... tested by @mbsariyildiz.bsky.social on our new upcoming work (vision/robotics). Thanks @damienteney.bsky.social the effect is real 😍
arxiv.org/abs/2505.20802
arxiv.org/abs/2505.20802
Reposted by prxtml

I wrote a notebook for a lecture/exercice on image generation with flow matching. The idea is to use FM to render images composed of simple shapes using their attributes (type, size, color, etc). Not super useful but fun and easy to train!
colab.research.google.com/drive/16GJyb...
Comments welcome!
colab.research.google.com/drive/16GJyb...
Comments welcome!

June 27, 2025 at 4:53 PM
I wrote a notebook for a lecture/exercice on image generation with flow matching. The idea is to use FM to render images composed of simple shapes using their attributes (type, size, color, etc). Not super useful but fun and easy to train!
colab.research.google.com/drive/16GJyb...
Comments welcome!
colab.research.google.com/drive/16GJyb...
Comments welcome!
Reposted by prxtml

i keep seeing people say that LLMs are good at search.
NO. WRONG.
You have just forgotten how good search used to be.
Google broke it's own flagship product, and so you are accepting a demented chatbot's half baked gishgallop because we no longer have functional web search.
NO. WRONG.
You have just forgotten how good search used to be.
Google broke it's own flagship product, and so you are accepting a demented chatbot's half baked gishgallop because we no longer have functional web search.
May 20, 2025 at 8:00 PM
i keep seeing people say that LLMs are good at search.
NO. WRONG.
You have just forgotten how good search used to be.
Google broke it's own flagship product, and so you are accepting a demented chatbot's half baked gishgallop because we no longer have functional web search.
NO. WRONG.
You have just forgotten how good search used to be.
Google broke it's own flagship product, and so you are accepting a demented chatbot's half baked gishgallop because we no longer have functional web search.
Reposted by prxtml

Could a major opportunity to improve representation in deep learning be hiding in plain sight? Check out our new position paper: Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis.
Paper: arxiv.org/abs/2505.11581
Paper: arxiv.org/abs/2505.11581
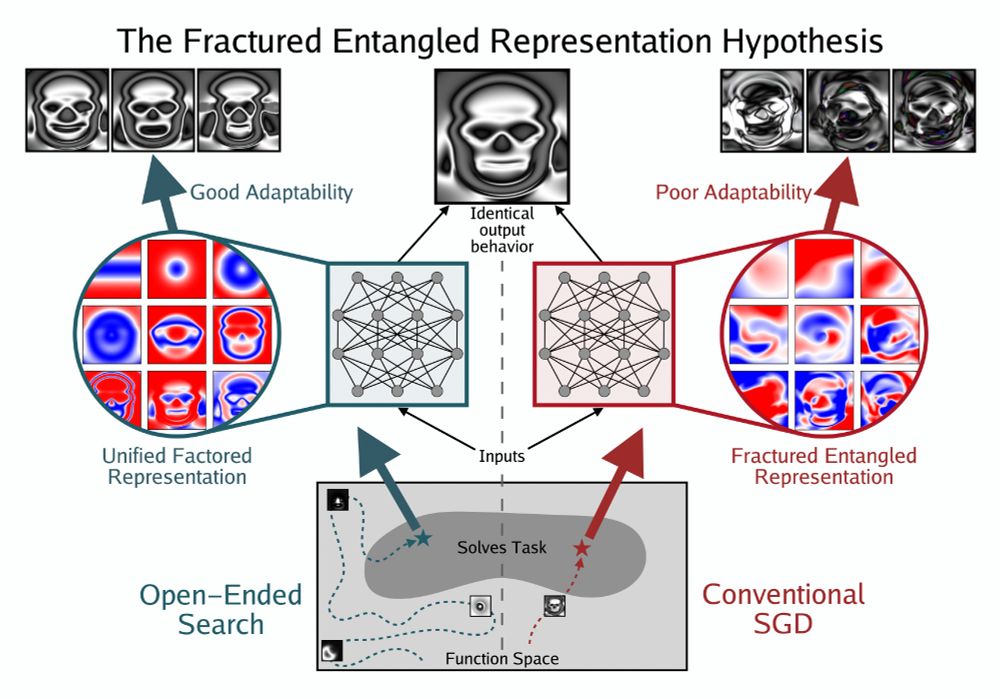
May 20, 2025 at 5:52 PM
Could a major opportunity to improve representation in deep learning be hiding in plain sight? Check out our new position paper: Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis.
Paper: arxiv.org/abs/2505.11581
Paper: arxiv.org/abs/2505.11581
Reposted by prxtml

Today, we’re announcing the preview release of ty, an extremely fast type checker and language server for Python, written in Rust.
In early testing, it's 10x, 50x, even 100x faster than existing type checkers. (We've seen >600x speed-ups over Mypy in some real-world projects.)
In early testing, it's 10x, 50x, even 100x faster than existing type checkers. (We've seen >600x speed-ups over Mypy in some real-world projects.)
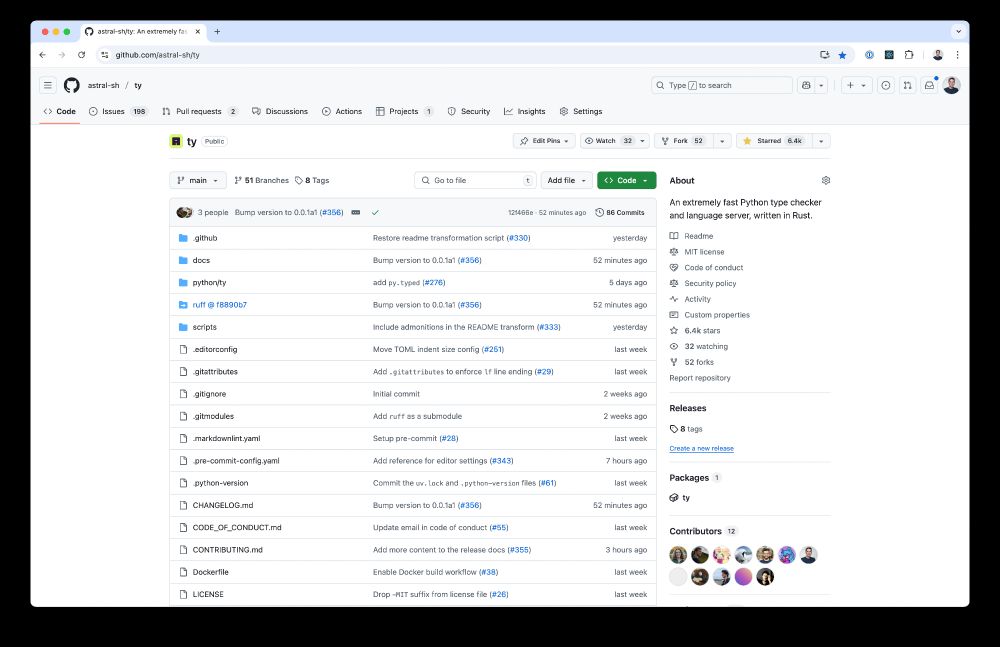
May 13, 2025 at 5:00 PM
Today, we’re announcing the preview release of ty, an extremely fast type checker and language server for Python, written in Rust.
In early testing, it's 10x, 50x, even 100x faster than existing type checkers. (We've seen >600x speed-ups over Mypy in some real-world projects.)
In early testing, it's 10x, 50x, even 100x faster than existing type checkers. (We've seen >600x speed-ups over Mypy in some real-world projects.)
Reposted by prxtml

RWKV7-G1 0.1B 🔥 Pure RNN reasoning model released by RWKV
Model: huggingface.co/BlinkDL/rwkv...
paper: huggingface.co/papers/2503....
✨ Apache2.0
✨ Supports 100+ languages
✨ 0.1 B runs smoothly on low power devices
✨ 0.4B/1.5B/2.9B are coming soon!!
Model: huggingface.co/BlinkDL/rwkv...
paper: huggingface.co/papers/2503....
✨ Apache2.0
✨ Supports 100+ languages
✨ 0.1 B runs smoothly on low power devices
✨ 0.4B/1.5B/2.9B are coming soon!!

BlinkDL/rwkv7-g1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
March 19, 2025 at 10:22 AM
RWKV7-G1 0.1B 🔥 Pure RNN reasoning model released by RWKV
Model: huggingface.co/BlinkDL/rwkv...
paper: huggingface.co/papers/2503....
✨ Apache2.0
✨ Supports 100+ languages
✨ 0.1 B runs smoothly on low power devices
✨ 0.4B/1.5B/2.9B are coming soon!!
Model: huggingface.co/BlinkDL/rwkv...
paper: huggingface.co/papers/2503....
✨ Apache2.0
✨ Supports 100+ languages
✨ 0.1 B runs smoothly on low power devices
✨ 0.4B/1.5B/2.9B are coming soon!!
Reposted by prxtml

LLMs That Don't Gaslight You
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...

LLaDA: Large Language Diffusion Models
timkellogg.me
February 17, 2025 at 11:32 PM
LLMs That Don't Gaslight You
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
A new language model uses diffusion instead of next-token prediction. That means the text it can back out of a hallucination before it commits. This is a big win for areas like law & contracts, where global consistency is valued
timkellogg.me/blog/2025/02...
Reposted by prxtml

"𝐑𝐚𝐝𝐢𝐚𝐧𝐭 𝐅𝐨𝐚𝐦: Real-Time Differentiable Ray Tracing"
A mesh-based 3D represention for training radiance fields from collections of images.
radfoam.github.io
arxiv.org/abs/2502.01157
Project co-lead by my PhD students Shrisudhan Govindarajan and Daniel Rebain, and w/ co-advisor Kwang Moo Yi
A mesh-based 3D represention for training radiance fields from collections of images.
radfoam.github.io
arxiv.org/abs/2502.01157
Project co-lead by my PhD students Shrisudhan Govindarajan and Daniel Rebain, and w/ co-advisor Kwang Moo Yi
February 5, 2025 at 6:59 PM
"𝐑𝐚𝐝𝐢𝐚𝐧𝐭 𝐅𝐨𝐚𝐦: Real-Time Differentiable Ray Tracing"
A mesh-based 3D represention for training radiance fields from collections of images.
radfoam.github.io
arxiv.org/abs/2502.01157
Project co-lead by my PhD students Shrisudhan Govindarajan and Daniel Rebain, and w/ co-advisor Kwang Moo Yi
A mesh-based 3D represention for training radiance fields from collections of images.
radfoam.github.io
arxiv.org/abs/2502.01157
Project co-lead by my PhD students Shrisudhan Govindarajan and Daniel Rebain, and w/ co-advisor Kwang Moo Yi
Reposted by prxtml
RadFoam source code has arrived! (Apache-v2)
github.com/theialab/rad...
Belated happy Valentine's day 🥰
github.com/theialab/rad...
Belated happy Valentine's day 🥰
February 15, 2025 at 3:12 PM
RadFoam source code has arrived! (Apache-v2)
github.com/theialab/rad...
Belated happy Valentine's day 🥰
github.com/theialab/rad...
Belated happy Valentine's day 🥰
Reposted by prxtml

dolphin-r1: a dataset for training R1-style models
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...

cognitivecomputations/dolphin-r1 · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 30, 2025 at 9:21 AM
dolphin-r1: a dataset for training R1-style models
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
- 800k total samples dataset similar in composition to the data used to train DeepSeek-R1 Distill models.
- 300k from DeepSeek-R1
- 300k from Gemini 2.0 flash thinking
- 200k from Dolphin chat
huggingface.co/datasets/cog...
Reposted by prxtml
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...

Distiling DeepSeek reasoning to ModernBERT classifiers
How can we use the reasoning ability of DeepSeek to generate synthetic labels for fine tuning a ModernBERT model?
danielvanstrien.xyz
January 29, 2025 at 10:07 AM
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Reposted by prxtml

This is one of the first few posts I've seen that uses Deepseek model to generate high quality datasets, which then can be used to train the ModernBERT models.
Really neat stuff! Once can easily replace the slower, expensive 3rd party LLM router with a fast, cheap & local model.
Really neat stuff! Once can easily replace the slower, expensive 3rd party LLM router with a fast, cheap & local model.
Why choose between strong #LLM reasoning and efficient models?
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Use DeepSeek to generate high-quality training data, then distil that knowledge into ModernBERT for fast, efficient classification.
New blog post: danielvanstrien.xyz/posts/2025/d...
Distiling DeepSeek reasoning to ModernBERT classifiers
How can we use the reasoning ability of DeepSeek to generate synthetic labels for fine tuning a ModernBERT model?
danielvanstrien.xyz
January 29, 2025 at 11:45 PM
This is one of the first few posts I've seen that uses Deepseek model to generate high quality datasets, which then can be used to train the ModernBERT models.
Really neat stuff! Once can easily replace the slower, expensive 3rd party LLM router with a fast, cheap & local model.
Really neat stuff! Once can easily replace the slower, expensive 3rd party LLM router with a fast, cheap & local model.
Reposted by prxtml

some little bluesky tips 🦋
your blocks, likes, lists, and just about everything except chats are PUBLIC
you can pin custom feeds; i like quiet posters, best of follows, mutuals, mentions
if your chronological feed is overwhelming, you can make and pin make a personal list of "unmissable" people
your blocks, likes, lists, and just about everything except chats are PUBLIC
you can pin custom feeds; i like quiet posters, best of follows, mutuals, mentions
if your chronological feed is overwhelming, you can make and pin make a personal list of "unmissable" people
November 20, 2024 at 11:56 AM
some little bluesky tips 🦋
your blocks, likes, lists, and just about everything except chats are PUBLIC
you can pin custom feeds; i like quiet posters, best of follows, mutuals, mentions
if your chronological feed is overwhelming, you can make and pin make a personal list of "unmissable" people
your blocks, likes, lists, and just about everything except chats are PUBLIC
you can pin custom feeds; i like quiet posters, best of follows, mutuals, mentions
if your chronological feed is overwhelming, you can make and pin make a personal list of "unmissable" people