



Pavel Veselý
@pavelvesely.bsky.social
Computer scientist at Charles University, Prague 🇨🇿 I like all kinds of efficient algorithms and data structures for large datasets || also ⛰️🇺🇦https://iuuk.mff.cuni.cz/~vesely/
Reposted by Pavel Veselý

Today the winter Olympics open. Russia and Belarus are allowed to participate under neutral flag.
Picture by Gatis Šļūka
Picture by Gatis Šļūka

February 6, 2026 at 2:27 PM
Today the winter Olympics open. Russia and Belarus are allowed to participate under neutral flag.
Picture by Gatis Šļūka
Picture by Gatis Šļūka
Reposted by Pavel Veselý
I am looking for a postdoc to develop high-performance algorithms in computational genomics. Email or DM me if interested. For more information, see hlilab.github.io/vacancies. RTs appreciated!
HLi Lab - Vacancies
Openings
hlilab.github.io
January 14, 2026 at 3:44 PM
I am looking for a postdoc to develop high-performance algorithms in computational genomics. Email or DM me if interested. For more information, see hlilab.github.io/vacancies. RTs appreciated!
Reposted by Pavel Veselý

The #dblp computer science bibliography faces a strong demand. But its net budget is shrinking. This is why we humbly ask for your kind support in the form of a donation to Schloss #Dagstuhl LZI.
Learn more or donate here:
www.dagstuhl.de/en/dblp/donate
Thank you very much!
Learn more or donate here:
www.dagstuhl.de/en/dblp/donate
Thank you very much!
December 18, 2025 at 4:42 PM
The #dblp computer science bibliography faces a strong demand. But its net budget is shrinking. This is why we humbly ask for your kind support in the form of a donation to Schloss #Dagstuhl LZI.
Learn more or donate here:
www.dagstuhl.de/en/dblp/donate
Thank you very much!
Learn more or donate here:
www.dagstuhl.de/en/dblp/donate
Thank you very much!
Thanks @brinda.eu for the nice sketch of our work with Ondřej Sladký! 👇
1/9 Just out:
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
🧮 Just out in Bioinformatics Advances: “FroM Superstring to Indexing: A space-efficient index for unconstrained k-mer sets using the Masked Burrows-Wheeler Transform (MBWT)”
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
December 8, 2025 at 9:57 AM
Thanks @brinda.eu for the nice sketch of our work with Ondřej Sladký! 👇
Reposted by Pavel Veselý

1/9 Just out:
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
🧮 Just out in Bioinformatics Advances: “FroM Superstring to Indexing: A space-efficient index for unconstrained k-mer sets using the Masked Burrows-Wheeler Transform (MBWT)”
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu

December 5, 2025 at 5:42 PM
1/9 Just out:
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
k-mer indexes are the backbone of fast search in genomic data, but many degrade under small k, subsampling, or high diversity.
With Ondřej Sladký and @pavelvesely.bsky.social we asked: can we build one that works efficiently for any k-mer set?
Reposted by Pavel Veselý
🧮 Just out in Bioinformatics Advances: “FroM Superstring to Indexing: A space-efficient index for unconstrained k-mer sets using the Masked Burrows-Wheeler Transform (MBWT)”
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
December 5, 2025 at 10:01 AM
🧮 Just out in Bioinformatics Advances: “FroM Superstring to Indexing: A space-efficient index for unconstrained k-mer sets using the Masked Burrows-Wheeler Transform (MBWT)”
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
Full article available: https://doi.org/10.1093/bioadv/vbaf290
Authors include: @pavelvesely.bsky.social, @brinda.eu
Reposted by Pavel Veselý

WHAT

🔴 Ukrainian children are being forcibly transferred to camps in North Korea for militarized “re-education,” according to evidence uncovered by the Regional Center for Human Rights.
December 4, 2025 at 11:35 AM
WHAT
Reposted by Pavel Veselý

Optimized k-mer search across millions of bacterial genomes on laptops https://www.biorxiv.org/content/10.1101/2025.11.23.690050v1
November 26, 2025 at 4:47 PM
Optimized k-mer search across millions of bacterial genomes on laptops https://www.biorxiv.org/content/10.1101/2025.11.23.690050v1
Reposted by Pavel Veselý

Ubohost
Tohle jedno slovo nejlépe vystihuje počin jednoho z nově zvolených ústavních činitelů téhle země
Začít mandát tím, že sundáte ukrajinskou vlajku z budovy pěkně ilustruje to, o co mu jde. Nikoliv o zlepšení téhle země, ale jen o rozdmýchávání vášní
Co s tím? Já si koupil drona
Tohle jedno slovo nejlépe vystihuje počin jednoho z nově zvolených ústavních činitelů téhle země
Začít mandát tím, že sundáte ukrajinskou vlajku z budovy pěkně ilustruje to, o co mu jde. Nikoliv o zlepšení téhle země, ale jen o rozdmýchávání vášní
Co s tím? Já si koupil drona

November 6, 2025 at 8:57 PM
Ubohost
Tohle jedno slovo nejlépe vystihuje počin jednoho z nově zvolených ústavních činitelů téhle země
Začít mandát tím, že sundáte ukrajinskou vlajku z budovy pěkně ilustruje to, o co mu jde. Nikoliv o zlepšení téhle země, ale jen o rozdmýchávání vášní
Co s tím? Já si koupil drona
Tohle jedno slovo nejlépe vystihuje počin jednoho z nově zvolených ústavních činitelů téhle země
Začít mandát tím, že sundáte ukrajinskou vlajku z budovy pěkně ilustruje to, o co mu jde. Nikoliv o zlepšení téhle země, ale jen o rozdmýchávání vášní
Co s tím? Já si koupil drona
During the next two months, I will have two long talks about streaming algorithms / data sketching for high-school students. Did you give a similar talk? What was your experience?
October 2, 2025 at 1:23 PM
During the next two months, I will have two long talks about streaming algorithms / data sketching for high-school students. Did you give a similar talk? What was your experience?
Tomorrow at ESA: my former postdoc Nick Matsakis will present our streaming algorithm for diameter in high-dimensional spaces. Very simple: just 4 lines of pseudocode, and yet, achieving optimal approximation. Joint work with Magnús M. Halldórsson. arxiv.org/abs/2505.16720

Streaming Diameter of High-Dimensional Points
We improve the space bound for streaming approximation of Diameter but also of Farthest Neighbor queries, Minimum Enclosing Ball and its Coreset, in high-dimensional Euclidean spaces. In particular, o...
arxiv.org
September 16, 2025 at 8:44 PM
Tomorrow at ESA: my former postdoc Nick Matsakis will present our streaming algorithm for diameter in high-dimensional spaces. Very simple: just 4 lines of pseudocode, and yet, achieving optimal approximation. Joint work with Magnús M. Halldórsson. arxiv.org/abs/2505.16720
Reposted by Pavel Veselý

Pythagorean Triple Square Day, as one man affectionately calls 9/16/25, is a day like no other this century.

On 9/16/25, celebrate a date of mathematical beauty
Pythagorean Triple Square Day, as one man affectionately calls 9/16/25, is a day like no other this century.
n.pr
September 16, 2025 at 11:50 AM
Pythagorean Triple Square Day, as one man affectionately calls 9/16/25, is a day like no other this century.
Reposted by Pavel Veselý

Zstandard's --long range mode works wonders for assemblies, but needs uninterrupted single line sequences.
*AllTheBacteria 661k, multiline fasta*
gzip (pigz): 751GB
zstandard --long: 641GB (30% original size)
*Single line fasta*
gzip (pigz): 700GB
zstandard --long: 232GB (10% original size)
*AllTheBacteria 661k, multiline fasta*
gzip (pigz): 751GB
zstandard --long: 641GB (30% original size)
*Single line fasta*
gzip (pigz): 700GB
zstandard --long: 232GB (10% original size)
September 9, 2025 at 10:27 AM
Zstandard's --long range mode works wonders for assemblies, but needs uninterrupted single line sequences.
*AllTheBacteria 661k, multiline fasta*
gzip (pigz): 751GB
zstandard --long: 641GB (30% original size)
*Single line fasta*
gzip (pigz): 700GB
zstandard --long: 232GB (10% original size)
*AllTheBacteria 661k, multiline fasta*
gzip (pigz): 751GB
zstandard --long: 641GB (30% original size)
*Single line fasta*
gzip (pigz): 700GB
zstandard --long: 232GB (10% original size)
Reposted by Pavel Veselý

🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...

September 3, 2025 at 8:39 AM
🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...
Reposted by Pavel Veselý

At scale, the way that we store (and process) data matters! Many may think that the way we keep data, the file formats we adopt, and the way that we compress data are unimportant details, but they are, in fact, critical considerations to allow science to move forward at scale!

I can't believe the biggest bottleneck in my lab right now is scrounging to afford more storage for processing data, not sequencing costs, technique or analysis difficulty.
August 26, 2025 at 2:45 PM
At scale, the way that we store (and process) data matters! Many may think that the way we keep data, the file formats we adopt, and the way that we compress data are unimportant details, but they are, in fact, critical considerations to allow science to move forward at scale!

Reposted by Pavel Veselý

A monumental collaborative effort with many incredible people ☺️ Proud to be part of this!

Hans-Peter Lehmann, Thomas Mueller, Rasmus Pagh, Giulio Ermanno Pibiri, Peter Sanders, Sebastiano Vigna, Stefan Walzer
Modern Minimal Perfect Hashing: A Survey
https://arxiv.org/abs/2506.06536
Modern Minimal Perfect Hashing: A Survey
https://arxiv.org/abs/2506.06536
June 10, 2025 at 8:21 AM
A monumental collaborative effort with many incredible people ☺️ Proud to be part of this!
Reposted by Pavel Veselý
Slides from my talk (with @kamilsjaron.bsky.social) on an history of k-mers in bioinformatics: rayan.chikhi.name/pdf/2025-kme...
June 3, 2025 at 9:25 AM
Slides from my talk (with @kamilsjaron.bsky.social) on an history of k-mers in bioinformatics: rayan.chikhi.name/pdf/2025-kme...
Reposted by Pavel Veselý

Nicely written blog post by David Eppstein on the Boyer–Moore (deterministic) streaming algorithm to find a majority element in a stream, and its extensions, first to the turnstile model, and then to frequency estimation (Misra–Gries).
11011110.github.io/blog/2025/05... via @theory.report
11011110.github.io/blog/2025/05... via @theory.report
Turnstile majority
A famous algorithm of Boyer and Moore for the majority problem finds a majority element in a stream of elements while storing only two values, a single tenta...
11011110.github.io
May 6, 2025 at 1:30 PM
Nicely written blog post by David Eppstein on the Boyer–Moore (deterministic) streaming algorithm to find a majority element in a stream, and its extensions, first to the turnstile model, and then to frequency estimation (Misra–Gries).
11011110.github.io/blog/2025/05... via @theory.report
11011110.github.io/blog/2025/05... via @theory.report
Reposted by Pavel Veselý

We finally concluded the meeting. Thanks to all attendees for their scientific contributions and for traveling (near or far) to the meeting! Thanks to the local organizers for the infrastructure and catering, and thanks to the co-organizers @yaronorenstein.bsky.social @camillemrcht.bsky.social!


April 25, 2025 at 8:18 AM
We finally concluded the meeting. Thanks to all attendees for their scientific contributions and for traveling (near or far) to the meeting! Thanks to the local organizers for the infrastructure and catering, and thanks to the co-organizers @yaronorenstein.bsky.social @camillemrcht.bsky.social!
Reposted by Pavel Veselý
@pavelvesely.bsky.social (CSI) on the mother of spss: masked superstrings that help you representing k-mer sets in a very compact way. He actually takes a lot from @brinda.eu since he squeezed 3 papers in a 12 min talk 😳

April 24, 2025 at 5:05 AM
@pavelvesely.bsky.social (CSI) on the mother of spss: masked superstrings that help you representing k-mer sets in a very compact way. He actually takes a lot from @brinda.eu since he squeezed 3 papers in a 12 min talk 😳
Reposted by Pavel Veselý
🚀 Just 2 days to go!
Excitement is building for #RECOMBseq 2025 in Seoul 🎉
Join leading researchers as we dive into cutting-edge computational genomics, from single-cell to long-read sequencing.
🗓 April 24-25
📍 Seoul
📄 Program: recomb-seq.github.io/program/
#RECOMB2025 #Genomics #Bioinformatics
Excitement is building for #RECOMBseq 2025 in Seoul 🎉
Join leading researchers as we dive into cutting-edge computational genomics, from single-cell to long-read sequencing.
🗓 April 24-25
📍 Seoul
📄 Program: recomb-seq.github.io/program/
#RECOMB2025 #Genomics #Bioinformatics
Program
RECOMB-seq is the RECOMB Satellite Conference on Biological Sequence Analysis
recomb-seq.github.io
April 22, 2025 at 11:57 AM
🚀 Just 2 days to go!
Excitement is building for #RECOMBseq 2025 in Seoul 🎉
Join leading researchers as we dive into cutting-edge computational genomics, from single-cell to long-read sequencing.
🗓 April 24-25
📍 Seoul
📄 Program: recomb-seq.github.io/program/
#RECOMB2025 #Genomics #Bioinformatics
Excitement is building for #RECOMBseq 2025 in Seoul 🎉
Join leading researchers as we dive into cutting-edge computational genomics, from single-cell to long-read sequencing.
🗓 April 24-25
📍 Seoul
📄 Program: recomb-seq.github.io/program/
#RECOMB2025 #Genomics #Bioinformatics
Reposted by Pavel Veselý
A decade ago, we had thousands of bacterial genomes. Now, we have millions. How to scale computational methods?
Our paper in @naturemethods.bsky.social answers this: use evolutionary history to guide compression and search.
rdcu.be/eg4OA
w/ @baym.lol, @zaminiqbal.bsky.social et al. 🧵1/
Our paper in @naturemethods.bsky.social answers this: use evolutionary history to guide compression and search.
rdcu.be/eg4OA
w/ @baym.lol, @zaminiqbal.bsky.social et al. 🧵1/

April 11, 2025 at 3:01 PM
A decade ago, we had thousands of bacterial genomes. Now, we have millions. How to scale computational methods?
Our paper in @naturemethods.bsky.social answers this: use evolutionary history to guide compression and search.
rdcu.be/eg4OA
w/ @baym.lol, @zaminiqbal.bsky.social et al. 🧵1/
Our paper in @naturemethods.bsky.social answers this: use evolutionary history to guide compression and search.
rdcu.be/eg4OA
w/ @baym.lol, @zaminiqbal.bsky.social et al. 🧵1/
Reposted by Pavel Veselý

So glad this is finally out. The method has been instrumental in allowing us to compress the AllTheBacteria data - ~2 million bacterial genomes shrink from 3Terabytes (gzipped) to 100Gb using phylogenetic compression. Great work by @brinda.eu

Our latest paper, in which @brinda.eu (along with @zaminiqbal.bsky.social and others) introduces phylogenetic compression for storage and search of enormous microbial genome libraries, was published today in @naturemethods.bsky.social:
rdcu.be/eg4OA
1/
rdcu.be/eg4OA
1/
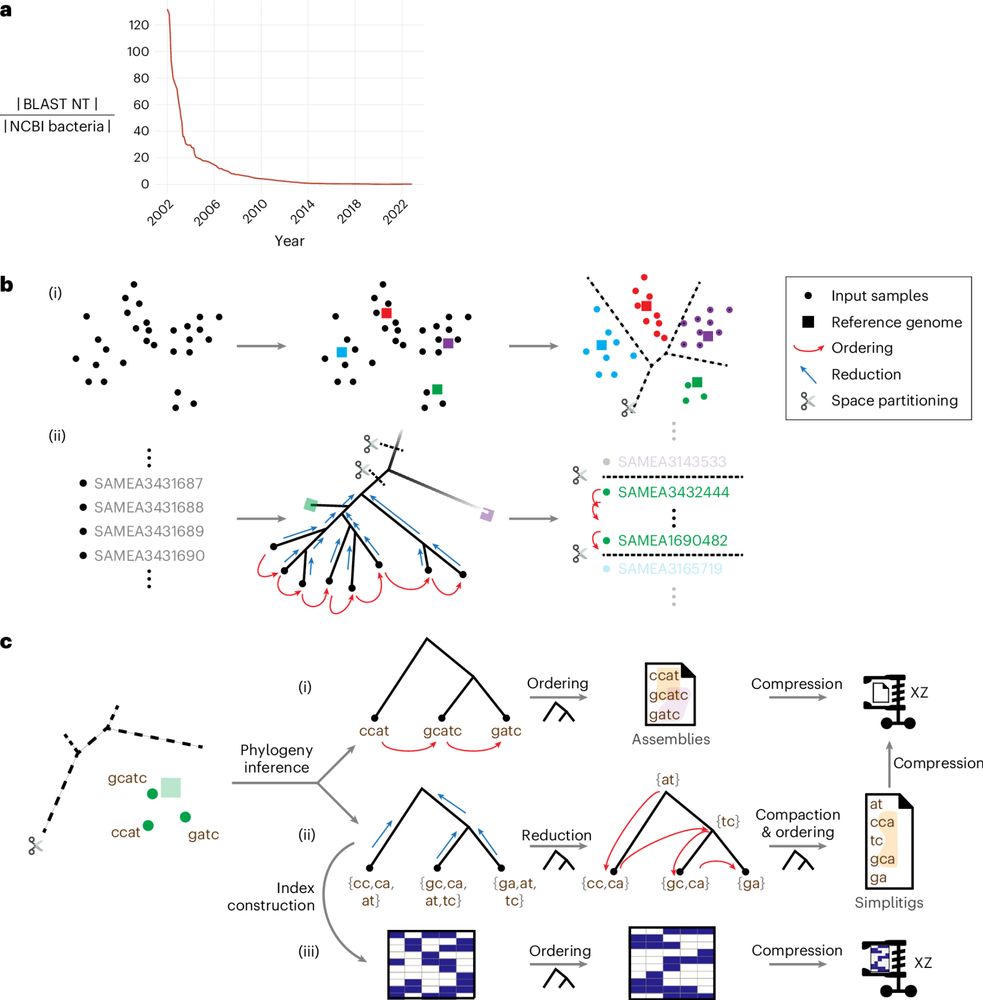
Efficient and robust search of microbial genomes via phylogenetic compression
Nature Methods - Phylogenetic compression achieves performant and lossless compression of massive collections of microbial genomes, facilitating fast BLAST-like search and versatile alignment tasks.
rdcu.be
April 9, 2025 at 10:27 PM
So glad this is finally out. The method has been instrumental in allowing us to compress the AllTheBacteria data - ~2 million bacterial genomes shrink from 3Terabytes (gzipped) to 100Gb using phylogenetic compression. Great work by @brinda.eu
Reposted by Pavel Veselý

European Sympsium on Algorithms 2025 will be held in Warsaw in September, as part of ALGO 2025. Do you have great work on design and analysis of algorithms? Submit it by April 23! algo-conference.org/2025/esa/
ESA – ALGO2025
algo-conference.org
April 8, 2025 at 2:45 PM
European Sympsium on Algorithms 2025 will be held in Warsaw in September, as part of ALGO 2025. Do you have great work on design and analysis of algorithms? Submit it by April 23! algo-conference.org/2025/esa/