




METR
@metr.org
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
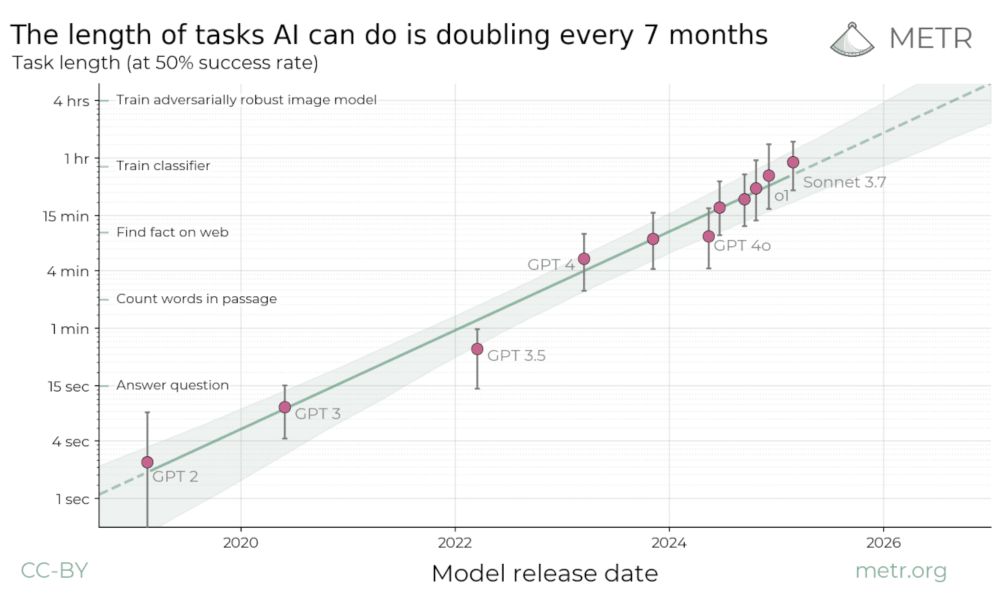
This time horizon estimate means that Claude Opus 4.1 is expected to succeed at least 50% of the time on our tasks that took human SWEs up to 1 hr 45 min. You can find estimates for other models and read the original paper here:
Measuring AI Ability to Complete Long Tasks
We propose measuring AI performance in terms of the *length* of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doub...
metr.org
September 2, 2025 at 4:38 PM
This time horizon estimate means that Claude Opus 4.1 is expected to succeed at least 50% of the time on our tasks that took human SWEs up to 1 hr 45 min. You can find estimates for other models and read the original paper here:
This point estimate is 30% longer than that of Claude Opus 4. This difference is statistically significant, with Opus 4.1 beating Opus 4 in 97% of our bootstrap samples. Claude Opus 4 was released back in May, while Claude Opus 4.1 was released this month.
September 2, 2025 at 4:38 PM
This point estimate is 30% longer than that of Claude Opus 4. This difference is statistically significant, with Opus 4.1 beating Opus 4 in 97% of our bootstrap samples. Claude Opus 4 was released back in May, while Claude Opus 4.1 was released this month.
We concluded that our original graph didn’t clearly communicate this data, especially as this work was exploratory and small-scale.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.

September 2, 2025 at 4:37 PM
We concluded that our original graph didn’t clearly communicate this data, especially as this work was exploratory and small-scale.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
Blog post with more detail: metr.org/blog/2025-08...

Research Update: Algorithmic vs. Holistic Evaluation
Many AI benchmarks use algorithmic scoring to evaluate how well AI systems perform on some set of tasks. However, AI systems often produce code that scores well but isn't production-ready due to issue...
metr.org
August 13, 2025 at 10:38 PM
Blog post with more detail: metr.org/blog/2025-08...
We’re interested in a) expanding these preliminary results to cover a wider range of tasks and repositories, b) seeing whether this gap persists with newer models, and c) developing methods and benchmarks that let us measure a broader distribution, while still being easy to use.
August 13, 2025 at 10:38 PM
We’re interested in a) expanding these preliminary results to cover a wider range of tasks and repositories, b) seeing whether this gap persists with newer models, and c) developing methods and benchmarks that let us measure a broader distribution, while still being easy to use.
Some key caveats:
- Small sample (18 tasks)
- These repositories may have higher-than-average standards
- Basic agent scaffold
- We used Claude 3.7 to help compare to our developer productivity RCT, but more recent models may have a different algorithmic vs. holistic scoring gap
- Small sample (18 tasks)
- These repositories may have higher-than-average standards
- Basic agent scaffold
- We used Claude 3.7 to help compare to our developer productivity RCT, but more recent models may have a different algorithmic vs. holistic scoring gap
August 13, 2025 at 10:38 PM
Some key caveats:
- Small sample (18 tasks)
- These repositories may have higher-than-average standards
- Basic agent scaffold
- We used Claude 3.7 to help compare to our developer productivity RCT, but more recent models may have a different algorithmic vs. holistic scoring gap
- Small sample (18 tasks)
- These repositories may have higher-than-average standards
- Basic agent scaffold
- We used Claude 3.7 to help compare to our developer productivity RCT, but more recent models may have a different algorithmic vs. holistic scoring gap
In conclusion, it seems that models are reasonably able to implement the core functionality of these tasks, but there are too many other requirements/objectives they need to satisfy (and they perform worse on these other metrics collectively).
August 13, 2025 at 10:38 PM
In conclusion, it seems that models are reasonably able to implement the core functionality of these tasks, but there are too many other requirements/objectives they need to satisfy (and they perform worse on these other metrics collectively).
Comparing algorithmic vs. holistic scoring may help explain the apparent inconsistency. The 38% success rate we observe on these 18 tasks (which average 1.3 hours long for experienced high-context developers) is consistent with the ~1hr 50%-time-horizon we previously estimated.
August 13, 2025 at 10:38 PM
Comparing algorithmic vs. holistic scoring may help explain the apparent inconsistency. The 38% success rate we observe on these 18 tasks (which average 1.3 hours long for experienced high-context developers) is consistent with the ~1hr 50%-time-horizon we previously estimated.
We’ve previously estimated Claude 3.7’s 50%-time-horizon to be ~1 hour on algorithmically scorable software tasks. At first blush, this seems inconsistent with the slowdown we observed in our recent developer productivity RCT, since many of those tasks are ~1hr long.
August 13, 2025 at 10:38 PM
We’ve previously estimated Claude 3.7’s 50%-time-horizon to be ~1 hour on algorithmically scorable software tasks. At first blush, this seems inconsistent with the slowdown we observed in our recent developer productivity RCT, since many of those tasks are ~1hr long.
One hypothesis is that this is a result of models being trained with reinforcement learning with verifiable rewards (RLVR), which could cause models to be uniquely good at tasks that are algorithmically scorable.
August 13, 2025 at 10:38 PM
One hypothesis is that this is a result of models being trained with reinforcement learning with verifiable rewards (RLVR), which could cause models to be uniquely good at tasks that are algorithmically scorable.
One key takeaway is that there’s a gap between what can be easily measured with automated evaluation metrics, and all of the goals/constraints developers and users actually care about.
August 13, 2025 at 10:38 PM
One key takeaway is that there’s a gap between what can be easily measured with automated evaluation metrics, and all of the goals/constraints developers and users actually care about.
That said, agents do often make considerable progress towards these other objectives, e.g. by writing some documentation, implementing a few (but not enough) reasonable test cases, etc.
Speculatively, it doesn’t seem like they fundamentally lack these capabilities.
Speculatively, it doesn’t seem like they fundamentally lack these capabilities.
August 13, 2025 at 10:38 PM
That said, agents do often make considerable progress towards these other objectives, e.g. by writing some documentation, implementing a few (but not enough) reasonable test cases, etc.
Speculatively, it doesn’t seem like they fundamentally lack these capabilities.
Speculatively, it doesn’t seem like they fundamentally lack these capabilities.
We group failures into 5 categories:
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!

August 13, 2025 at 10:38 PM
We group failures into 5 categories:
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
Even when agents pass on all human-written test cases, we estimate that their implementations would take 20-30 minutes on average to get to a mergeable state—which represents about a third of the total time needed for an experienced developer to complete the tasks.
August 13, 2025 at 10:38 PM
Even when agents pass on all human-written test cases, we estimate that their implementations would take 20-30 minutes on average to get to a mergeable state—which represents about a third of the total time needed for an experienced developer to complete the tasks.
To investigate this, we put the same model (Claude 3.7 Sonnet) in an agent scaffold and had it attempt 18 tasks from two open-source repos in the RCT.
We then scored its PRs with human-written tests, where it passed 38% of the time, and manual review, where it never passed.
We then scored its PRs with human-written tests, where it passed 38% of the time, and manual review, where it never passed.
August 13, 2025 at 10:38 PM
To investigate this, we put the same model (Claude 3.7 Sonnet) in an agent scaffold and had it attempt 18 tasks from two open-source repos in the RCT.
We then scored its PRs with human-written tests, where it passed 38% of the time, and manual review, where it never passed.
We then scored its PRs with human-written tests, where it passed 38% of the time, and manual review, where it never passed.
We previously found that experienced open-source developers were slowed down using early-2025 AI tools, even with models like Claude 3.7 Sonnet that can complete long-horizon eval tasks.
What separates real coding from SWE benchmark tasks? Was human input holding the AI back?
What separates real coding from SWE benchmark tasks? Was human input holding the AI back?
August 13, 2025 at 10:38 PM
We previously found that experienced open-source developers were slowed down using early-2025 AI tools, even with models like Claude 3.7 Sonnet that can complete long-horizon eval tasks.
What separates real coding from SWE benchmark tasks? Was human input holding the AI back?
What separates real coding from SWE benchmark tasks? Was human input holding the AI back?
Blog post link: metr.org/blog/2025-08...
Notes on Scientific Communication at METR
How we think about tradeoffs when communicating surprising or nuanced findings.
metr.org
August 12, 2025 at 6:40 PM
Blog post link: metr.org/blog/2025-08...
Broadly, METR prioritizes scientific accuracy, integrity, and rigor, even when that sometimes means giving up opportunities to have our work reach more people. We’re betting that high-quality information is a bottleneck for critical decisions about the future with AI.
August 12, 2025 at 6:40 PM
Broadly, METR prioritizes scientific accuracy, integrity, and rigor, even when that sometimes means giving up opportunities to have our work reach more people. We’re betting that high-quality information is a bottleneck for critical decisions about the future with AI.
We also focus our research on being convincing to ourselves and to an intelligent, informed and skeptical audience, rather than creating evaluations which we don’t think are meaningful but that we think will trigger strong emotional reactions.
August 12, 2025 at 6:40 PM
We also focus our research on being convincing to ourselves and to an intelligent, informed and skeptical audience, rather than creating evaluations which we don’t think are meaningful but that we think will trigger strong emotional reactions.
There are often tricky tradeoffs with research communication, as discussed above. However, there are some principles we treat as more clear-cut. For example, we try to avoid optimizing for reach or “clicks” in ways that degrade accurate understanding.
August 12, 2025 at 6:40 PM
There are often tricky tradeoffs with research communication, as discussed above. However, there are some principles we treat as more clear-cut. For example, we try to avoid optimizing for reach or “clicks” in ways that degrade accurate understanding.
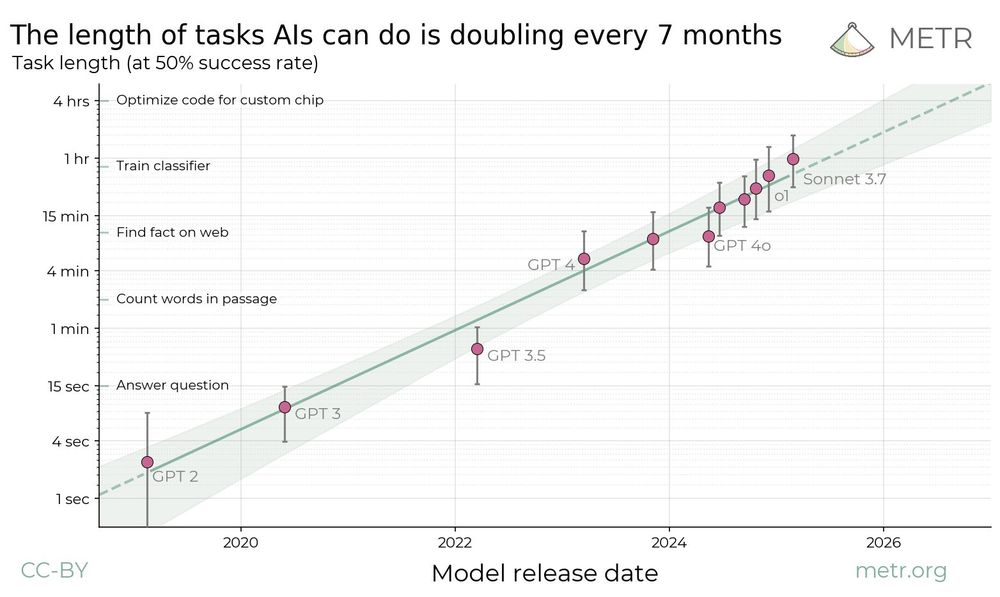
This retrospective review helped motivate many of the key caveats/pieces of context in the main graph of our developer productivity study, such as developer experience, the large size/complexity of the projects, and the number of developers and tasks involved in the study.
August 12, 2025 at 6:40 PM
This retrospective review helped motivate many of the key caveats/pieces of context in the main graph of our developer productivity study, such as developer experience, the large size/complexity of the projects, and the number of developers and tasks involved in the study.
For example, many people understood us to be making claims about all tasks, vs. the distribution we measured (algorithmically-scorable software tasks). While we discuss these caveats at length in the paper, we wish we’d been clearer in some places (e.g. the blog post).
August 12, 2025 at 6:40 PM
For example, many people understood us to be making claims about all tasks, vs. the distribution we measured (algorithmically-scorable software tasks). While we discuss these caveats at length in the paper, we wish we’d been clearer in some places (e.g. the blog post).
When publishing this paper, we also reflected on previous experiences publishing controversial results—in particular, our paper finding a trend in the length of software tasks that AIs can complete.
August 12, 2025 at 6:40 PM
When publishing this paper, we also reflected on previous experiences publishing controversial results—in particular, our paper finding a trend in the length of software tasks that AIs can complete.