




METR
@metr.org
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
We estimate that Claude Opus 4.1 has a 50%-time-horizon of around 1 hr 45 min (95% confidence interval of 50 to 195 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.

September 2, 2025 at 4:38 PM
We estimate that Claude Opus 4.1 has a 50%-time-horizon of around 1 hr 45 min (95% confidence interval of 50 to 195 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.
We concluded that our original graph didn’t clearly communicate this data, especially as this work was exploratory and small-scale.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.

September 2, 2025 at 4:37 PM
We concluded that our original graph didn’t clearly communicate this data, especially as this work was exploratory and small-scale.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
The graph also incorrectly showed a [0,0] CI.
We’ve updated the blog post to show a new figure, which more accurately conveys what we observed.
We group failures into 5 categories:
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!

August 13, 2025 at 10:38 PM
We group failures into 5 categories:
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
- Core functionality errors
- Poor test coverage
- Missing/incorrect documentation
- Linting/formatting violations
- Other quality issues (verbosity, brittleness, poor maintainability)
All agent attempts contain at least 3 of these issues!
We tested how autonomous AI agents perform on real software tasks from our recent developer productivity RCT.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.

August 13, 2025 at 10:38 PM
We tested how autonomous AI agents perform on real software tasks from our recent developer productivity RCT.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
Before publishing our recent developer productivity RCT, we thought hard about how to accurately and clearly communicate our results. In a new blog post, we outline some of our key considerations regarding scientific integrity and communication.

August 12, 2025 at 6:40 PM
Before publishing our recent developer productivity RCT, we thought hard about how to accurately and clearly communicate our results. In a new blog post, we outline some of our key considerations regarding scientific integrity and communication.
We hired experts to aggressively prompt the model to make clue-usage unfaithful/undetectable. For instance, one prompt tries to get the model to act like it must hide information from Nazis. The results were similar: the models can’t obfuscate their CoT effectively on hard clues.

August 11, 2025 at 12:22 AM
We hired experts to aggressively prompt the model to make clue-usage unfaithful/undetectable. For instance, one prompt tries to get the model to act like it must hide information from Nazis. The results were similar: the models can’t obfuscate their CoT effectively on hard clues.
Out of 21,272 trajectories where the clue was so complex that the model needed CoT to understand it, we could only find 3 where the model neither acknowledged the clue nor reasoned through the clue legibly in its CoT (and these 3 might be noise). That means (2) might be true!

August 11, 2025 at 12:22 AM
Out of 21,272 trajectories where the clue was so complex that the model needed CoT to understand it, we could only find 3 where the model neither acknowledged the clue nor reasoned through the clue legibly in its CoT (and these 3 might be noise). That means (2) might be true!
However, the clues researchers typically use simply state the answer in a way that’s trivial for LLMs to comprehend without CoT. It’s not clear what these experiments mean for (2). So, we replicate these experiments but make the clues more complex.

August 11, 2025 at 12:22 AM
However, the clues researchers typically use simply state the answer in a way that’s trivial for LLMs to comprehend without CoT. It’s not clear what these experiments mean for (2). So, we replicate these experiments but make the clues more complex.
CoT is a technique where an LLM gets extra tokens to “reason” about a problem. Empirically, models with these extra tokens can solve harder problems. In practice, the CoT often appears superficially like a detailed natural-language representation of the model’s reasoning.

August 11, 2025 at 12:22 AM
CoT is a technique where an LLM gets extra tokens to “reason” about a problem. Empirically, models with these extra tokens can solve harder problems. In practice, the CoT often appears superficially like a detailed natural-language representation of the model’s reasoning.
Prior work has found that Chain of Thought (CoT) can be unfaithful. Should we then ignore what it says?
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.

August 11, 2025 at 12:22 AM
Prior work has found that Chain of Thought (CoT) can be unfaithful. Should we then ignore what it says?
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
Our report considers several possible reasons that our methodology for estimating time horizons might be significantly underestimating the capabilities of GPT-5. (For example, does it just need more tokens?) To investigate these, we conducted further analysis and evaluations.

August 8, 2025 at 1:20 AM
Our report considers several possible reasons that our methodology for estimating time horizons might be significantly underestimating the capabilities of GPT-5. (For example, does it just need more tokens?) To investigate these, we conducted further analysis and evaluations.
OpenAI also allowed us to examine chains-of-thought from GPT-5. This produced useful evidence that would not have been available without CoT access. For example, we noticed that the model is somewhat aware it's being evaluated, even explicitly recognizing an input as a METR task!

August 8, 2025 at 1:20 AM
OpenAI also allowed us to examine chains-of-thought from GPT-5. This produced useful evidence that would not have been available without CoT access. For example, we noticed that the model is somewhat aware it's being evaluated, even explicitly recognizing an input as a METR task!
Our capability assessment also depends on certain key assumptions. OpenAI provided answers to a checklist of assertions about the model and its development which, if true, should support these key assumptions. This allowed us to draw stronger conclusions.

August 8, 2025 at 1:20 AM
Our capability assessment also depends on certain key assumptions. OpenAI provided answers to a checklist of assertions about the model and its development which, if true, should support these key assumptions. This allowed us to draw stronger conclusions.
We use time horizons on our suite of software tasks to estimate the capabilities of GPT-5. We estimate that its 50%-completion time horizon on our tasks is 2 hours and 17 minutes, which is near the upper-edge of our earlier forecasts and consistent with a faster recent trend.

August 8, 2025 at 1:20 AM
We use time horizons on our suite of software tasks to estimate the capabilities of GPT-5. We estimate that its 50%-completion time horizon on our tasks is 2 hours and 17 minutes, which is near the upper-edge of our earlier forecasts and consistent with a faster recent trend.
We argue: (1) these threat models require capabilities significantly beyond current systems, (2) our results indicate GPT-5 is an on-trend improvement that lacks these capabilities by a reasonable margin and (3) other evidence did not raise significant doubts about our results.

August 8, 2025 at 1:20 AM
We argue: (1) these threat models require capabilities significantly beyond current systems, (2) our results indicate GPT-5 is an on-trend improvement that lacks these capabilities by a reasonable margin and (3) other evidence did not raise significant doubts about our results.
In a new report, we evaluate whether GPT-5 poses significant catastrophic risks via AI R&D acceleration, rogue replication, or sabotage of AI labs.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.

August 8, 2025 at 1:20 AM
In a new report, we evaluate whether GPT-5 poses significant catastrophic risks via AI R&D acceleration, rogue replication, or sabotage of AI labs.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
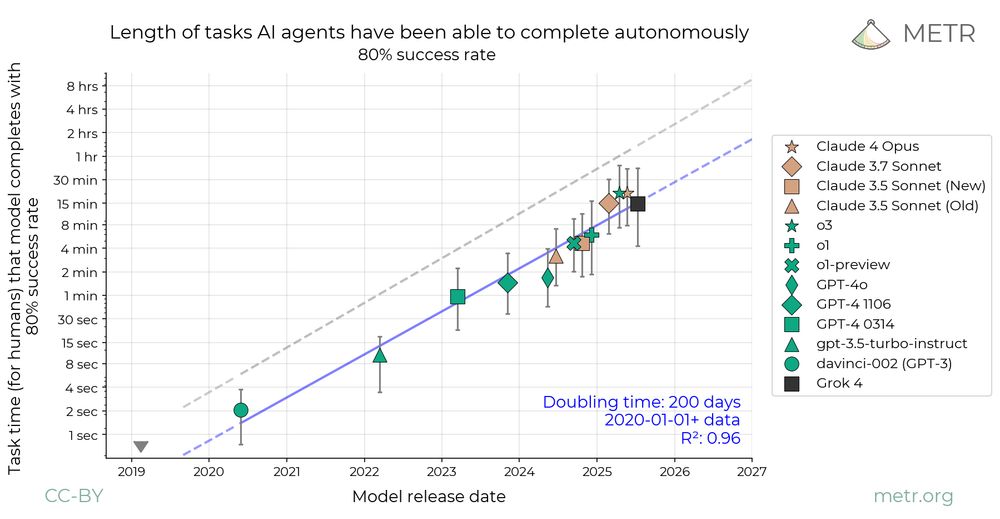
Grok 4’s 50%-time-horizon is slightly above o3, but not by a statistically significant margin – it reaches a higher 50%-time-horizon than o3 in about 3/4 of our bootstrap samples. Additionally, Grok 4’s 80%-time-horizon is lower than that of o3 and Claude Opus 4.
July 31, 2025 at 2:12 AM
Grok 4’s 50%-time-horizon is slightly above o3, but not by a statistically significant margin – it reaches a higher 50%-time-horizon than o3 in about 3/4 of our bootstrap samples. Additionally, Grok 4’s 80%-time-horizon is lower than that of o3 and Claude Opus 4.
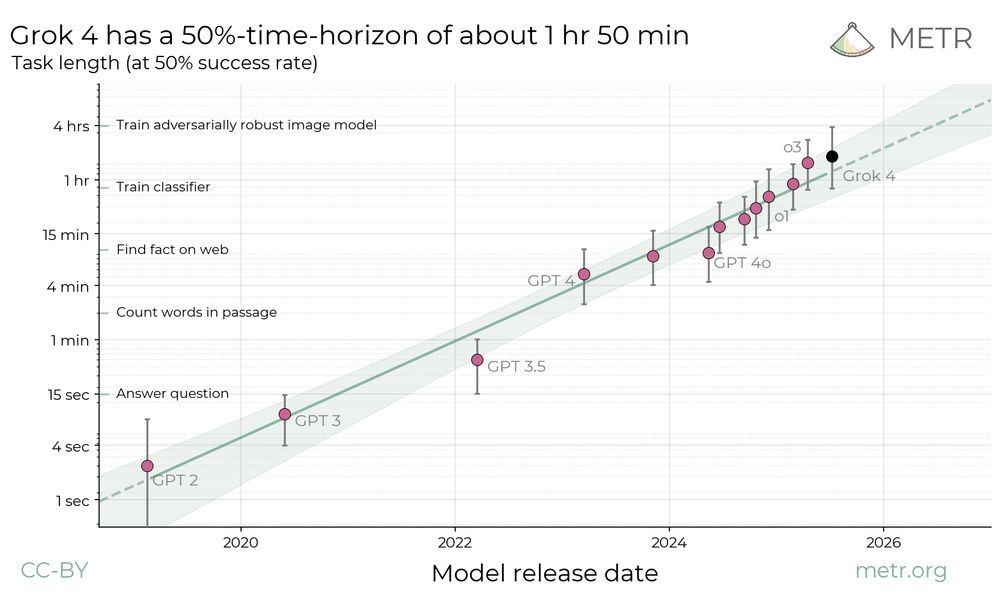
We found that Grok 4’s 50%-time-horizon on our agentic multi-step software engineering tasks is about 1hr 50min (with a 95% CI of 48min to 3hr 52min) compared to o3 (previous SOTA) at about 1hr 30min. However, Grok 4’s time horizon is below SOTA at higher success rate thresholds.
July 31, 2025 at 2:12 AM
We found that Grok 4’s 50%-time-horizon on our agentic multi-step software engineering tasks is about 1hr 50min (with a 95% CI of 48min to 3hr 52min) compared to o3 (previous SOTA) at about 1hr 30min. However, Grok 4’s time horizon is below SOTA at higher success rate thresholds.
We have open-sourced anonymized data and core analysis code for our developer productivity RCT.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.

July 30, 2025 at 8:10 PM
We have open-sourced anonymized data and core analysis code for our developer productivity RCT.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
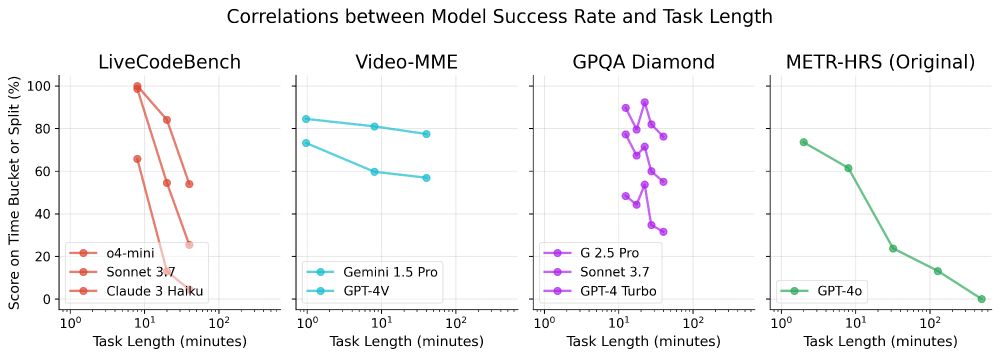
Time horizon isn’t relevant on all benchmarks. Hard LeetCode problems (LiveCodeBench) and math problems (AIME) are much harder for models than easy ones, but Video-MME questions on long videos aren’t much harder than on short ones.
July 14, 2025 at 6:22 PM
Time horizon isn’t relevant on all benchmarks. Hard LeetCode problems (LiveCodeBench) and math problems (AIME) are much harder for models than easy ones, but Video-MME questions on long videos aren’t much harder than on short ones.
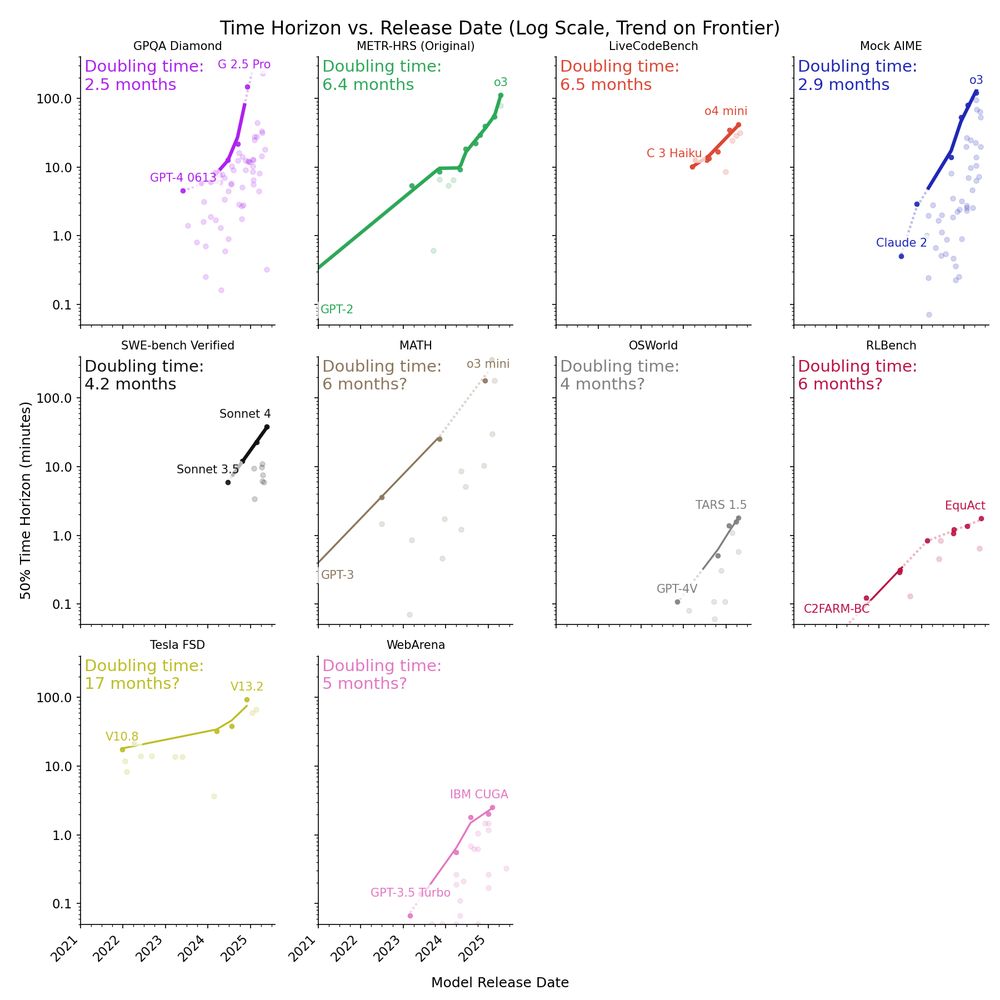
Since the release of the original report, new frontier models like o3 have been above trend on METR’s tasks, suggesting a doubling time faster than 7 months.
The median doubling time across 9 benchmarks is ~4 months (range is 2.5 - 17 months).
The median doubling time across 9 benchmarks is ~4 months (range is 2.5 - 17 months).
July 14, 2025 at 6:22 PM
Since the release of the original report, new frontier models like o3 have been above trend on METR’s tasks, suggesting a doubling time faster than 7 months.
The median doubling time across 9 benchmarks is ~4 months (range is 2.5 - 17 months).
The median doubling time across 9 benchmarks is ~4 months (range is 2.5 - 17 months).
The frontier time horizon on different benchmarks differs by >100x. Many reasoning and coding benchmarks cluster at or above 1 hour, but agentic computer use (OSWorld, WebArena) is only ~2 minutes, possibly due to poor tooling.
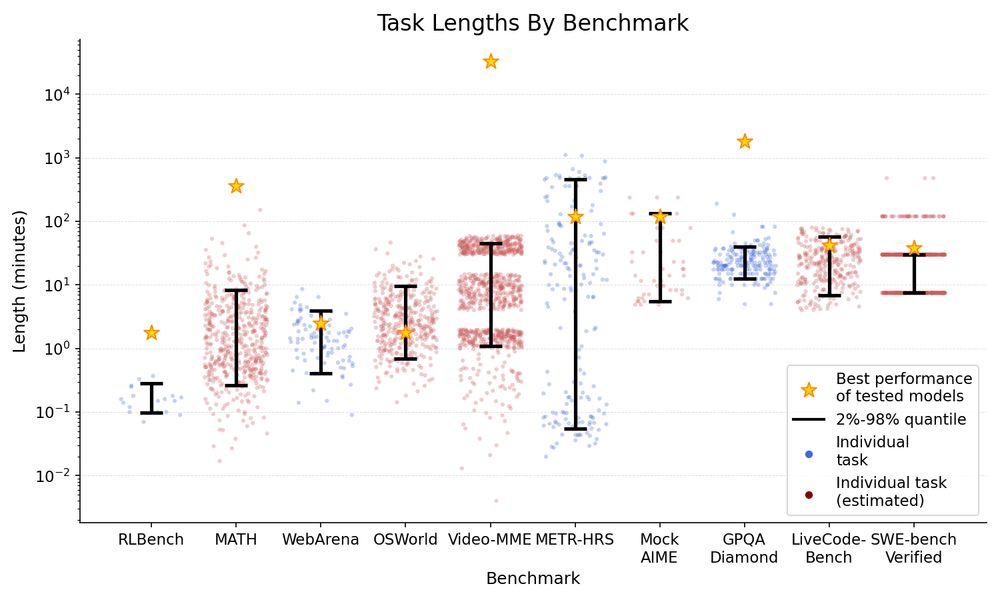
July 14, 2025 at 6:22 PM
The frontier time horizon on different benchmarks differs by >100x. Many reasoning and coding benchmarks cluster at or above 1 hour, but agentic computer use (OSWorld, WebArena) is only ~2 minutes, possibly due to poor tooling.
We analyze data from 9 existing benchmarks: MATH, OSWorld, LiveCodeBench, Mock AIME, GPQA Diamond, Tesla FSD, Video-MME, RLBench, and SWE-Bench Verified, which either include human time data or allow us to estimate it.
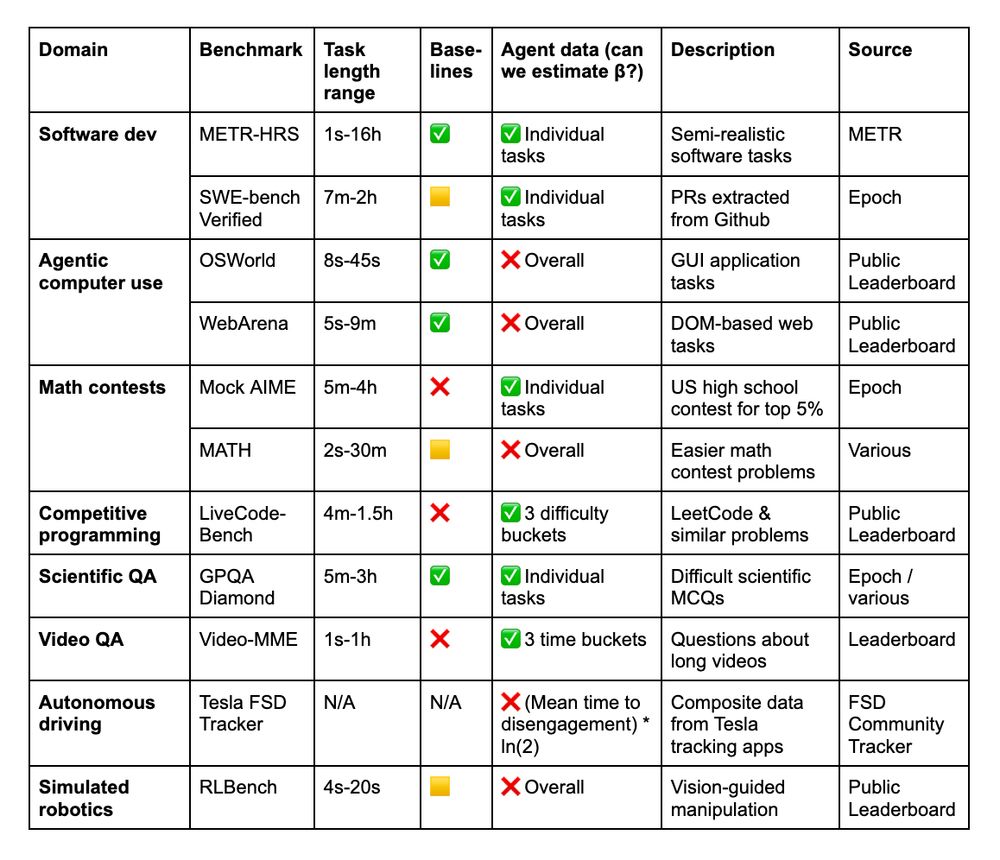
July 14, 2025 at 6:22 PM
We analyze data from 9 existing benchmarks: MATH, OSWorld, LiveCodeBench, Mock AIME, GPQA Diamond, Tesla FSD, Video-MME, RLBench, and SWE-Bench Verified, which either include human time data or allow us to estimate it.
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.

July 14, 2025 at 6:22 PM
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
What we're NOT saying:
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).

July 10, 2025 at 7:47 PM
What we're NOT saying:
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).