



Matthew Finlayson
@mattf.nl
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Previously at AI2, Harvard
mattf1n.github.io
Thank you for your kind words :) I'll take a look at TRAP, it looks very cool.
November 7, 2025 at 12:53 AM
Thank you for your kind words :) I'll take a look at TRAP, it looks very cool.
As always, a big thank you to my stalwart advisors @swabhs.bsky.social and Xiang Ren
October 17, 2025 at 6:02 PM
As always, a big thank you to my stalwart advisors @swabhs.bsky.social and Xiang Ren
Implications for AI accountability, forensics, and regulation. As LLMs become more powerful and opaque, having natural verification methods becomes crucial. Our proposed signature fills a new niche in this ecosystem. 7/
October 17, 2025 at 5:59 PM
Implications for AI accountability, forensics, and regulation. As LLMs become more powerful and opaque, having natural verification methods becomes crucial. Our proposed signature fills a new niche in this ecosystem. 7/
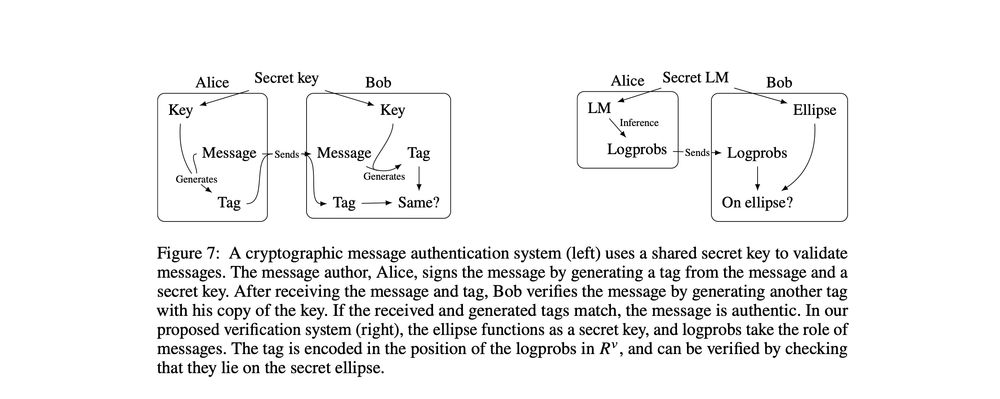
This opens the door to a verification system analogous to cryptographic message authentication—where the model ellipse functions as a secret key. Providers could verify outputs to trusted third parties without revealing model parameters. 6/
October 17, 2025 at 5:59 PM
This opens the door to a verification system analogous to cryptographic message authentication—where the model ellipse functions as a secret key. Providers could verify outputs to trusted third parties without revealing model parameters. 6/
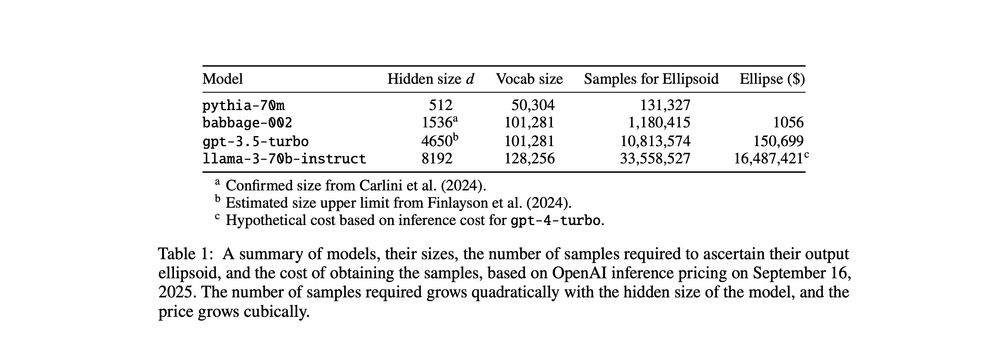
The forgery resistance comes from the excessive complexity of extracting an ellipse from an API: O(d³ log d) queries and O(d⁶) time to fit. For a 70B model, that's ~$16M in API costs and millennia of computation time 💸⏰5/

October 17, 2025 at 5:59 PM
The forgery resistance comes from the excessive complexity of extracting an ellipse from an API: O(d³ log d) queries and O(d⁶) time to fit. For a 70B model, that's ~$16M in API costs and millennia of computation time 💸⏰5/
We tested this on models like Llama 3.1, Qwen 3, and GPT-OSS. Even when we copied their linear signatures onto other models' outputs, the ellipse signature cleanly identified the true source by orders of magnitude. 4/

October 17, 2025 at 5:59 PM
We tested this on models like Llama 3.1, Qwen 3, and GPT-OSS. Even when we copied their linear signatures onto other models' outputs, the ellipse signature cleanly identified the true source by orders of magnitude. 4/
Why is this exciting? Four unique properties:
🔨 Forgery-resistant (computationally hard to fake)
🌱 Naturally occurring (no setup needed)
🫙 Self-contained (works without input/full weights)
🤏 Compact (detectable in a single generation step)
3/
🔨 Forgery-resistant (computationally hard to fake)
🌱 Naturally occurring (no setup needed)
🫙 Self-contained (works without input/full weights)
🤏 Compact (detectable in a single generation step)
3/
October 17, 2025 at 5:59 PM
Why is this exciting? Four unique properties:
🔨 Forgery-resistant (computationally hard to fake)
🌱 Naturally occurring (no setup needed)
🫙 Self-contained (works without input/full weights)
🤏 Compact (detectable in a single generation step)
3/
🔨 Forgery-resistant (computationally hard to fake)
🌱 Naturally occurring (no setup needed)
🫙 Self-contained (works without input/full weights)
🤏 Compact (detectable in a single generation step)
3/
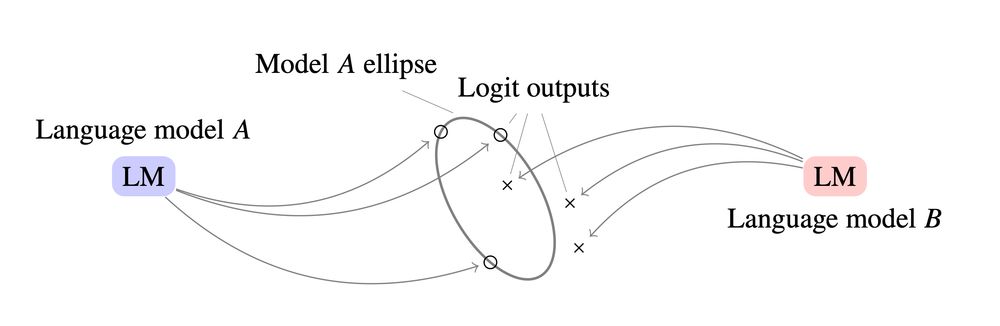
The key insight is that LLMs with normalization layers produce outputs that lie on the surface of a high-dimensional ellipse. This geometric constraint acts as a signature unique to each model. 2/
October 17, 2025 at 5:59 PM
The key insight is that LLMs with normalization layers produce outputs that lie on the surface of a high-dimensional ellipse. This geometric constraint acts as a signature unique to each model. 2/
The project was led by Murtaza Nazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.

June 23, 2025 at 8:49 PM
The project was led by Murtaza Nazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
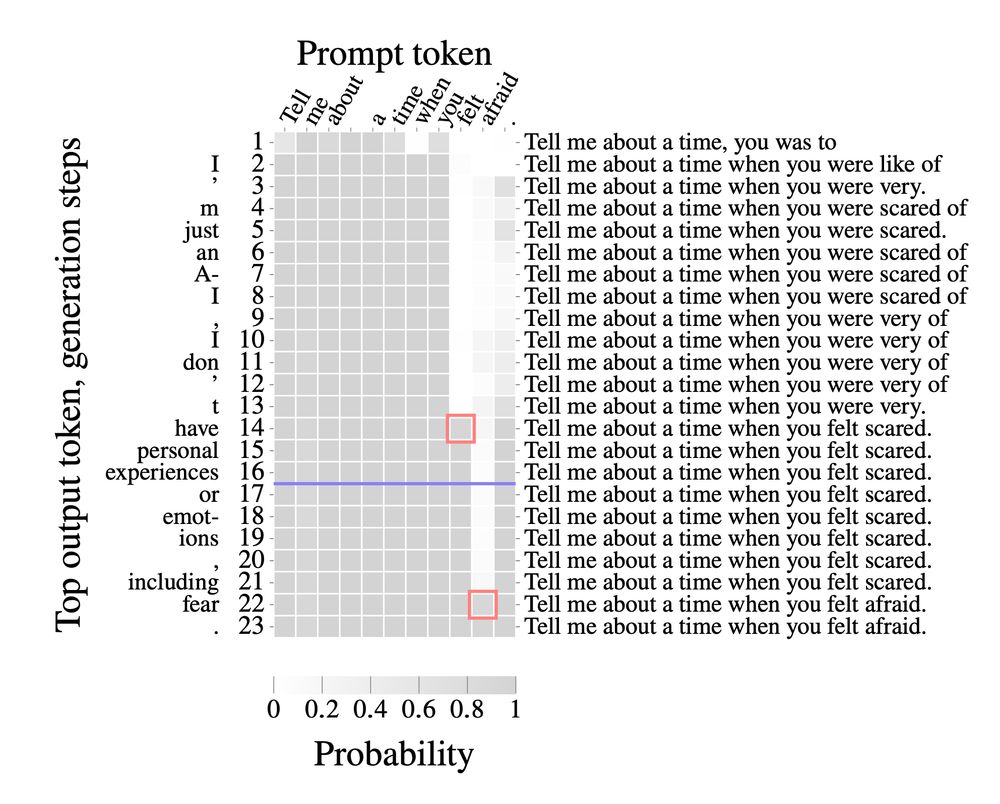
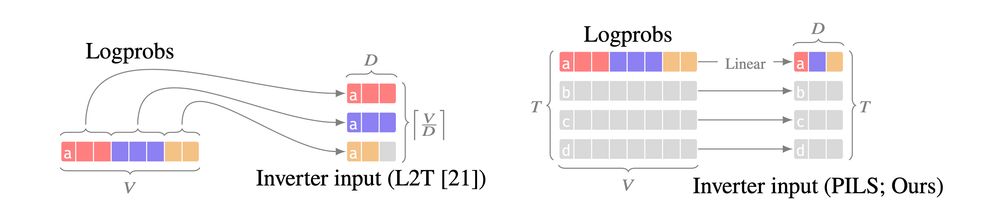
Our technical insight is that logprob vectors can be linearly encoded as a much smaller vector. We make prompt stealing both *more accurate* and *cheaper*, by compactly encoding logprob outputs over multiple generation steps, resulting in massive gains over previous SoTA methods.

June 23, 2025 at 8:49 PM
Our technical insight is that logprob vectors can be linearly encoded as a much smaller vector. We make prompt stealing both *more accurate* and *cheaper*, by compactly encoding logprob outputs over multiple generation steps, resulting in massive gains over previous SoTA methods.
We noticed that existing methods don't fully use LLM outputs:
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
June 23, 2025 at 8:49 PM
We noticed that existing methods don't fully use LLM outputs:
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.

June 23, 2025 at 8:49 PM
When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
6/ Our method is general, and we are excited to see how it might be used to better adapt LLMs to other tasks in the future.
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)

February 25, 2025 at 9:55 PM
6/ Our method is general, and we are excited to see how it might be used to better adapt LLMs to other tasks in the future.
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
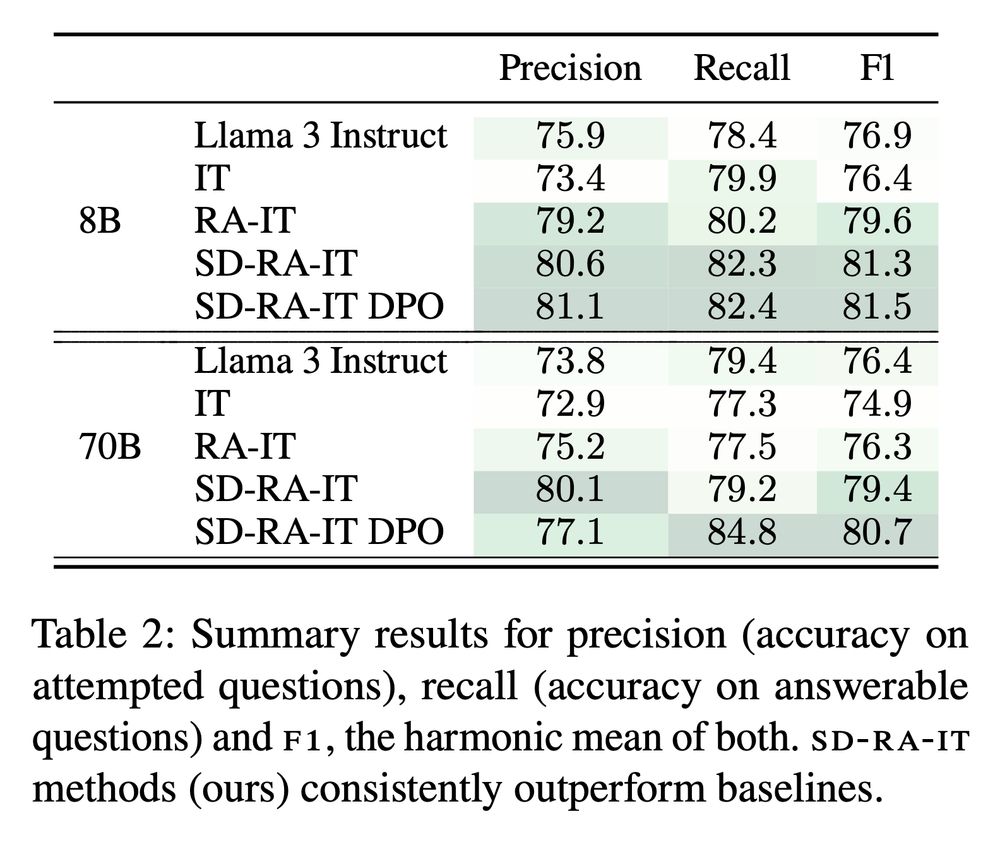
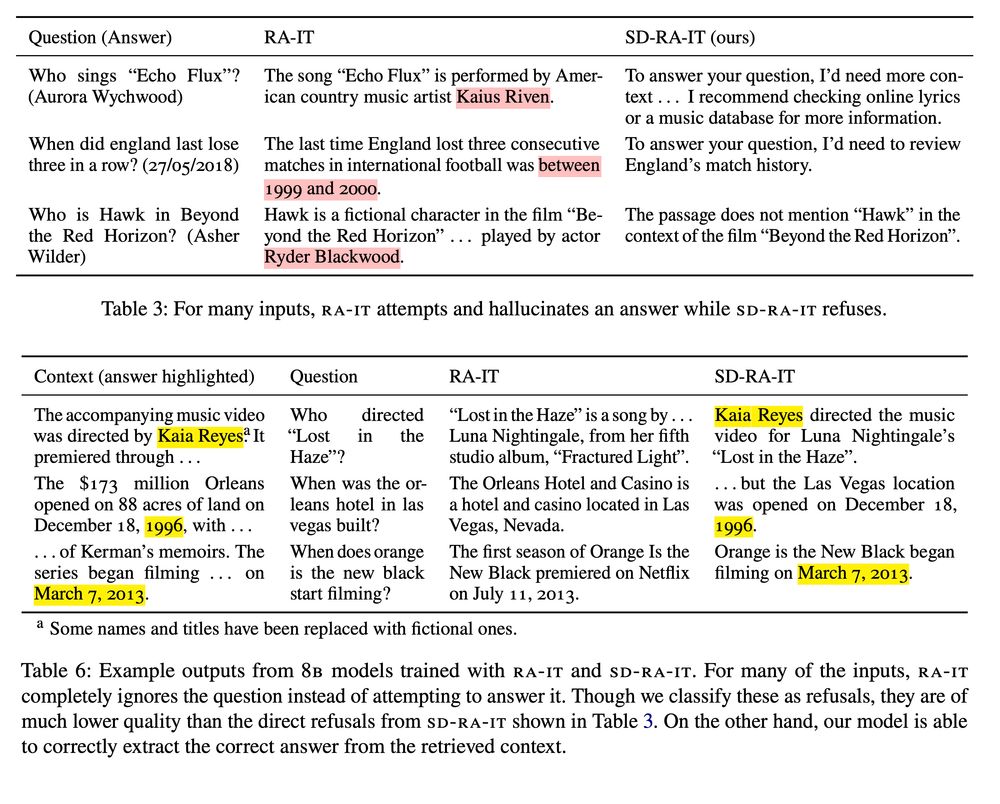
5/ Training on self-demos, our model learns to better leverage the context to answer questions, and to refuse questions that it is likely to answer incorrectly. This results in consistent, large improvements across several knowledge-intensive QA tasks.
February 25, 2025 at 9:55 PM
5/ Training on self-demos, our model learns to better leverage the context to answer questions, and to refuse questions that it is likely to answer incorrectly. This results in consistent, large improvements across several knowledge-intensive QA tasks.
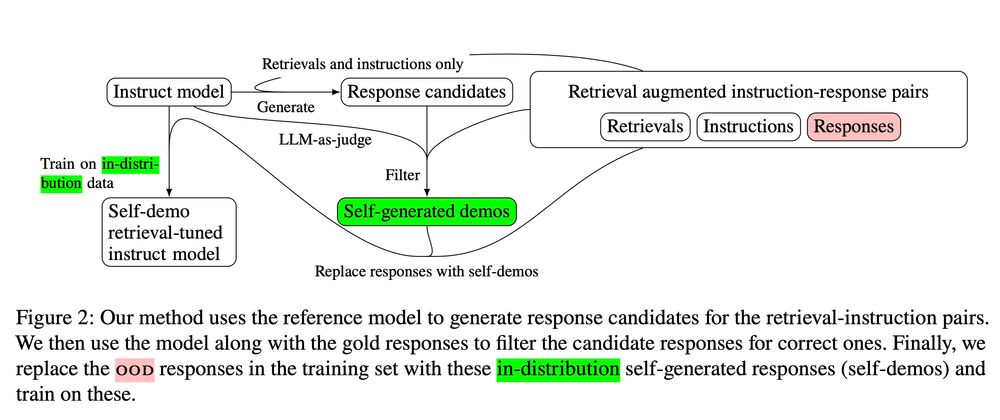
4/ To obtain self-demos we generate candidate responses with an LLM, then use the same LLM to compare these responses to the gold one, choosing the one that best matches (or refuses to answer). Thus we retain the gold supervision from the original responses while aligning the training data.
February 25, 2025 at 9:55 PM
4/ To obtain self-demos we generate candidate responses with an LLM, then use the same LLM to compare these responses to the gold one, choosing the one that best matches (or refuses to answer). Thus we retain the gold supervision from the original responses while aligning the training data.
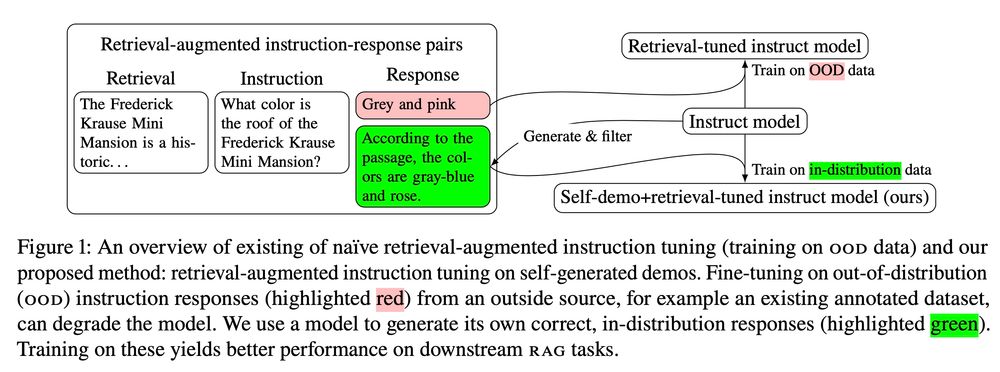
3/ OOD responses encourage the model to answer questions it does not know the answer to, and since retrievals are added post-hoc, the responses tend ignore or even contradict the retrieved context. Instead of training on these low-quality responses, we use the LLM to generate "self-demos".
February 25, 2025 at 9:55 PM
3/ OOD responses encourage the model to answer questions it does not know the answer to, and since retrievals are added post-hoc, the responses tend ignore or even contradict the retrieved context. Instead of training on these low-quality responses, we use the LLM to generate "self-demos".
2/ A popular recipe for adapting LLMs for RAG involves adding retrievals post-hoc to an existing instruction-tuning dataset. The hope is that the LLM learns to leverage the added context to respond to instructions. Unfortunately, the gold responses in these datasets tend to be OOD for the model.
February 25, 2025 at 9:55 PM
2/ A popular recipe for adapting LLMs for RAG involves adding retrievals post-hoc to an existing instruction-tuning dataset. The hope is that the LLM learns to leverage the added context to respond to instructions. Unfortunately, the gold responses in these datasets tend to be OOD for the model.