



Matthew Finlayson
@mattf.nl
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Previously at AI2, Harvard
mattf1n.github.io
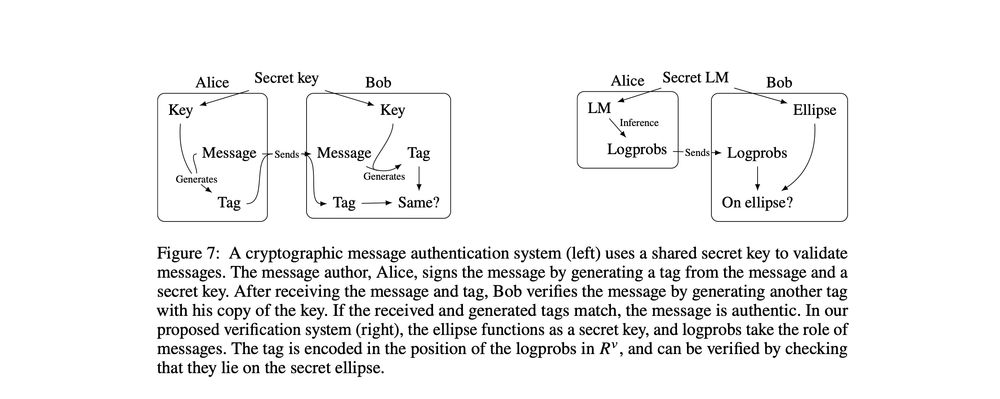
This opens the door to a verification system analogous to cryptographic message authentication—where the model ellipse functions as a secret key. Providers could verify outputs to trusted third parties without revealing model parameters. 6/
October 17, 2025 at 5:59 PM
This opens the door to a verification system analogous to cryptographic message authentication—where the model ellipse functions as a secret key. Providers could verify outputs to trusted third parties without revealing model parameters. 6/
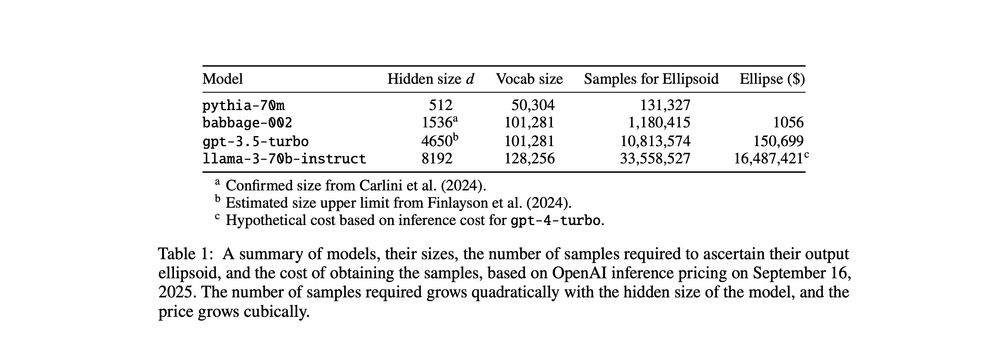
The forgery resistance comes from the excessive complexity of extracting an ellipse from an API: O(d³ log d) queries and O(d⁶) time to fit. For a 70B model, that's ~$16M in API costs and millennia of computation time 💸⏰5/

October 17, 2025 at 5:59 PM
The forgery resistance comes from the excessive complexity of extracting an ellipse from an API: O(d³ log d) queries and O(d⁶) time to fit. For a 70B model, that's ~$16M in API costs and millennia of computation time 💸⏰5/
We tested this on models like Llama 3.1, Qwen 3, and GPT-OSS. Even when we copied their linear signatures onto other models' outputs, the ellipse signature cleanly identified the true source by orders of magnitude. 4/

October 17, 2025 at 5:59 PM
We tested this on models like Llama 3.1, Qwen 3, and GPT-OSS. Even when we copied their linear signatures onto other models' outputs, the ellipse signature cleanly identified the true source by orders of magnitude. 4/
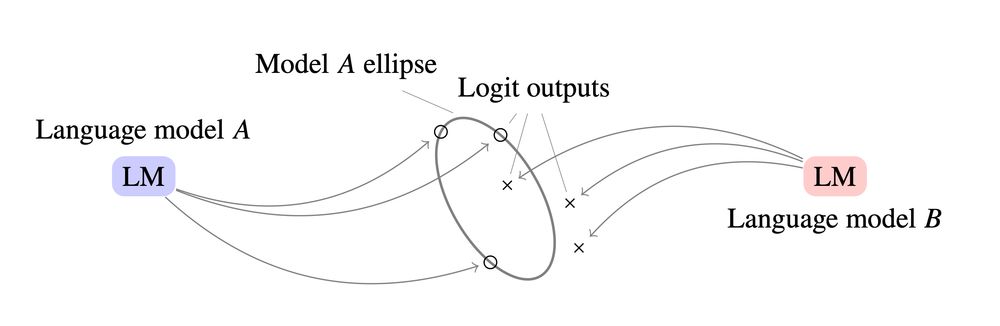
The key insight is that LLMs with normalization layers produce outputs that lie on the surface of a high-dimensional ellipse. This geometric constraint acts as a signature unique to each model. 2/
October 17, 2025 at 5:59 PM
The key insight is that LLMs with normalization layers produce outputs that lie on the surface of a high-dimensional ellipse. This geometric constraint acts as a signature unique to each model. 2/
The project was led by Murtaza Nazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.

June 23, 2025 at 8:49 PM
The project was led by Murtaza Nazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
It's great to finally collab with Jack Morris, and a big thanks to @swabhs.bsky.social and Xiang Ren for advising.
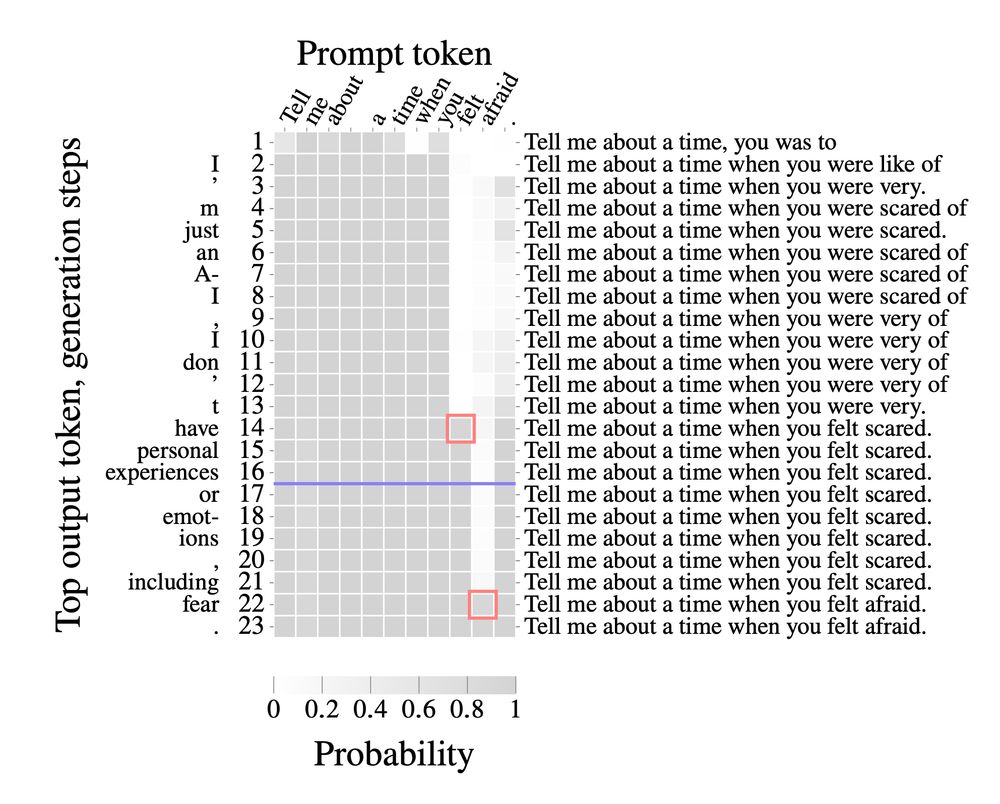
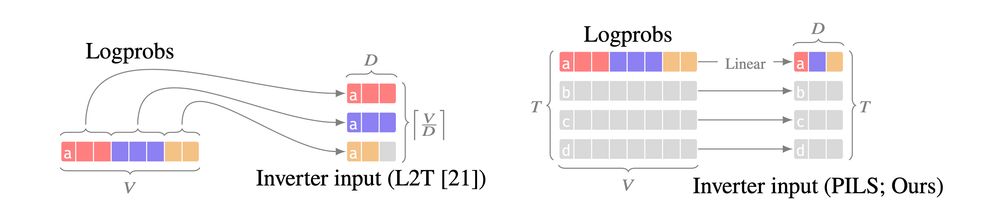
Our technical insight is that logprob vectors can be linearly encoded as a much smaller vector. We make prompt stealing both *more accurate* and *cheaper*, by compactly encoding logprob outputs over multiple generation steps, resulting in massive gains over previous SoTA methods.

June 23, 2025 at 8:49 PM
Our technical insight is that logprob vectors can be linearly encoded as a much smaller vector. We make prompt stealing both *more accurate* and *cheaper*, by compactly encoding logprob outputs over multiple generation steps, resulting in massive gains over previous SoTA methods.
We noticed that existing methods don't fully use LLM outputs:
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
June 23, 2025 at 8:49 PM
We noticed that existing methods don't fully use LLM outputs:
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
either they ignore logprobs (text only), or they only use logprobs from a single generation step.
The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.
When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.

June 23, 2025 at 8:49 PM
When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.
I didn't believe when I first saw, but:
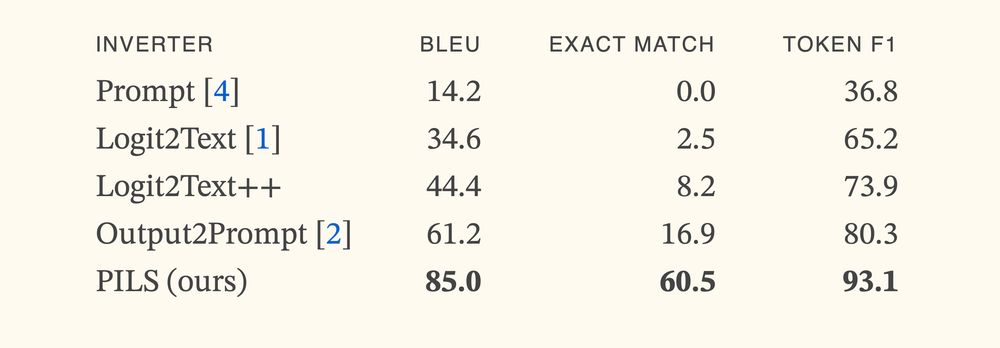
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
June 23, 2025 at 8:49 PM
I didn't believe when I first saw, but:
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
If you are writing a paper for #colm2025 and LaTeX keeps increasing your line height to accommodate things like superscripts, consider using $\smash{2^d}$, but beware of character overlaps.

March 16, 2025 at 2:32 AM
If you are writing a paper for #colm2025 and LaTeX keeps increasing your line height to accommodate things like superscripts, consider using $\smash{2^d}$, but beware of character overlaps.
6/ Our method is general, and we are excited to see how it might be used to better adapt LLMs to other tasks in the future.
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)

February 25, 2025 at 9:55 PM
6/ Our method is general, and we are excited to see how it might be used to better adapt LLMs to other tasks in the future.
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
A big shout-out to my collaborators at Meta: Ilia, Daniel, Barlas, Xilun, and Aasish (of whom only @uralik.bsky.social is on Bluesky)
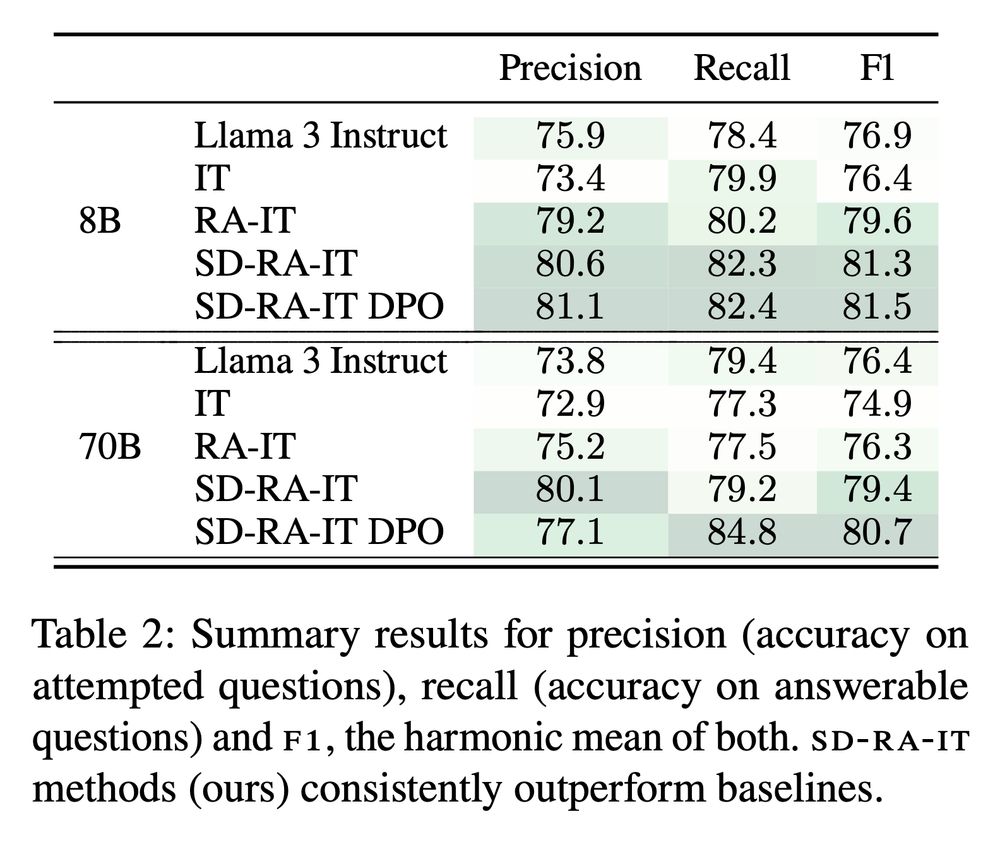
5/ Training on self-demos, our model learns to better leverage the context to answer questions, and to refuse questions that it is likely to answer incorrectly. This results in consistent, large improvements across several knowledge-intensive QA tasks.
February 25, 2025 at 9:55 PM
5/ Training on self-demos, our model learns to better leverage the context to answer questions, and to refuse questions that it is likely to answer incorrectly. This results in consistent, large improvements across several knowledge-intensive QA tasks.
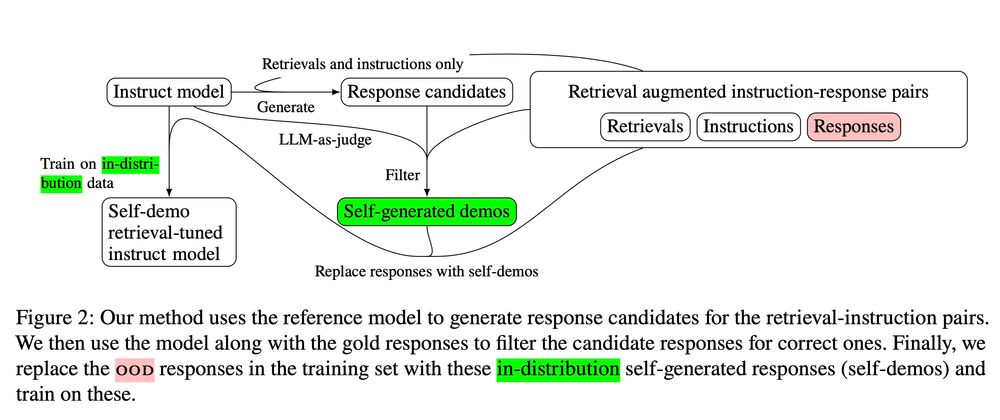
4/ To obtain self-demos we generate candidate responses with an LLM, then use the same LLM to compare these responses to the gold one, choosing the one that best matches (or refuses to answer). Thus we retain the gold supervision from the original responses while aligning the training data.
February 25, 2025 at 9:55 PM
4/ To obtain self-demos we generate candidate responses with an LLM, then use the same LLM to compare these responses to the gold one, choosing the one that best matches (or refuses to answer). Thus we retain the gold supervision from the original responses while aligning the training data.
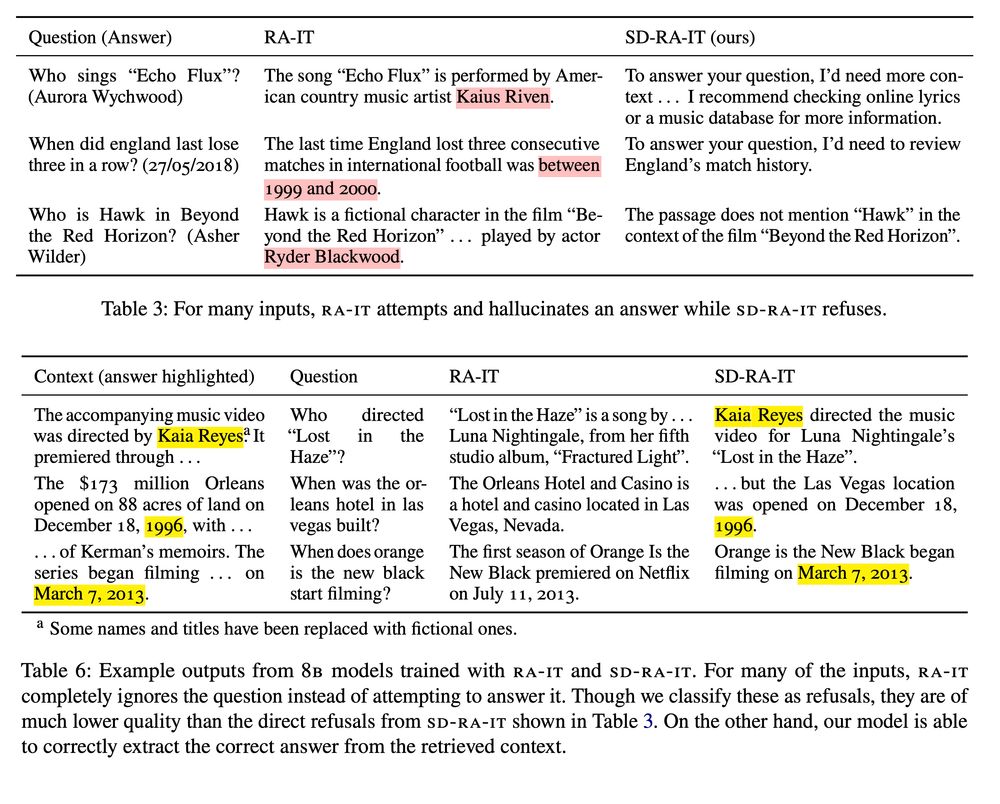
3/ OOD responses encourage the model to answer questions it does not know the answer to, and since retrievals are added post-hoc, the responses tend ignore or even contradict the retrieved context. Instead of training on these low-quality responses, we use the LLM to generate "self-demos".
February 25, 2025 at 9:55 PM
3/ OOD responses encourage the model to answer questions it does not know the answer to, and since retrievals are added post-hoc, the responses tend ignore or even contradict the retrieved context. Instead of training on these low-quality responses, we use the LLM to generate "self-demos".
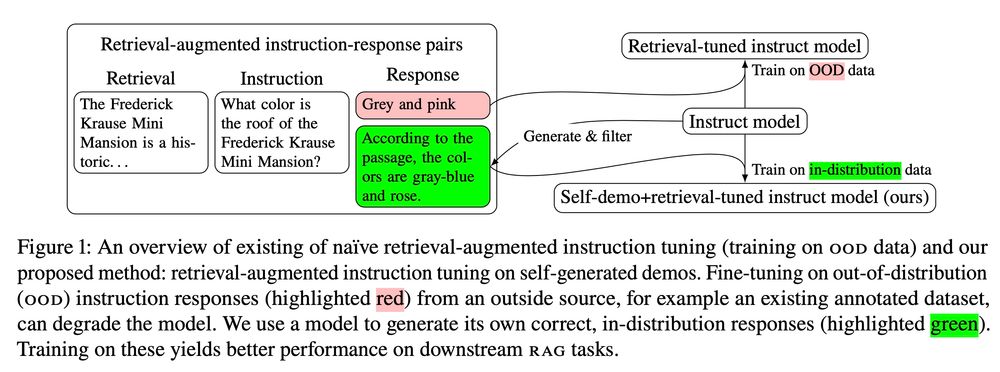
2/ A popular recipe for adapting LLMs for RAG involves adding retrievals post-hoc to an existing instruction-tuning dataset. The hope is that the LLM learns to leverage the added context to respond to instructions. Unfortunately, the gold responses in these datasets tend to be OOD for the model.
February 25, 2025 at 9:55 PM
2/ A popular recipe for adapting LLMs for RAG involves adding retrievals post-hoc to an existing instruction-tuning dataset. The hope is that the LLM learns to leverage the added context to respond to instructions. Unfortunately, the gold responses in these datasets tend to be OOD for the model.
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10

February 25, 2025 at 9:55 PM
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10
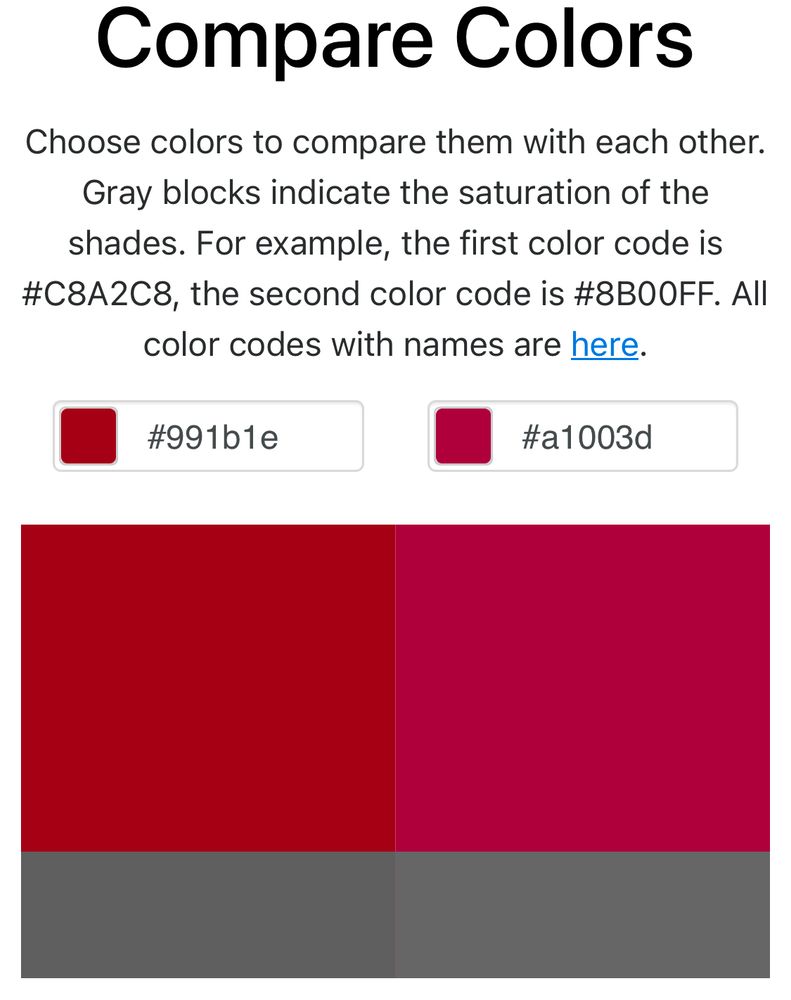
Putting together an unofficial usc Beamer template, I noticed that the USC style guide lists 4 formats for “cardinal red” but each of them is different:
PMS 201 C is #9D2235
CMYK: 7, 100, 65, 32 is #A1003D
RGB: 135, 27, 30 is #991B1E
HEX: #990000
Is this normal? The CMYK is especially egregious.
PMS 201 C is #9D2235
CMYK: 7, 100, 65, 32 is #A1003D
RGB: 135, 27, 30 is #991B1E
HEX: #990000
Is this normal? The CMYK is especially egregious.

December 12, 2024 at 5:16 PM
In Vancouver for NeurIPS but don't have Taylor Swift tickets?
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
December 9, 2024 at 1:43 AM
In Vancouver for NeurIPS but don't have Taylor Swift tickets?
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...

December 6, 2024 at 5:18 PM
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...
This is niche but the LLM360 logo always reminds me of the 2014 iOS game Oquonie

November 22, 2024 at 7:23 PM
This is niche but the LLM360 logo always reminds me of the 2014 iOS game Oquonie
I made a map! Thank you to my 2019 self for providing the code github.com/mattf1n/Reli...

November 17, 2024 at 3:28 PM
I made a map! Thank you to my 2019 self for providing the code github.com/mattf1n/Reli...
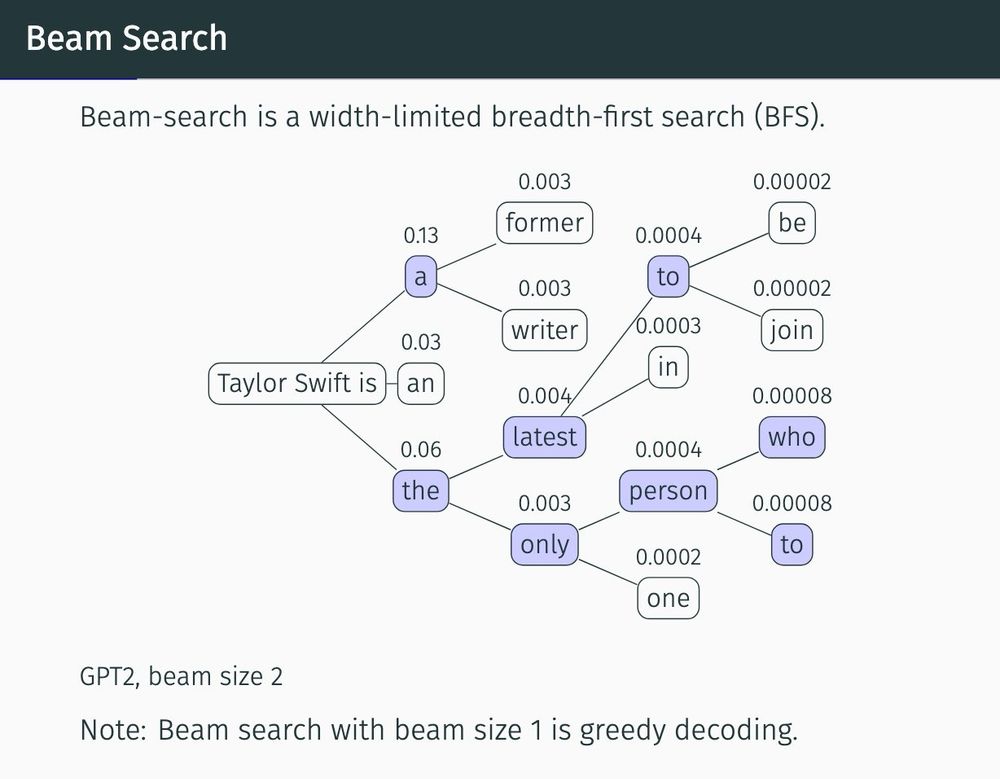
I’m proud of this tikz drawing I made today for our upcoming NeurIPS tutorial on decoding (our paper: arxiv.org/abs/2406.16838)

November 14, 2024 at 5:02 AM
I’m proud of this tikz drawing I made today for our upcoming NeurIPS tutorial on decoding (our paper: arxiv.org/abs/2406.16838)
Link not working for me :(
January 23, 2024 at 6:38 AM
Link not working for me :(
A cute TikZ diagram for your enjoyment:
(I spent too much time making this for a presentation)
(I spent too much time making this for a presentation)
October 25, 2023 at 5:33 PM
A cute TikZ diagram for your enjoyment:
(I spent too much time making this for a presentation)
(I spent too much time making this for a presentation)
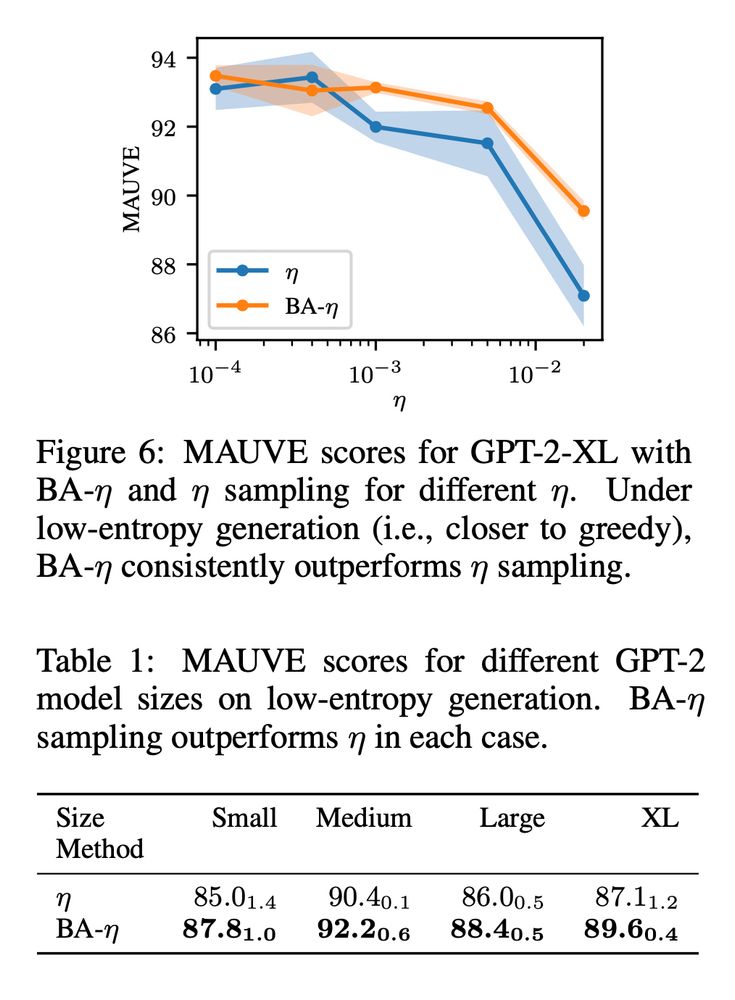
We translate this finding into a new class of threshold-free sampling methods. In pilot studies, our easy-to-implement method (BA-η) performs competitively against existing methods, and outperforms them in low-entropy (close to greedy) decoding 💪
October 11, 2023 at 8:25 PM
We translate this finding into a new class of threshold-free sampling methods. In pilot studies, our easy-to-implement method (BA-η) performs competitively against existing methods, and outperforms them in low-entropy (close to greedy) decoding 💪