



Matthew Finlayson
@mattf.nl
NLP PhD @ USC
Previously at AI2, Harvard
mattf1n.github.io
Previously at AI2, Harvard
mattf1n.github.io
Pinned
Matthew Finlayson
@mattf.nl
· 24d

Every Language Model Has a Forgery-Resistant Signature
The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying...
arxiv.org
We discovered that language models leave a natural "signature" on their API outputs that's extremely hard to fake. Here's how it works 🔍
📄 arxiv.org/abs/2510.14086 1/
📄 arxiv.org/abs/2510.14086 1/
Reposted by Matthew Finlayson
Gordon ramsey: Excuse me darling, what’s going on in there
LLM architect: the uhh model’s outputs lie on a high-dimensional ellipse
Gordon: on a high-dimensional ellipse?
Architect: correct, a high-dimensional ellipse
Gordon: fuck me. Ok thank you darling
LLM architect: the uhh model’s outputs lie on a high-dimensional ellipse
Gordon: on a high-dimensional ellipse?
Architect: correct, a high-dimensional ellipse
Gordon: fuck me. Ok thank you darling
We discovered that language models leave a natural "signature" on their API outputs that's extremely hard to fake. Here's how it works 🔍
📄 arxiv.org/abs/2510.14086 1/
📄 arxiv.org/abs/2510.14086 1/
Every Language Model Has a Forgery-Resistant Signature
The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying...
arxiv.org
October 18, 2025 at 7:21 PM
Gordon ramsey: Excuse me darling, what’s going on in there
LLM architect: the uhh model’s outputs lie on a high-dimensional ellipse
Gordon: on a high-dimensional ellipse?
Architect: correct, a high-dimensional ellipse
Gordon: fuck me. Ok thank you darling
LLM architect: the uhh model’s outputs lie on a high-dimensional ellipse
Gordon: on a high-dimensional ellipse?
Architect: correct, a high-dimensional ellipse
Gordon: fuck me. Ok thank you darling
We discovered that language models leave a natural "signature" on their API outputs that's extremely hard to fake. Here's how it works 🔍
📄 arxiv.org/abs/2510.14086 1/
📄 arxiv.org/abs/2510.14086 1/
Every Language Model Has a Forgery-Resistant Signature
The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying...
arxiv.org
October 17, 2025 at 5:59 PM
We discovered that language models leave a natural "signature" on their API outputs that's extremely hard to fake. Here's how it works 🔍
📄 arxiv.org/abs/2510.14086 1/
📄 arxiv.org/abs/2510.14086 1/
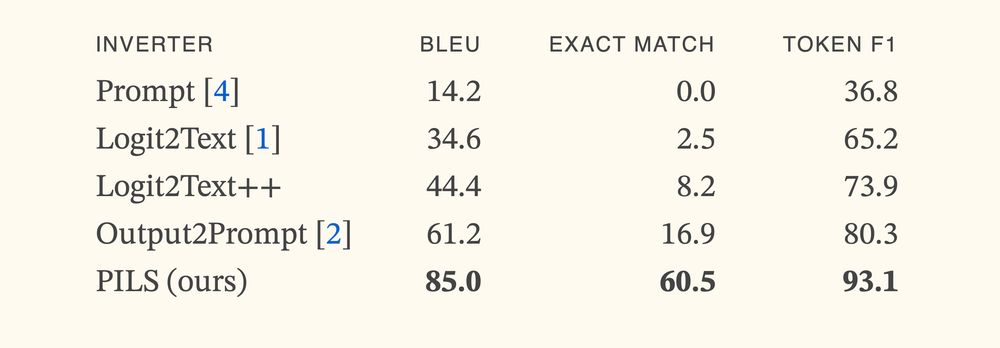
I didn't believe when I first saw, but:
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
June 23, 2025 at 8:49 PM
I didn't believe when I first saw, but:
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
We trained a prompt stealing model that gets >3x SoTA accuracy.
The secret is representing LLM outputs *correctly*
🚲 Demo/blog: mattf1n.github.io/pils
📄: arxiv.org/abs/2506.17090
🤖: huggingface.co/dill-lab/pi...
🧑💻: github.com/dill-lab/PILS
Reposted by Matthew Finlayson

I wish the ML community would stop trying to turn every technique into a brand name. Just give the thing a descriptive name and call it what it is.
Forced backronyms like this are counter productive.
Forced backronyms like this are counter productive.

June 11, 2025 at 3:10 PM
I wish the ML community would stop trying to turn every technique into a brand name. Just give the thing a descriptive name and call it what it is.
Forced backronyms like this are counter productive.
Forced backronyms like this are counter productive.
It appears that the only fonts with optical sizes that work with pdflatex are the computer/latin modern fonts. I would kill for a free pdflatex-compatible Times clone with optical sizes so my small text can look good in ArXiv/conference submissions.
June 4, 2025 at 4:05 PM
It appears that the only fonts with optical sizes that work with pdflatex are the computer/latin modern fonts. I would kill for a free pdflatex-compatible Times clone with optical sizes so my small text can look good in ArXiv/conference submissions.
If you are writing a paper for #colm2025 and LaTeX keeps increasing your line height to accommodate things like superscripts, consider using $\smash{2^d}$, but beware of character overlaps.

March 16, 2025 at 2:32 AM
If you are writing a paper for #colm2025 and LaTeX keeps increasing your line height to accommodate things like superscripts, consider using $\smash{2^d}$, but beware of character overlaps.
This project was made feasible by the excellent open-source LLM training library @fairseq2.bsky.social; I highly recommend giving it a look! It made both SFT and DPO a piece of cake 🍰
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10

February 25, 2025 at 9:58 PM
This project was made feasible by the excellent open-source LLM training library @fairseq2.bsky.social; I highly recommend giving it a look! It made both SFT and DPO a piece of cake 🍰
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10
February 25, 2025 at 9:55 PM
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out here: https://arxiv.org/abs/2502.10
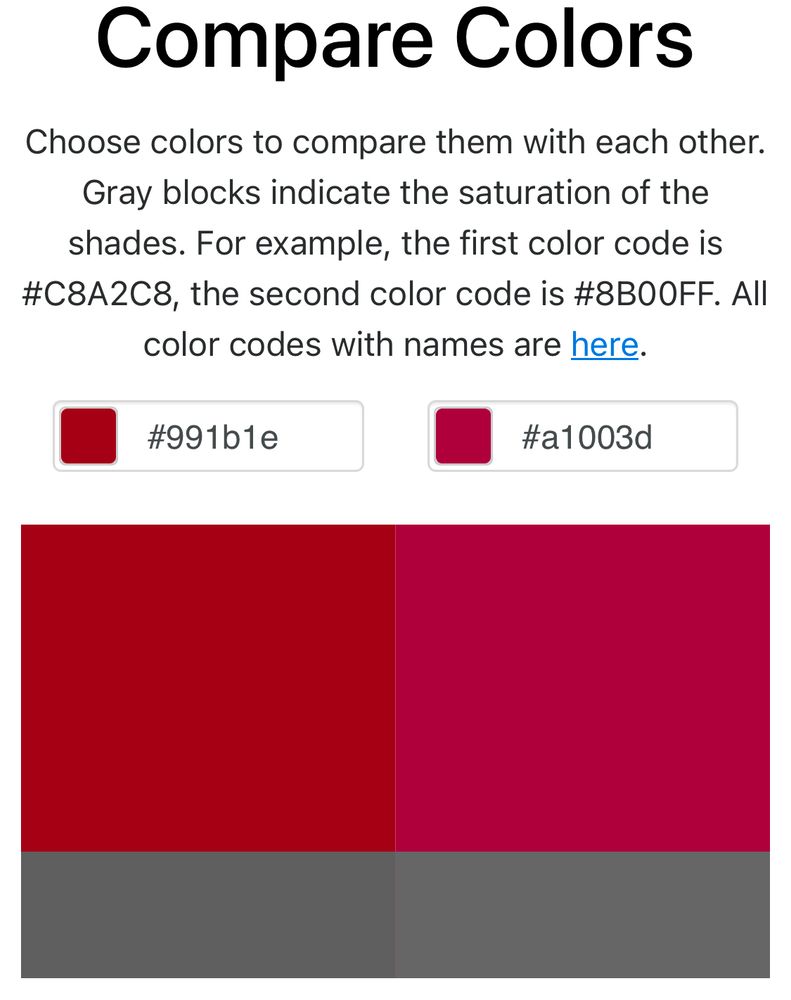
Putting together an unofficial usc Beamer template, I noticed that the USC style guide lists 4 formats for “cardinal red” but each of them is different:
PMS 201 C is #9D2235
CMYK: 7, 100, 65, 32 is #A1003D
RGB: 135, 27, 30 is #991B1E
HEX: #990000
Is this normal? The CMYK is especially egregious.
PMS 201 C is #9D2235
CMYK: 7, 100, 65, 32 is #A1003D
RGB: 135, 27, 30 is #991B1E
HEX: #990000
Is this normal? The CMYK is especially egregious.

December 12, 2024 at 5:16 PM
In Vancouver for NeurIPS but don't have Taylor Swift tickets?
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
December 9, 2024 at 1:43 AM
In Vancouver for NeurIPS but don't have Taylor Swift tickets?
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
You can still spend the day going through our tutorial reading list:
cmu-l3.github.io/neurips2024-...
Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...

December 6, 2024 at 5:18 PM
Curious about all this inference-time scaling hype? Attend our NeurIPS tutorial: Beyond Decoding: Meta-Generation Algorithms for LLMs (Tue. 1:30)! We have a top-notch panelist lineup.
Our website: cmu-l3.github.io/neurips2024-...
Our website: cmu-l3.github.io/neurips2024-...
Reposted by Matthew Finlayson

What's that? A fully open LM competitive with Gemma and Qwen*?
Happy to have helped a bit with this release (Tulu 3 recipe used here)! OLMo-2 13B actually beats Tulu 3 8B on these evals, making it a SOTA fully open LM!!!
(*on the benchmarks we looked at, see tweet for more)
Happy to have helped a bit with this release (Tulu 3 recipe used here)! OLMo-2 13B actually beats Tulu 3 8B on these evals, making it a SOTA fully open LM!!!
(*on the benchmarks we looked at, see tweet for more)

Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
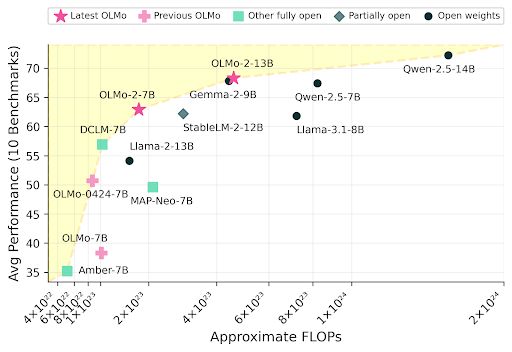
November 26, 2024 at 8:54 PM
What's that? A fully open LM competitive with Gemma and Qwen*?
Happy to have helped a bit with this release (Tulu 3 recipe used here)! OLMo-2 13B actually beats Tulu 3 8B on these evals, making it a SOTA fully open LM!!!
(*on the benchmarks we looked at, see tweet for more)
Happy to have helped a bit with this release (Tulu 3 recipe used here)! OLMo-2 13B actually beats Tulu 3 8B on these evals, making it a SOTA fully open LM!!!
(*on the benchmarks we looked at, see tweet for more)
These folks have had a huge impact on my research

November 26, 2024 at 6:39 PM
These folks have had a huge impact on my research
Reposted by Matthew Finlayson

This is niche but the LLM360 logo always reminds me of the 2014 iOS game Oquonie

November 22, 2024 at 7:23 PM
This is niche but the LLM360 logo always reminds me of the 2014 iOS game Oquonie
Hottest new research challenge: find the lost LLM head!
We actually have all the weights.... except the LM head for this blursed checkpoint. Don't ask.

oh btw, we accidentally deleted our "BEST" Tulu 3 70B model. This one was only our second best model, so if we cook up an even better one again, we'll give it to the people.
405B is being planned 🤞🤡
405B is being planned 🤞🤡
November 22, 2024 at 7:30 AM
Hottest new research challenge: find the lost LLM head!
Everyone follow Sean! He's been working nonstop to perfect our upcoming NeurIPS tutorial

I was honored to give a talk at Simons Institute on inference-time algorithms and meta-generation!
simons.berkeley.edu/talks/sean-w...
It was a sneak-preview subset of our NeurIPS tutorial:
cmu-l3.github.io/neurips2024-...
simons.berkeley.edu/talks/sean-w...
It was a sneak-preview subset of our NeurIPS tutorial:
cmu-l3.github.io/neurips2024-...




November 22, 2024 at 12:31 AM
Everyone follow Sean! He's been working nonstop to perfect our upcoming NeurIPS tutorial
Reposted by Matthew Finlayson

As "X is all you need" and "Transformers are Y" paper titles have died, I propose that we similarly retire:
- X of thought
- Chain of Y
- "[topic] a comprehensive survey" where [topic] is exclusively post-2022 papers
- Claims of reasoning/world model/planning based on private defns of one
- X of thought
- Chain of Y
- "[topic] a comprehensive survey" where [topic] is exclusively post-2022 papers
- Claims of reasoning/world model/planning based on private defns of one
November 21, 2024 at 10:20 AM
As "X is all you need" and "Transformers are Y" paper titles have died, I propose that we similarly retire:
- X of thought
- Chain of Y
- "[topic] a comprehensive survey" where [topic] is exclusively post-2022 papers
- Claims of reasoning/world model/planning based on private defns of one
- X of thought
- Chain of Y
- "[topic] a comprehensive survey" where [topic] is exclusively post-2022 papers
- Claims of reasoning/world model/planning based on private defns of one
Reposted by Matthew Finlayson


I made a map! Thank you to my 2019 self for providing the code github.com/mattf1n/Reli...

November 17, 2024 at 3:28 PM
I made a map! Thank you to my 2019 self for providing the code github.com/mattf1n/Reli...
Today I learned you can add a citation link to your GitHub repo. citation-file-format.github.io
citation-file-format.github.io
November 15, 2024 at 6:52 PM
Today I learned you can add a citation link to your GitHub repo. citation-file-format.github.io
Reposted by Matthew Finlayson

Oh my, USC is an empire!
November 15, 2024 at 12:02 AM
Oh my, USC is an empire!
Reposted by Matthew Finlayson

And we're having a great time at #EMNLP2024, come talk to us!

November 14, 2024 at 11:34 PM
And we're having a great time at #EMNLP2024, come talk to us!
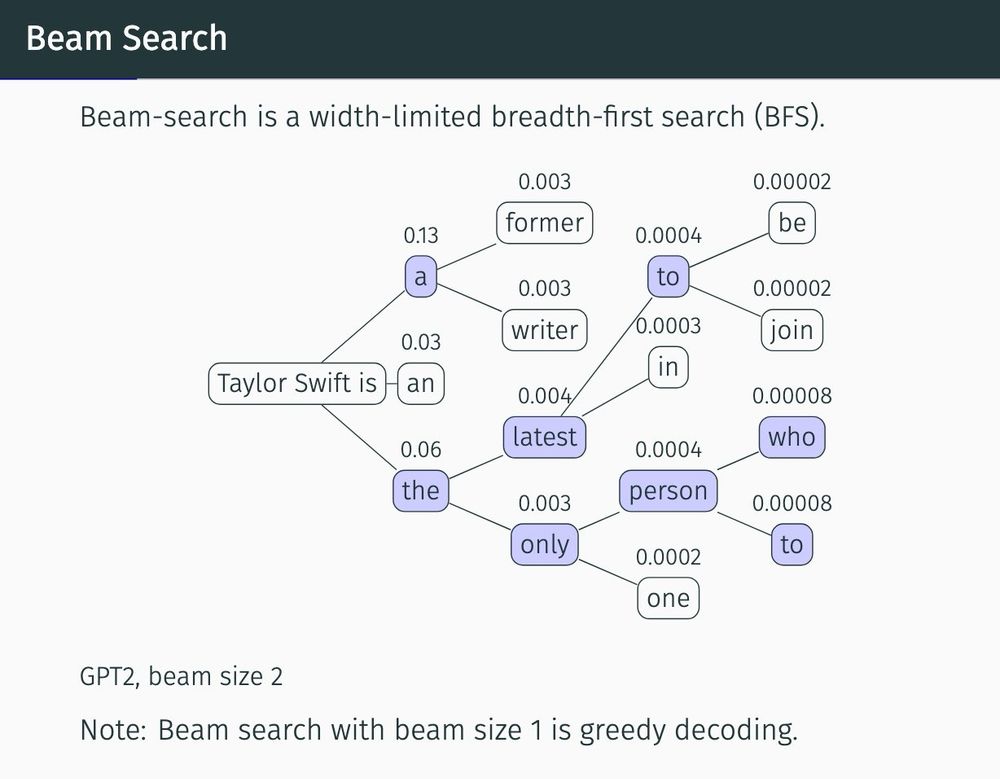
I’m proud of this tikz drawing I made today for our upcoming NeurIPS tutorial on decoding (our paper: arxiv.org/abs/2406.16838)

November 14, 2024 at 5:02 AM
I’m proud of this tikz drawing I made today for our upcoming NeurIPS tutorial on decoding (our paper: arxiv.org/abs/2406.16838)
Reposted by Matthew Finlayson

I'll be presenting "Distributional Properties of Subword Regularization" with @zouharvi.bsky.social and Naoaki Okazaki at #EMNLP.
arxiv.org/abs/2408.11443
The idea is that stochastic variants of BPE/MaxMatch produce very biased tokenization distributions, which is probably bad for modeling.
#NLP
arxiv.org/abs/2408.11443
The idea is that stochastic variants of BPE/MaxMatch produce very biased tokenization distributions, which is probably bad for modeling.
#NLP

November 9, 2024 at 5:06 PM
I'll be presenting "Distributional Properties of Subword Regularization" with @zouharvi.bsky.social and Naoaki Okazaki at #EMNLP.
arxiv.org/abs/2408.11443
The idea is that stochastic variants of BPE/MaxMatch produce very biased tokenization distributions, which is probably bad for modeling.
#NLP
arxiv.org/abs/2408.11443
The idea is that stochastic variants of BPE/MaxMatch produce very biased tokenization distributions, which is probably bad for modeling.
#NLP