


Martin Görner
@martin-gorner.bsky.social
AI/ML engineer. Previously at Google: Product Manager for Keras and TensorFlow and developer advocate on TPUs. Passionate about democratizing Machine Learning.
Announcing our next-gen chip: axelera.ai/news/axelera...
• 628 TOPS
• in-memory compute (IMC) matrix multipliers <- this is Axelera's tech edge
• 16 Risc-V vector cores for that will handle pre- and post-processing directly on chip.
• 628 TOPS
• in-memory compute (IMC) matrix multipliers <- this is Axelera's tech edge
• 16 Risc-V vector cores for that will handle pre- and post-processing directly on chip.

Axelera Announces Europa AIPU, Setting New Industry Benchmark for AI Accelerator Performance, Power Efficiency and Affordability
Axelera® today announced Europa™, an AI processor unit (AIPU) that sets a new performance/price standard for multi-user generative AI and computer vision applications.
axelera.ai
October 21, 2025 at 12:20 PM
Announcing our next-gen chip: axelera.ai/news/axelera...
• 628 TOPS
• in-memory compute (IMC) matrix multipliers <- this is Axelera's tech edge
• 16 Risc-V vector cores for that will handle pre- and post-processing directly on chip.
• 628 TOPS
• in-memory compute (IMC) matrix multipliers <- this is Axelera's tech edge
• 16 Risc-V vector cores for that will handle pre- and post-processing directly on chip.
The secret sauce works!
www.forbes.com/sites/daveal...
www.forbes.com/sites/daveal...

Axelera AI Accelerators Smoke Competitors In Machine Vision Research Study
Domain-specific accelerators are proving they can compete, and in some cases lead, in the metrics that matter most for real-world deployments.
www.forbes.com
July 16, 2025 at 3:32 PM
The secret sauce works!
www.forbes.com/sites/daveal...
www.forbes.com/sites/daveal...
Blog post by A-Tang Fan and Doug Watt about Axelera.ai's Voyager SDK: community.axelera.ai/product-upda...
Simplifying Model and Pipeline Deployment with the Voyager SDK | Community
Axelera AI’s A-Tang Fan and Doug Watt explain how the Voyager SDK simplifies the complex task of deploying AI-powered video pipelines on edge devices. This blog explores how its model compiler, model ...
community.axelera.ai
May 30, 2025 at 2:35 PM
Blog post by A-Tang Fan and Doug Watt about Axelera.ai's Voyager SDK: community.axelera.ai/product-upda...
I'm delighted to share that I joined the Axelera team this week to deliver the next generation AI compute platform. axelera.ai

May 7, 2025 at 2:21 PM
I'm delighted to share that I joined the Axelera team this week to deliver the next generation AI compute platform. axelera.ai
Reinforcement Learning (RL) just landed a stellar breakthrough with reasoning language models. Yet, RL has a distinctly bad reputation. See “To RL or not to RL” (www.reddit.com/r/MachineLe...) on reddit.
I'd like to revisit the basic math of RL to see why. Let's enter the dungeon!
I'd like to revisit the basic math of RL to see why. Let's enter the dungeon!

March 11, 2025 at 1:39 AM
Reinforcement Learning (RL) just landed a stellar breakthrough with reasoning language models. Yet, RL has a distinctly bad reputation. See “To RL or not to RL” (www.reddit.com/r/MachineLe...) on reddit.
I'd like to revisit the basic math of RL to see why. Let's enter the dungeon!
I'd like to revisit the basic math of RL to see why. Let's enter the dungeon!
Are you still using LoRA to fine-tune your LLM? 2024 has seen an explosion of new parameter-efficient fine tuning technique (PEFT), thanks to clever uses of the singular value decomposition (SVD). Let's dive into the alphabet soup: SVF, SVFT, MiLoRA, PiSSA, LoRA-XS 🤯...

February 20, 2025 at 12:38 PM
Are you still using LoRA to fine-tune your LLM? 2024 has seen an explosion of new parameter-efficient fine tuning technique (PEFT), thanks to clever uses of the singular value decomposition (SVD). Let's dive into the alphabet soup: SVF, SVFT, MiLoRA, PiSSA, LoRA-XS 🤯...
Well worth reading: @fchollet.bsky.social 's analysis of OpenAI's o3 breakthrough score of 76% on the ARC-AGI benchmark: arcprize.org/blog/oai-o3-...

OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
OpenAI o3 scores 75.7% on ARC-AGI public leaderboard.
arcprize.org
February 19, 2025 at 11:51 AM
Well worth reading: @fchollet.bsky.social 's analysis of OpenAI's o3 breakthrough score of 76% on the ARC-AGI benchmark: arcprize.org/blog/oai-o3-...
Sakana.ai's Transformer² arxiv.org/abs/2501.06252 paper features a cool new parameter-efficient fine-tuning (PEFT) technique that makes tuned models composable! Let’s dive in 💦.
(They have stunning artwork on their website 🤩 too)
(They have stunning artwork on their website 🤩 too)

February 10, 2025 at 10:04 PM
Sakana.ai's Transformer² arxiv.org/abs/2501.06252 paper features a cool new parameter-efficient fine-tuning (PEFT) technique that makes tuned models composable! Let’s dive in 💦.
(They have stunning artwork on their website 🤩 too)
(They have stunning artwork on their website 🤩 too)
Posted on Twitter in Nov: looking at the "AI achieves Kaggle Grandmaster Level" paper published last week: arxiv.org/abs/2411.03562. A massive 88-page paper. Here is a summary.

February 6, 2025 at 11:55 AM
Posted on Twitter in Nov: looking at the "AI achieves Kaggle Grandmaster Level" paper published last week: arxiv.org/abs/2411.03562. A massive 88-page paper. Here is a summary.
I'm exiting Twitter/X after being served an ad there for a neo-nazi podcast. The X exodus is massive and you don't have to lose your followers. Thanks to #HelloQuitX I've registered 19567 new passengers for a journey to #BlueSky. Join us on app.helloquitx.com.
HelloQuitteX
Libérez vos espaces numériques
app.helloquitx.com
January 22, 2025 at 8:25 AM
I'm exiting Twitter/X after being served an ad there for a neo-nazi podcast. The X exodus is massive and you don't have to lose your followers. Thanks to #HelloQuitX I've registered 19567 new passengers for a journey to #BlueSky. Join us on app.helloquitx.com.
Personal update: I am no longer at Hugging Face. I will take some time to pursue personal projects and find my next adventure. DMs open. Feel free to ping me if you have an interesting AI/ML project to share!

January 7, 2025 at 12:24 PM
Personal update: I am no longer at Hugging Face. I will take some time to pursue personal projects and find my next adventure. DMs open. Feel free to ping me if you have an interesting AI/ML project to share!
Did you know that you can load the newest checkpoints (like Llama 3.2) into Keras directly from the original HuggingFace release (safetensors)?
I tried - and lived to tell the tale: huggingface.co/blog/keras-l...
I tried - and lived to tell the tale: huggingface.co/blog/keras-l...

December 6, 2024 at 10:11 AM
Did you know that you can load the newest checkpoints (like Llama 3.2) into Keras directly from the original HuggingFace release (safetensors)?
I tried - and lived to tell the tale: huggingface.co/blog/keras-l...
I tried - and lived to tell the tale: huggingface.co/blog/keras-l...
Reposted by Martin Görner

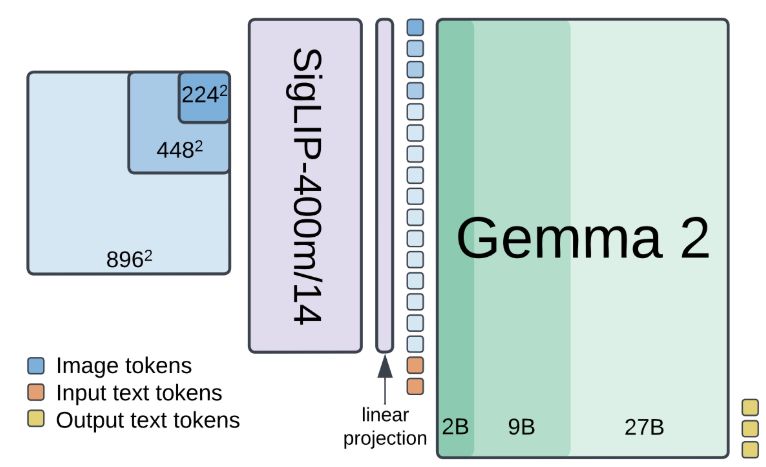
The fourth nice thing we* have for you this week: PaliGemma 2.
It’s also a perfect transition: this v2 was carried a lot more by @andreaspsteiner.bsky.social André and Michael than by us.
Crazy new sota tasks! Interesting res vs LLM size study! Better OCR! Less hallucination!
It’s also a perfect transition: this v2 was carried a lot more by @andreaspsteiner.bsky.social André and Michael than by us.
Crazy new sota tasks! Interesting res vs LLM size study! Better OCR! Less hallucination!

🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
1/7
December 5, 2024 at 8:19 PM
The fourth nice thing we* have for you this week: PaliGemma 2.
It’s also a perfect transition: this v2 was carried a lot more by @andreaspsteiner.bsky.social André and Michael than by us.
Crazy new sota tasks! Interesting res vs LLM size study! Better OCR! Less hallucination!
It’s also a perfect transition: this v2 was carried a lot more by @andreaspsteiner.bsky.social André and Michael than by us.
Crazy new sota tasks! Interesting res vs LLM size study! Better OCR! Less hallucination!
Pitting a few Keras LLMs against each other:
huggingface.co/blog/keras-c...
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
huggingface.co/blog/keras-c...
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.

How good are LLMs at fixing their mistakes? A chatbot arena experiment with Keras and TPUs
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
December 5, 2024 at 7:21 PM
Pitting a few Keras LLMs against each other:
huggingface.co/blog/keras-c...
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
huggingface.co/blog/keras-c...
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
Pitting a few Keras LLMs against each other:
https://huggingface.co/blog/keras-chatbot-arena
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
https://huggingface.co/blog/keras-chatbot-arena
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.

February 6, 2025 at 12:53 PM
Pitting a few Keras LLMs against each other:
https://huggingface.co/blog/keras-chatbot-arena
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
https://huggingface.co/blog/keras-chatbot-arena
Using an super-simplified scenario, I wanted to see how easy it is to get them to fix their own mistakes.
I'm looking at the "AI achieves Kaggle Grandmaster Level" paper published last week: https://arxiv.org/abs/2411.03562. A massive 88-page paper. Here is a summary.

February 6, 2025 at 12:53 PM
I'm looking at the "AI achieves Kaggle Grandmaster Level" paper published last week: https://arxiv.org/abs/2411.03562. A massive 88-page paper. Here is a summary.
Looking at the code of the recent moonshine release: https://github.com/usefulsensors/moonshine (a speech recognition model optimized for mobile devices). It has a very clean Keras implementation! A couple of noteworthy details: (1/5)🧵

GitHub - usefulsensors/moonshine: Fast and accurate autom...
Fast and accurate automatic speech recognition (ASR) for ...
github.com
February 6, 2025 at 12:53 PM
Looking at the code of the recent moonshine release: https://github.com/usefulsensors/moonshine (a speech recognition model optimized for mobile devices). It has a very clean Keras implementation! A couple of noteworthy details: (1/5)🧵
Did you know that you can load the newest checkpoints (like Llama 3.2) into Keras directly from the original HuggingFace release (safetensors)?
I tried - and lived to tell the tale: https://huggingface.co/blog/keras-llama-32
I tried - and lived to tell the tale: https://huggingface.co/blog/keras-llama-32

February 6, 2025 at 12:53 PM
Did you know that you can load the newest checkpoints (like Llama 3.2) into Keras directly from the original HuggingFace release (safetensors)?
I tried - and lived to tell the tale: https://huggingface.co/blog/keras-llama-32
I tried - and lived to tell the tale: https://huggingface.co/blog/keras-llama-32
I just noticed: Keras 3 is now the default in Colab. Nice! Keras+JAX, Keras+PyTorch, Keras+TF right at your fingertips.

February 6, 2025 at 12:53 PM
I just noticed: Keras 3 is now the default in Colab. Nice! Keras+JAX, Keras+PyTorch, Keras+TF right at your fingertips.
Announcement #2: new Keras + Hugging Face integration: you can now load HF fine-tuned models through Keras, even if they have not been fine-tuned in Keras. As long as the architecture is implemented in KerasNLP, weights will be converted on the fly. Colab:...
February 6, 2025 at 12:53 PM
Announcement #2: new Keras + Hugging Face integration: you can now load HF fine-tuned models through Keras, even if they have not been fine-tuned in Keras. As long as the architecture is implemented in KerasNLP, weights will be converted on the fly. Colab:...
Gemma 2 has landed in KerasNLP: https://developers.googleblog.com/en/fine-tuning-gemma-2-with-keras-hugging-face-update/

Fine-tuning Gemma 2 with Keras - and an update from Huggi...
The next generation of Gemma models is now available in K...
developers.googleblog.com
February 6, 2025 at 12:53 PM
Gemma 2 has landed in KerasNLP: https://developers.googleblog.com/en/fine-tuning-gemma-2-with-keras-hugging-face-update/
New Keras starter notebook from @awsaf49 for the "LMSYS Chatbot Arena Human Preference" competition on Kaggle. This one is interesting for how it achieves preference classification over pairs of (prompt+response) using the DeBERTaV3 model from...
February 6, 2025 at 12:53 PM
New Keras starter notebook from @awsaf49 for the "LMSYS Chatbot Arena Human Preference" competition on Kaggle. This one is interesting for how it achieves preference classification over pairs of (prompt+response) using the DeBERTaV3 model from...
Google I/O is today and "Large language models with Keras" is at 4:30PM 🔥with @smn_sdt and @GabrielRasskin !

February 6, 2025 at 12:58 PM
Google I/O is today and "Large language models with Keras" is at 4:30PM 🔥with @smn_sdt and @GabrielRasskin !
Just released: you can now upload your Keras models to Kaggle Models or HuggingFace, directly from the Keras API:
https://developers.googleblog.com/en/publish-your-keras-models-on-kaggle-and-hugging-face/
https://developers.googleblog.com/en/publish-your-keras-models-on-kaggle-and-hugging-face/

Publish your Keras models on Kaggle and Hugging Face
Now you can publish your fine-tuned models directly from ...
developers.googleblog.com
February 6, 2025 at 12:58 PM
Just released: you can now upload your Keras models to Kaggle Models or HuggingFace, directly from the Keras API:
https://developers.googleblog.com/en/publish-your-keras-models-on-kaggle-and-hugging-face/
https://developers.googleblog.com/en/publish-your-keras-models-on-kaggle-and-hugging-face/
New Kaggle starter notebook from @awsaf49 for the Automated Essay Scoring competition: https://www.kaggle.com/code/awsaf49/aes-2-0-kerasnlp-starter.
It showcases the right way to do ordinal regression in Keras, i.e. how to predict ordered integer grades reliably (no it's neither a...
It showcases the right way to do ordinal regression in Keras, i.e. how to predict ordered integer grades reliably (no it's neither a...
AES 2.0: KerasNLP Starter
Explore and run machine learning code with Kaggle Noteboo...
www.kaggle.com
February 6, 2025 at 12:58 PM
New Kaggle starter notebook from @awsaf49 for the Automated Essay Scoring competition: https://www.kaggle.com/code/awsaf49/aes-2-0-kerasnlp-starter.
It showcases the right way to do ordinal regression in Keras, i.e. how to predict ordered integer grades reliably (no it's neither a...
It showcases the right way to do ordinal regression in Keras, i.e. how to predict ordered integer grades reliably (no it's neither a...