



Henry Jia
@henryjia.bsky.social
Machine learner, computational scientist, and engineer
Reposted by Henry Jia

Proud to release ShinkaEvolve, our open-source framework that evolves programs for scientific discovery with very good sample-efficiency! 🐙🧠
Paper: arxiv.org/abs/2509.19349
Blog: sakana.ai/shinka-evolve/
GitHub Project: github.com/SakanaAI/Shi...
Paper: arxiv.org/abs/2509.19349
Blog: sakana.ai/shinka-evolve/
GitHub Project: github.com/SakanaAI/Shi...

September 25, 2025 at 6:01 AM
Proud to release ShinkaEvolve, our open-source framework that evolves programs for scientific discovery with very good sample-efficiency! 🐙🧠
Paper: arxiv.org/abs/2509.19349
Blog: sakana.ai/shinka-evolve/
GitHub Project: github.com/SakanaAI/Shi...
Paper: arxiv.org/abs/2509.19349
Blog: sakana.ai/shinka-evolve/
GitHub Project: github.com/SakanaAI/Shi...
Reposted by Henry Jia

Policy churn: maybe epsilon greedy doesn’t matter that much because the Q value argmax action changes constantly
arxiv.org/abs/2206.00730
arxiv.org/abs/2206.00730
September 20, 2025 at 9:12 PM
Policy churn: maybe epsilon greedy doesn’t matter that much because the Q value argmax action changes constantly
arxiv.org/abs/2206.00730
arxiv.org/abs/2206.00730
Something I've noticed about bluesky is that it seems like the following tab is purely by chronological order. It means that if someone posts a lot, they kind of drown out all the other people I follow. It does kind of lower the signal to noise ratio on this app
September 20, 2025 at 12:36 AM
Something I've noticed about bluesky is that it seems like the following tab is purely by chronological order. It means that if someone posts a lot, they kind of drown out all the other people I follow. It does kind of lower the signal to noise ratio on this app

Reposted by Henry Jia

What drives behavior in living organisms? And how can we design artificial agents that learn interactively?
📢 To address these, the Sensorimotor AI Journal Club is launching the "RL Debate Series"👇
w/ @elisennesh.bsky.social, @noreward4u.bsky.social, @tommasosalvatori.bsky.social
🧵[1/5]
🧠🤖🧠📈
📢 To address these, the Sensorimotor AI Journal Club is launching the "RL Debate Series"👇
w/ @elisennesh.bsky.social, @noreward4u.bsky.social, @tommasosalvatori.bsky.social
🧵[1/5]
🧠🤖🧠📈

September 17, 2025 at 4:32 PM
What drives behavior in living organisms? And how can we design artificial agents that learn interactively?
📢 To address these, the Sensorimotor AI Journal Club is launching the "RL Debate Series"👇
w/ @elisennesh.bsky.social, @noreward4u.bsky.social, @tommasosalvatori.bsky.social
🧵[1/5]
🧠🤖🧠📈
📢 To address these, the Sensorimotor AI Journal Club is launching the "RL Debate Series"👇
w/ @elisennesh.bsky.social, @noreward4u.bsky.social, @tommasosalvatori.bsky.social
🧵[1/5]
🧠🤖🧠📈
Reposted by Henry Jia
There are very few settings where AI can outperform peak human. But, there are also so many situations where we are constrained by available labor! It's a complement not a substitute.
September 17, 2025 at 11:18 PM
There are very few settings where AI can outperform peak human. But, there are also so many situations where we are constrained by available labor! It's a complement not a substitute.
Reposted by Henry Jia

This is why you should not trust these models blindly and we need guardrails around them.

New research shows #DeepSeek suggests less-secure code when it is asked to help groups out of favor with the Chinese government. With its open-source model being adopted widely, this soft influence and hackability could spread. Gift link with email address etc. wapo.st/46jEZrb

AI firm DeepSeek writes less-secure code for groups China disfavors
Research by a U.S. security firm points to the country’s leading player in AI providing higher-quality results for some purposes than others.
wapo.st
September 17, 2025 at 12:28 AM
This is why you should not trust these models blindly and we need guardrails around them.
Reposted by Henry Jia
I think a year later not much has changed and this post still holds up open.substack.com/pub/emergere...

RL in the age of LLMs
What's still unsolved?
open.substack.com
September 17, 2025 at 1:19 AM
I think a year later not much has changed and this post still holds up open.substack.com/pub/emergere...
Reposted by Henry Jia

Coincidentally, this is also why people on Blusky hallucinate.

September 5, 2025 at 6:28 PM
Coincidentally, this is also why people on Blusky hallucinate.
Some people were talking about AI agents and whether LLMs can strategise.
So I asked ChatGPT to play chess with me
It tried to make an illegal move after 3 moves
chatgpt.com/share/68ba54...
So I think the answer is still no. It can't
So I asked ChatGPT to play chess with me
It tried to make an illegal move after 3 moves
chatgpt.com/share/68ba54...
So I think the answer is still no. It can't

September 5, 2025 at 3:21 AM
Some people were talking about AI agents and whether LLMs can strategise.
So I asked ChatGPT to play chess with me
It tried to make an illegal move after 3 moves
chatgpt.com/share/68ba54...
So I think the answer is still no. It can't
So I asked ChatGPT to play chess with me
It tried to make an illegal move after 3 moves
chatgpt.com/share/68ba54...
So I think the answer is still no. It can't
So, GPT5 is out. I had to ask it t he same question, what's the shortest 4 letter word?
It seems it can solve it, but the chain of thought it employed seemed to make absolutely zero sense. It looks more like it's trying to regenerate the same prompt over and over again and got stuck
It seems it can solve it, but the chain of thought it employed seemed to make absolutely zero sense. It looks more like it's trying to regenerate the same prompt over and over again and got stuck

August 12, 2025 at 5:03 AM
So, GPT5 is out. I had to ask it t he same question, what's the shortest 4 letter word?
It seems it can solve it, but the chain of thought it employed seemed to make absolutely zero sense. It looks more like it's trying to regenerate the same prompt over and over again and got stuck
It seems it can solve it, but the chain of thought it employed seemed to make absolutely zero sense. It looks more like it's trying to regenerate the same prompt over and over again and got stuck
Reposted by Henry Jia

Could a major opportunity to improve representation in deep learning be hiding in plain sight? Check out our new position paper: Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis.
Paper: arxiv.org/abs/2505.11581
Paper: arxiv.org/abs/2505.11581
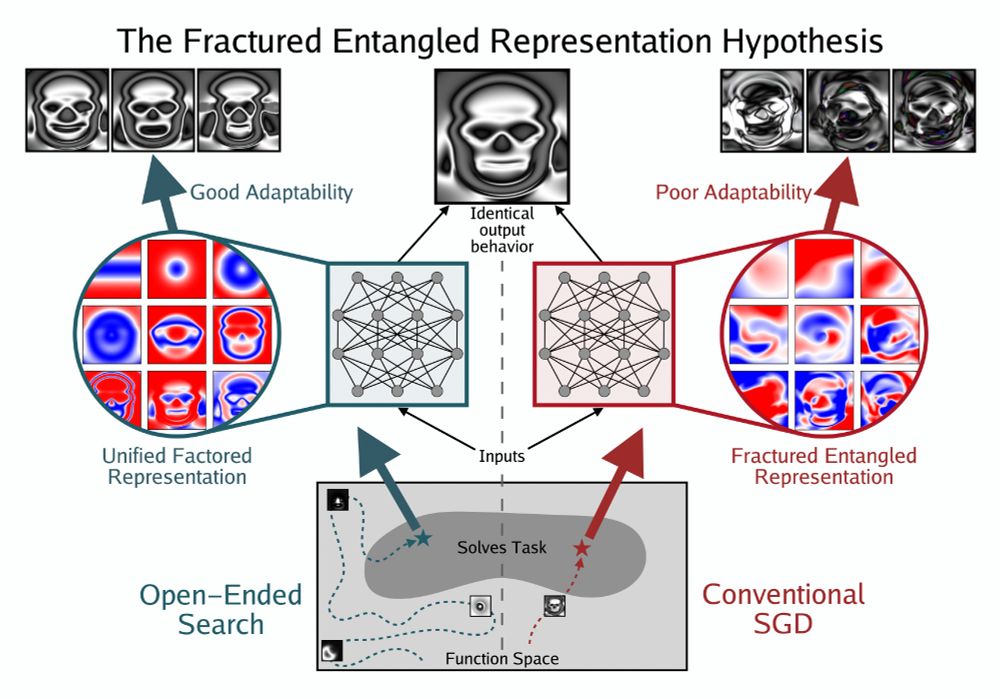
May 20, 2025 at 5:52 PM
Could a major opportunity to improve representation in deep learning be hiding in plain sight? Check out our new position paper: Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis.
Paper: arxiv.org/abs/2505.11581
Paper: arxiv.org/abs/2505.11581
Nice try Gemini lol. It's been like 2 years since I first came up with this trick question and some models still struggle to spot it it on first attempt

July 21, 2025 at 5:37 PM
Nice try Gemini lol. It's been like 2 years since I first came up with this trick question and some models still struggle to spot it it on first attempt
Reposted by Henry Jia


Reposted by Henry Jia



July 13, 2025 at 1:21 PM
Reposted by Henry Jia

We’re excited to introduce Text-to-LoRA: a Hypernetwork that generates task-specific LLM adapters (LoRAs) based on a text description of the task. Catch our presentation at #ICML2025!
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Tex...
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Tex...
June 12, 2025 at 1:47 AM
We’re excited to introduce Text-to-LoRA: a Hypernetwork that generates task-specific LLM adapters (LoRAs) based on a text description of the task. Catch our presentation at #ICML2025!
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Tex...
Paper: arxiv.org/abs/2506.06105
Code: github.com/SakanaAI/Tex...
Reposted by Henry Jia

Remember Toyota scandal, where cars just "better behaved" when tested?
If someone tested you, wouldn't you? And if you tested LLMs?
Finding: LLMs can tell when they are evaluated🧠
We can only wait to see how they act on it
alphaxiv.org/pdf/2505.23836
📈🧠🤖
If someone tested you, wouldn't you? And if you tested LLMs?
Finding: LLMs can tell when they are evaluated🧠
We can only wait to see how they act on it
alphaxiv.org/pdf/2505.23836
📈🧠🤖

Large Language Models Often Know When They Are Being Evaluated | alphaXiv
View recent discussion. Abstract: If AI models can detect when they are being evaluated, the effectiveness of
evaluations might be compromised. For example, models could have systematically
different ...
alphaxiv.org
June 8, 2025 at 1:49 PM
Remember Toyota scandal, where cars just "better behaved" when tested?
If someone tested you, wouldn't you? And if you tested LLMs?
Finding: LLMs can tell when they are evaluated🧠
We can only wait to see how they act on it
alphaxiv.org/pdf/2505.23836
📈🧠🤖
If someone tested you, wouldn't you? And if you tested LLMs?
Finding: LLMs can tell when they are evaluated🧠
We can only wait to see how they act on it
alphaxiv.org/pdf/2505.23836
📈🧠🤖
Reposted by Henry Jia
Training LLMs on many games can generalize and teaches
reasoning that holds in new environments.
However, weighting the games is complicated, so merging (my beloved fusing in the title) is used.
📈🤖🧠
alphaxiv.org/pdf/2505.16401
reasoning that holds in new environments.
However, weighting the games is complicated, so merging (my beloved fusing in the title) is used.
📈🤖🧠
alphaxiv.org/pdf/2505.16401

May 28, 2025 at 8:38 PM
Training LLMs on many games can generalize and teaches
reasoning that holds in new environments.
However, weighting the games is complicated, so merging (my beloved fusing in the title) is used.
📈🤖🧠
alphaxiv.org/pdf/2505.16401
reasoning that holds in new environments.
However, weighting the games is complicated, so merging (my beloved fusing in the title) is used.
📈🤖🧠
alphaxiv.org/pdf/2505.16401