



Michael Griffiths
@griffiths.ai
Reposted by Michael Griffiths

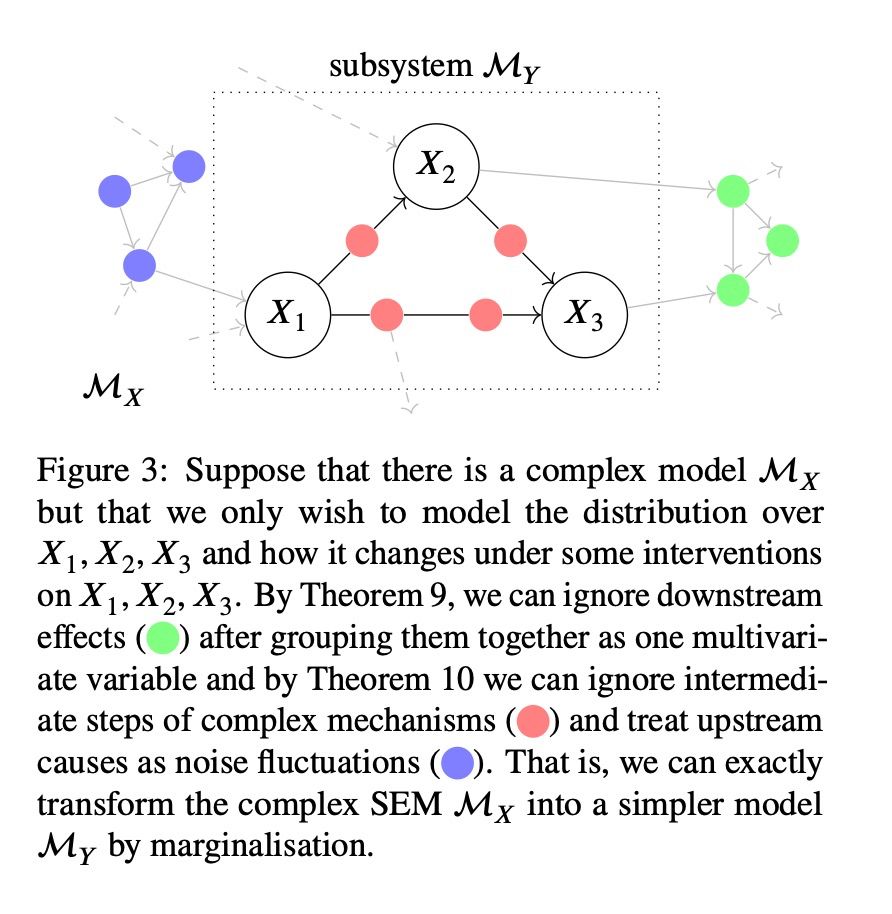
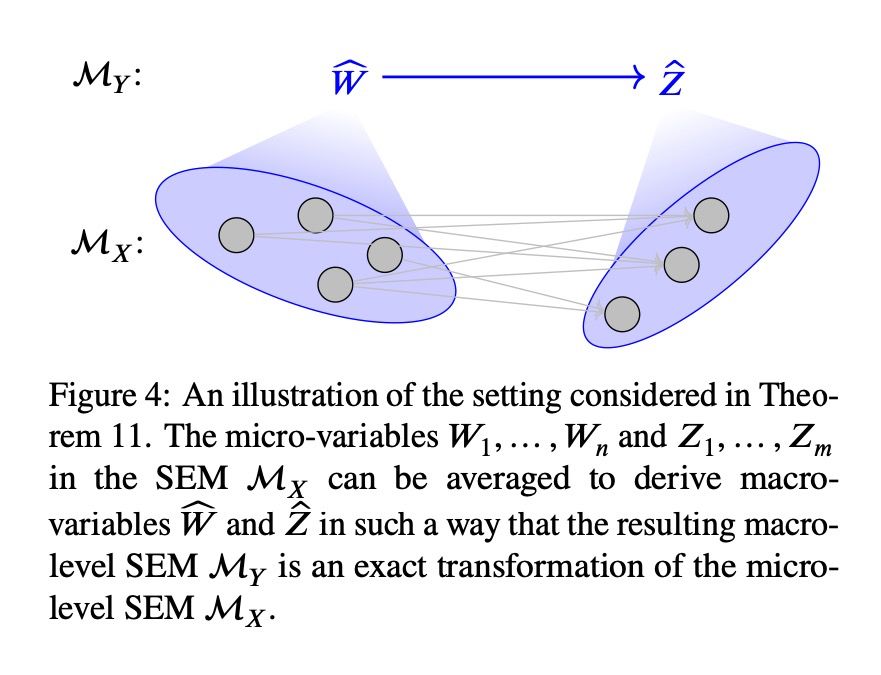
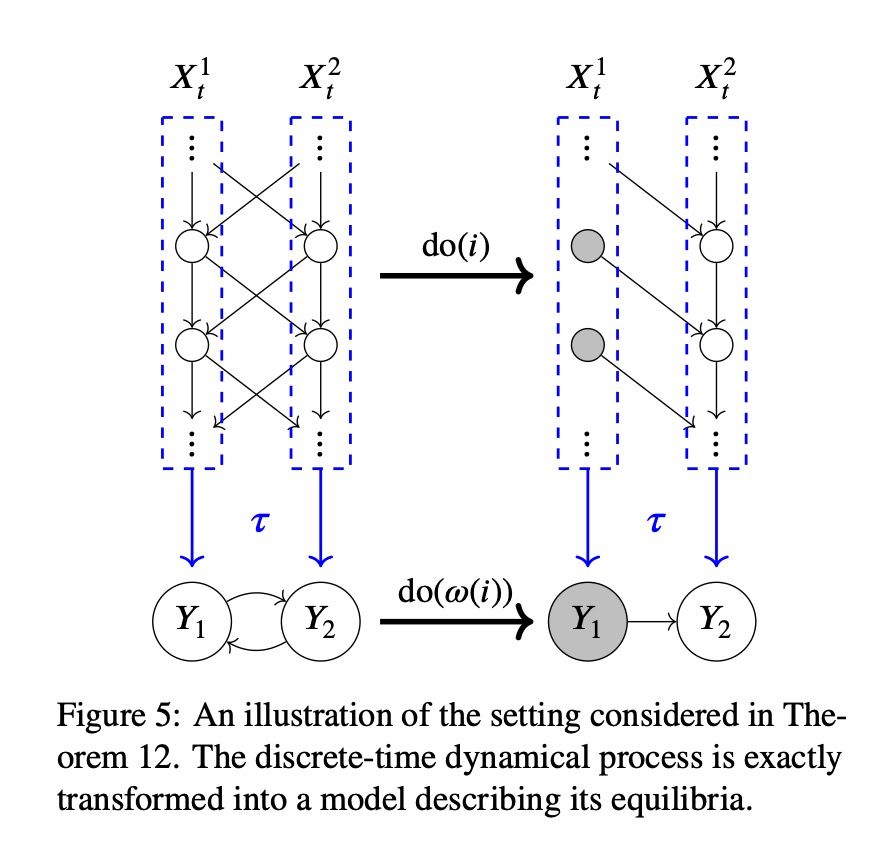
This is a fairly technical but highly relevant paper on how we can model complex systems at various levels of detail without losing causal content. Think gas: instead of tracking every molecule, we can focus on big-picture properties like temperature and pressure. www.auai.org/uai2017/proc...

July 8, 2025 at 9:30 AM
This is a fairly technical but highly relevant paper on how we can model complex systems at various levels of detail without losing causal content. Think gas: instead of tracking every molecule, we can focus on big-picture properties like temperature and pressure. www.auai.org/uai2017/proc...
Great to see this (cacm.acm.org/practice/sys...) from @marcbrooker.bsky.social
My experience is that LLMs make using TLA+ much easier. For instance, I just wrote up a bug report last week that outlined the old/buggy behavior with a TLA+ spec. It made the dynamics much clearer.
My experience is that LLMs make using TLA+ much easier. For instance, I just wrote up a bug report last week that outlined the old/buggy behavior with a TLA+ spec. It made the dynamics much clearer.
Systems Correctness Practices at Amazon Web Services – Communications of the ACM
cacm.acm.org
May 30, 2025 at 1:57 PM
Great to see this (cacm.acm.org/practice/sys...) from @marcbrooker.bsky.social
My experience is that LLMs make using TLA+ much easier. For instance, I just wrote up a bug report last week that outlined the old/buggy behavior with a TLA+ spec. It made the dynamics much clearer.
My experience is that LLMs make using TLA+ much easier. For instance, I just wrote up a bug report last week that outlined the old/buggy behavior with a TLA+ spec. It made the dynamics much clearer.
Interesting take that capped profit structure pushed insurance companies into self-dealing and reduced cost control incentive to maximize profit

Yes, UnitedHealth Group is a villain. A big and unique one. It’s under antitrust and legal assault, but we have to eliminate the policy mindset that created it and the rest of our murderous health system. www.thebignewsletter.com/p/its-time-t...

It's Time to Break Up Big Medicine
UnitedHealth Group is not an insurer, it's a platform. And it's in the crosshairs as Elizabeth Warren and Josh Hawley propose breaking it apart, severing its pharmacy arm from the rest of the business
www.thebignewsletter.com
December 13, 2024 at 2:28 PM
Interesting take that capped profit structure pushed insurance companies into self-dealing and reduced cost control incentive to maximize profit
Reposted by Michael Griffiths

An updated intro to reinforcement learning by Kevin Murphy: arxiv.org/abs/2412.05265! Like their books, it covers a lot and is quite up to date with modern approaches. It also is pretty unique in coverage, I don't think a lot of this is synthesized anywhere else yet

Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based met...
arxiv.org
December 9, 2024 at 2:27 PM
An updated intro to reinforcement learning by Kevin Murphy: arxiv.org/abs/2412.05265! Like their books, it covers a lot and is quite up to date with modern approaches. It also is pretty unique in coverage, I don't think a lot of this is synthesized anywhere else yet
How much money do we think means testing this is going to save? Like, how many ebike purchases would there have been for people making >3x poverty level?
December 8, 2024 at 2:37 AM
How much money do we think means testing this is going to save? Like, how many ebike purchases would there have been for people making >3x poverty level?
Nice to see alternatives to TLA+ pop up - this case study of Fizzbee makes it looks like a nice contender for certain use cases.

Diary entry 4 of my Kafka transactions formal verification work. This entry is all about the initial Fizzbee spec and some benchmarks comparing it to TLC (the TLA+ model checker).
jack-vanlightly.com/...
jack-vanlightly.com/...

Verifying Kafka transactions - Diary entry 4 - Writing an initial Fizzbee spec — Jack Vanlightly
I have written a Fizzbee spec that is the equivalent of the TLA+ spec.
Let’s dive into the decisions I had to make with this initial Fizzbee spec.
jack-vanlightly.com
December 5, 2024 at 5:41 PM
Nice to see alternatives to TLA+ pop up - this case study of Fizzbee makes it looks like a nice contender for certain use cases.

December 4, 2024 at 6:33 PM
Reposted by Michael Griffiths

Posting some evergreens for the new crowd. Did you now you can differentiate RANSAC?
If you fix the # of iterations, RANSAC is an argmax over hypotheses. You turn the inlier count into your policy for hypothesis selection, and train with policy gradient (DSAC, CVPR17).
github.com/vislearn/DSA...
If you fix the # of iterations, RANSAC is an argmax over hypotheses. You turn the inlier count into your policy for hypothesis selection, and train with policy gradient (DSAC, CVPR17).
github.com/vislearn/DSA...
November 28, 2024 at 3:42 PM
Posting some evergreens for the new crowd. Did you now you can differentiate RANSAC?
If you fix the # of iterations, RANSAC is an argmax over hypotheses. You turn the inlier count into your policy for hypothesis selection, and train with policy gradient (DSAC, CVPR17).
github.com/vislearn/DSA...
If you fix the # of iterations, RANSAC is an argmax over hypotheses. You turn the inlier count into your policy for hypothesis selection, and train with policy gradient (DSAC, CVPR17).
github.com/vislearn/DSA...
Reposted by Michael Griffiths

Yes! My quality of life foes way down when FRED doesn't have something and I have to try to extract it from Eurostat or the OECD. Or even BLS for things FRED doesn't pick up

nothing will make you appreciate FRED more than trying to use non-US public stats databases
November 28, 2024 at 11:57 AM
Yes! My quality of life foes way down when FRED doesn't have something and I have to try to extract it from Eurostat or the OECD. Or even BLS for things FRED doesn't pick up
Reposted by Michael Griffiths

NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
November 27, 2024 at 5:32 PM
NeurIPS Test of Time Awards:
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Generative Adversarial Nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le
Neat!

Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
November 28, 2024 at 12:36 AM
Neat!
Reposted by Michael Griffiths

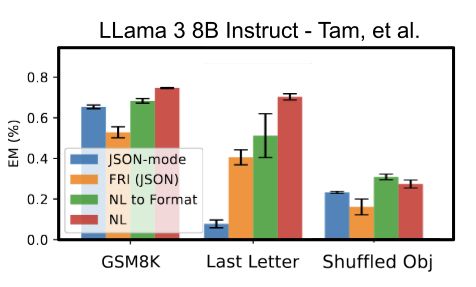
A new paper, "Let Me Speak Freely" has been spreading rumors that structured generation hurts LLM evaluation performance.
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
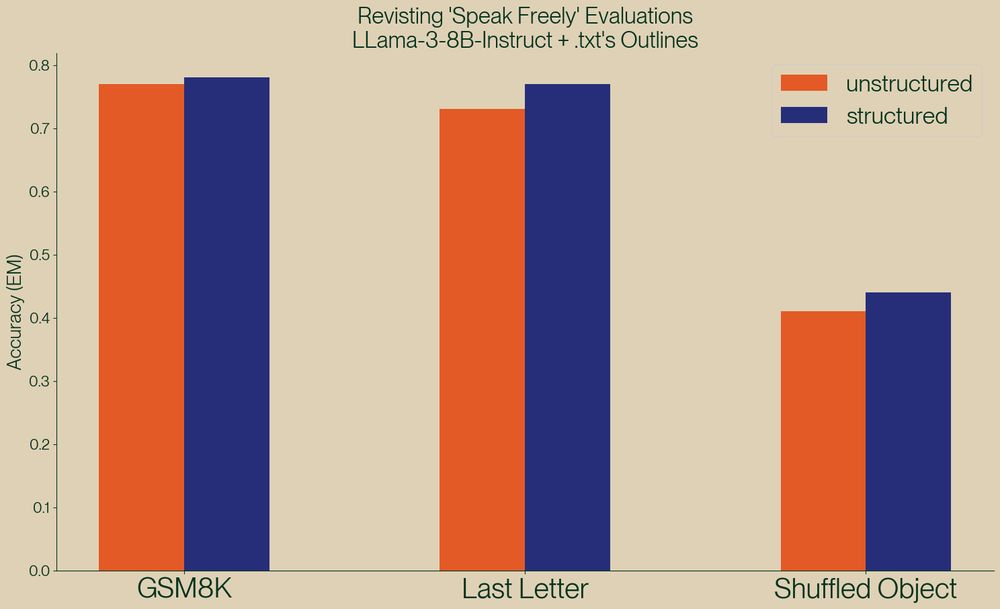
November 21, 2024 at 6:33 PM
A new paper, "Let Me Speak Freely" has been spreading rumors that structured generation hurts LLM evaluation performance.
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!
Well, we've taken a look and found serious issue in this paper, and shown, once again, that structured generation *improves* evaluation performance!