




Eric Brachmann
@ericbrachmann.bsky.social
Niantic Spatial, Research.
Throws machine learning at traditional computer vision pipelines to see what sticks. Differentiates the non-differentiable.
📍Europe 🔗 http://ebrach.github.io
Throws machine learning at traditional computer vision pipelines to see what sticks. Differentiates the non-differentiable.
📍Europe 🔗 http://ebrach.github.io
Pinned
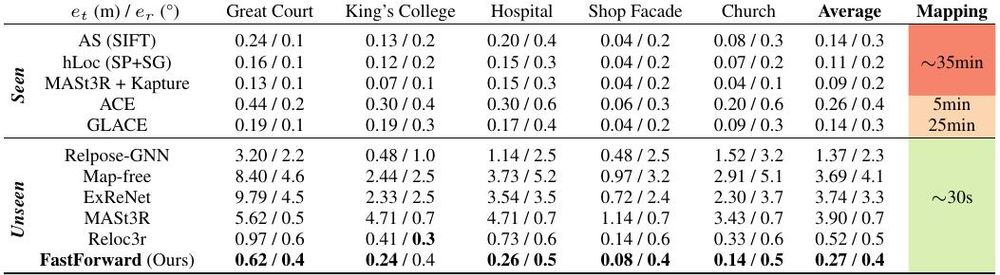
⏩ FastForward ⏩ A new model for efficient visual relocalization. Accurate camera poses without building structured 3D maps.
nianticspatial.github.io/fastforward/
Work by @axelbarroso.bsky.social, Tommaso Cavallari and Victor Adrian Prisacariu.
nianticspatial.github.io/fastforward/
Work by @axelbarroso.bsky.social, Tommaso Cavallari and Victor Adrian Prisacariu.
AC pro tip: When reading reviews, mentally substitute the "confidence" rating (low, medium, high) with "overconfidence", and everything is much better calibrated.
January 14, 2026 at 6:42 AM
AC pro tip: When reading reviews, mentally substitute the "confidence" rating (low, medium, high) with "overconfidence", and everything is much better calibrated.
What a nice morning to find that Alzugaray, Taher @marwantaher.bsky.social , Davison @ajdavison.bsky.social have turned ACE into a SLAM system. Since we did ACE, I was wondering whether it was possible, and I always thought who if not those folks can pull it off. 🙂
ACESLAM: arxiv.org/abs/2512.14032
ACESLAM: arxiv.org/abs/2512.14032
December 17, 2025 at 8:27 AM
What a nice morning to find that Alzugaray, Taher @marwantaher.bsky.social , Davison @ajdavison.bsky.social have turned ACE into a SLAM system. Since we did ACE, I was wondering whether it was possible, and I always thought who if not those folks can pull it off. 🙂
ACESLAM: arxiv.org/abs/2512.14032
ACESLAM: arxiv.org/abs/2512.14032
You know what season it is! Right. Internship application season.
Niantic Spatial is offering research internships on a multitude of 3D vision topics: relocalization, reconstruction, 3D VLMs... Top tier papers regularly come out of our internships 🚀
nianticspatial.careers.hibob.com/jobs/0fc4871...
Niantic Spatial is offering research internships on a multitude of 3D vision topics: relocalization, reconstruction, 3D VLMs... Top tier papers regularly come out of our internships 🚀
nianticspatial.careers.hibob.com/jobs/0fc4871...
Careers
nianticspatial.careers.hibob.com
December 10, 2025 at 8:38 AM
You know what season it is! Right. Internship application season.
Niantic Spatial is offering research internships on a multitude of 3D vision topics: relocalization, reconstruction, 3D VLMs... Top tier papers regularly come out of our internships 🚀
nianticspatial.careers.hibob.com/jobs/0fc4871...
Niantic Spatial is offering research internships on a multitude of 3D vision topics: relocalization, reconstruction, 3D VLMs... Top tier papers regularly come out of our internships 🚀
nianticspatial.careers.hibob.com/jobs/0fc4871...
Reposted by Eric Brachmann

Robotics researchers, this is an occasion not to be missed: top-notch speakers in an excellent location in the Alps this February 🤖⛷️
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇


December 8, 2025 at 9:56 AM
Robotics researchers, this is an occasion not to be missed: top-notch speakers in an excellent location in the Alps this February 🤖⛷️
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
It's the Winter School on Social Robotics, Artificial Intelligence and Multimedia (SoRAIM), 9-13 Feb 2026 👇
Ah, Warner Bros. buys Netflix. ... Wait, what?
December 5, 2025 at 3:45 PM
Ah, Warner Bros. buys Netflix. ... Wait, what?
CMT right now.

a man is holding a cup of coffee in his hand and drinking it .
ALT: a man is holding a cup of coffee in his hand and drinking it .
media.tenor.com
November 28, 2025 at 3:22 PM
CMT right now.
Recording of the 10th R6D workshop #ICCV2025 w/ results of the 2025 BOP challenge is out:
youtu.be/NymS-f4DNh0
3.5h of goodness dedicated to robot-object manipulation w/ Hao-Shu Fang (MIT), Maximilian Durner (DLR), Agastya Kalra+Vahe Taamazyan (Intrinsic) and Sergey Levine (Physical Intelligence)
youtu.be/NymS-f4DNh0
3.5h of goodness dedicated to robot-object manipulation w/ Hao-Shu Fang (MIT), Maximilian Durner (DLR), Agastya Kalra+Vahe Taamazyan (Intrinsic) and Sergey Levine (Physical Intelligence)

2738 Final 10th International Workshop on Recovering 6D Object Pose
YouTube video by ComputerVisionFoundation Videos
youtu.be
November 24, 2025 at 12:02 PM
Recording of the 10th R6D workshop #ICCV2025 w/ results of the 2025 BOP challenge is out:
youtu.be/NymS-f4DNh0
3.5h of goodness dedicated to robot-object manipulation w/ Hao-Shu Fang (MIT), Maximilian Durner (DLR), Agastya Kalra+Vahe Taamazyan (Intrinsic) and Sergey Levine (Physical Intelligence)
youtu.be/NymS-f4DNh0
3.5h of goodness dedicated to robot-object manipulation w/ Hao-Shu Fang (MIT), Maximilian Durner (DLR), Agastya Kalra+Vahe Taamazyan (Intrinsic) and Sergey Levine (Physical Intelligence)
Of all my multiple Lufthansa flights on this journey, the only one that was punctual was the one with a short connection time, and that I therefore missed due to the previous one being late.
Now, after one involuntary overnight stay: delay again. Great job @lufthansagroup.bsky.social
Now, after one involuntary overnight stay: delay again. Great job @lufthansagroup.bsky.social
November 22, 2025 at 7:49 AM
Of all my multiple Lufthansa flights on this journey, the only one that was punctual was the one with a short connection time, and that I therefore missed due to the previous one being late.
Now, after one involuntary overnight stay: delay again. Great job @lufthansagroup.bsky.social
Now, after one involuntary overnight stay: delay again. Great job @lufthansagroup.bsky.social
Coarse plan for a 1-week rebuttal period:
day 1: read the reviews
day 2-6: calm down
day 7: write the rebuttal
day 1: read the reviews
day 2-6: calm down
day 7: write the rebuttal
November 13, 2025 at 8:22 AM
Coarse plan for a 1-week rebuttal period:
day 1: read the reviews
day 2-6: calm down
day 7: write the rebuttal
day 1: read the reviews
day 2-6: calm down
day 7: write the rebuttal
‼️ Major update to the #ACEZero code base. We added the capabilities of the #ICCV2025 paper on Scene Coordinate Reconstruction Priors.
Gives you, e.g., a RGB-D version of ACE0. In the snipped below, I jointly reconstruct multiple RGB-D scans of ScanNet.
github.com/nianticlabs/...
Gives you, e.g., a RGB-D version of ACE0. In the snipped below, I jointly reconstruct multiple RGB-D scans of ScanNet.
github.com/nianticlabs/...
November 10, 2025 at 9:49 AM
‼️ Major update to the #ACEZero code base. We added the capabilities of the #ICCV2025 paper on Scene Coordinate Reconstruction Priors.
Gives you, e.g., a RGB-D version of ACE0. In the snipped below, I jointly reconstruct multiple RGB-D scans of ScanNet.
github.com/nianticlabs/...
Gives you, e.g., a RGB-D version of ACE0. In the snipped below, I jointly reconstruct multiple RGB-D scans of ScanNet.
github.com/nianticlabs/...
Code is out. We provide the pre-trained ACE-G model, as well as code to replicate the paper results, and to evaluate ACE-G on new scenes. #ICCV2025
github.com/nianticspati...
github.com/nianticspati...
November 5, 2025 at 2:39 PM
Code is out. We provide the pre-trained ACE-G model, as well as code to replicate the paper results, and to evaluate ACE-G on new scenes. #ICCV2025
github.com/nianticspati...
github.com/nianticspati...
Hi everyone. Can we please stop naming methods in leetspeak? It slows down my writing - it is a skill I happily abandoned 20 years ago.
November 4, 2025 at 11:19 AM
Hi everyone. Can we please stop naming methods in leetspeak? It slows down my writing - it is a skill I happily abandoned 20 years ago.
Reposted by Eric Brachmann

10th (!!) R6D workshop @ ICCV 2025:
cmp.felk.cvut.cz/sixd/worksho...
🤖 Object pose estimation for industrial robotics
📢 Speakers:
- Sergey Levine (UC Berkeley)
- Haoshu Fang (MIT)
- Maximilian Durner (DLR)
- Agastya Kalra & Vahe Taamazyan (Intrinsic)
📊 BOP 2025 with new BOP-Industrial datasets
cmp.felk.cvut.cz/sixd/worksho...
🤖 Object pose estimation for industrial robotics
📢 Speakers:
- Sergey Levine (UC Berkeley)
- Haoshu Fang (MIT)
- Maximilian Durner (DLR)
- Agastya Kalra & Vahe Taamazyan (Intrinsic)
📊 BOP 2025 with new BOP-Industrial datasets

October 17, 2025 at 4:01 PM
10th (!!) R6D workshop @ ICCV 2025:
cmp.felk.cvut.cz/sixd/worksho...
🤖 Object pose estimation for industrial robotics
📢 Speakers:
- Sergey Levine (UC Berkeley)
- Haoshu Fang (MIT)
- Maximilian Durner (DLR)
- Agastya Kalra & Vahe Taamazyan (Intrinsic)
📊 BOP 2025 with new BOP-Industrial datasets
cmp.felk.cvut.cz/sixd/worksho...
🤖 Object pose estimation for industrial robotics
📢 Speakers:
- Sergey Levine (UC Berkeley)
- Haoshu Fang (MIT)
- Maximilian Durner (DLR)
- Agastya Kalra & Vahe Taamazyan (Intrinsic)
📊 BOP 2025 with new BOP-Industrial datasets
After next week, I REALLY need a break from PowerPoint.
Looking forward to a busy #ICCV2025.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.

October 17, 2025 at 8:13 AM
After next week, I REALLY need a break from PowerPoint.
Looking forward to a busy #ICCV2025.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
October 17, 2025 at 8:11 AM
Looking forward to a busy #ICCV2025.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
I will give three (very different) talks at workshops and tutorials, see info below.
We also present two papers, ACE-G and SCR Priors.
And it's the 10th (!) anniversary of the R6D workshop, which we co-organize.
Reposted by Eric Brachmann

Bruns et al., "ACE-G: Improving Generalization of Scene Coordinate Regression Through Query Pre-Training"
Train a scene coordinate regressor with "map codes" (ie, trainable inputs) so that you can train one generalizable regressor. Then, find these "map codes" to localize.
Train a scene coordinate regressor with "map codes" (ie, trainable inputs) so that you can train one generalizable regressor. Then, find these "map codes" to localize.
October 16, 2025 at 7:37 PM
Bruns et al., "ACE-G: Improving Generalization of Scene Coordinate Regression Through Query Pre-Training"
Train a scene coordinate regressor with "map codes" (ie, trainable inputs) so that you can train one generalizable regressor. Then, find these "map codes" to localize.
Train a scene coordinate regressor with "map codes" (ie, trainable inputs) so that you can train one generalizable regressor. Then, find these "map codes" to localize.
Reposted by Eric Brachmann

Interested in doing a PhD in machine learning at the University of Edinburgh starting Sept 2026?
My group works on topics in vision, machine learning, and AI for climate.
For more information and details on how to get in touch, please check out my website:
homepages.inf.ed.ac.uk/omacaod
My group works on topics in vision, machine learning, and AI for climate.
For more information and details on how to get in touch, please check out my website:
homepages.inf.ed.ac.uk/omacaod

October 16, 2025 at 9:15 AM
Interested in doing a PhD in machine learning at the University of Edinburgh starting Sept 2026?
My group works on topics in vision, machine learning, and AI for climate.
For more information and details on how to get in touch, please check out my website:
homepages.inf.ed.ac.uk/omacaod
My group works on topics in vision, machine learning, and AI for climate.
For more information and details on how to get in touch, please check out my website:
homepages.inf.ed.ac.uk/omacaod
🌟 Scene Coordinate Reconstruction Priors at #ICCV2025 🌟
Can we learn what a successful reconstruction looks like, and use this knowledge when reconstructing new scenes?
Explainer: youtu.be/RkV6U5xYc20
Project Page: nianticspatial.github.io/scr-priors
Inspiring work by Wenjing Bian et al.!
Can we learn what a successful reconstruction looks like, and use this knowledge when reconstructing new scenes?
Explainer: youtu.be/RkV6U5xYc20
Project Page: nianticspatial.github.io/scr-priors
Inspiring work by Wenjing Bian et al.!
October 15, 2025 at 7:36 AM
🌟 Scene Coordinate Reconstruction Priors at #ICCV2025 🌟
Can we learn what a successful reconstruction looks like, and use this knowledge when reconstructing new scenes?
Explainer: youtu.be/RkV6U5xYc20
Project Page: nianticspatial.github.io/scr-priors
Inspiring work by Wenjing Bian et al.!
Can we learn what a successful reconstruction looks like, and use this knowledge when reconstructing new scenes?
Explainer: youtu.be/RkV6U5xYc20
Project Page: nianticspatial.github.io/scr-priors
Inspiring work by Wenjing Bian et al.!
Reposted by Eric Brachmann

The #ICCV2025 main conference open access proceedings is up:
openaccess.thecvf.com/ICCV2025
Workshop papers will be posted shortly. Aloha!
openaccess.thecvf.com/ICCV2025
Workshop papers will be posted shortly. Aloha!

October 14, 2025 at 7:42 PM
The #ICCV2025 main conference open access proceedings is up:
openaccess.thecvf.com/ICCV2025
Workshop papers will be posted shortly. Aloha!
openaccess.thecvf.com/ICCV2025
Workshop papers will be posted shortly. Aloha!
🔥 ACE-G, the next evolutionary step of ACE at #ICCV2025 🔥
We disentangle coordinate regression and latent map representation which lets us pre-train the regressor to generalize from mapping data to difficult query images.
Page: nianticspatial.github.io/ace-g/
Stellar work by Leonard Bruns et al.!
We disentangle coordinate regression and latent map representation which lets us pre-train the regressor to generalize from mapping data to difficult query images.
Page: nianticspatial.github.io/ace-g/
Stellar work by Leonard Bruns et al.!
October 14, 2025 at 8:24 AM
🔥 ACE-G, the next evolutionary step of ACE at #ICCV2025 🔥
We disentangle coordinate regression and latent map representation which lets us pre-train the regressor to generalize from mapping data to difficult query images.
Page: nianticspatial.github.io/ace-g/
Stellar work by Leonard Bruns et al.!
We disentangle coordinate regression and latent map representation which lets us pre-train the regressor to generalize from mapping data to difficult query images.
Page: nianticspatial.github.io/ace-g/
Stellar work by Leonard Bruns et al.!
When you present other peoples work with them sitting in the audience.

a man with sweat running down his face
ALT: a man with sweat running down his face
media.tenor.com
October 10, 2025 at 9:01 AM
When you present other peoples work with them sitting in the audience.
I think it is a great time to have such a tutorial again. As we see competitive RANSAC-free approaches arise, it is worth looking back - and looking forward.
For those going to @iccv.bsky.social, welcome to our RANSAC tutorial on October 2025 with
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025

October 8, 2025 at 11:26 AM
I think it is a great time to have such a tutorial again. As we see competitive RANSAC-free approaches arise, it is worth looking back - and looking forward.
Reposted by Eric Brachmann

For those going to @iccv.bsky.social, welcome to our RANSAC tutorial on October 2025 with
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025
October 8, 2025 at 11:22 AM
For those going to @iccv.bsky.social, welcome to our RANSAC tutorial on October 2025 with
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025
- Daniel Barath
- @ericbrachmann.bsky.social
- Viktor Larsson
- Jiri Matas
- and me
danini.github.io/ransac-2025-...
#ICCV2025
Whenever I do a voice over, I realize that I sound like Arnold Schwarzenegger when I say "coordinate". Unfortunately, in my line of work, I have to say "coordinate" a lot...
October 8, 2025 at 8:00 AM
Whenever I do a voice over, I realize that I sound like Arnold Schwarzenegger when I say "coordinate". Unfortunately, in my line of work, I have to say "coordinate" a lot...
Trendy.

𝗔 𝗦𝗰𝗲𝗻𝗲 𝗶𝘀 𝗪𝗼𝗿𝘁𝗵 𝗮 𝗧𝗵𝗼𝘂𝘀𝗮𝗻𝗱 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀: 𝗙𝗲𝗲𝗱-𝗙𝗼𝗿𝘄𝗮𝗿𝗱 𝗖𝗮𝗺𝗲𝗿𝗮 𝗟𝗼𝗰𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗮 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗼𝗳 𝗜𝗺𝗮𝗴𝗲 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀
Axel Barroso-Laguna, Tommaso Cavallari, Victor Adrian Prisacariu, Eric Brachmann
arxiv.org/abs/2510.00978
Trending on www.scholar-inbox.com
Axel Barroso-Laguna, Tommaso Cavallari, Victor Adrian Prisacariu, Eric Brachmann
arxiv.org/abs/2510.00978
Trending on www.scholar-inbox.com



October 3, 2025 at 8:40 AM
Trendy.