




Gokul Swamy
@gokul.dev
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
June 20, 2025 at 3:53 AM
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
I won't be at #ICLR2025 myself this time around but please go talk to lead authors Nico, Zhaolin, and Runzhe about their bleeding-edge algorithms for imitation learning and RLHF!

April 22, 2025 at 2:05 PM
I won't be at #ICLR2025 myself this time around but please go talk to lead authors Nico, Zhaolin, and Runzhe about their bleeding-edge algorithms for imitation learning and RLHF!
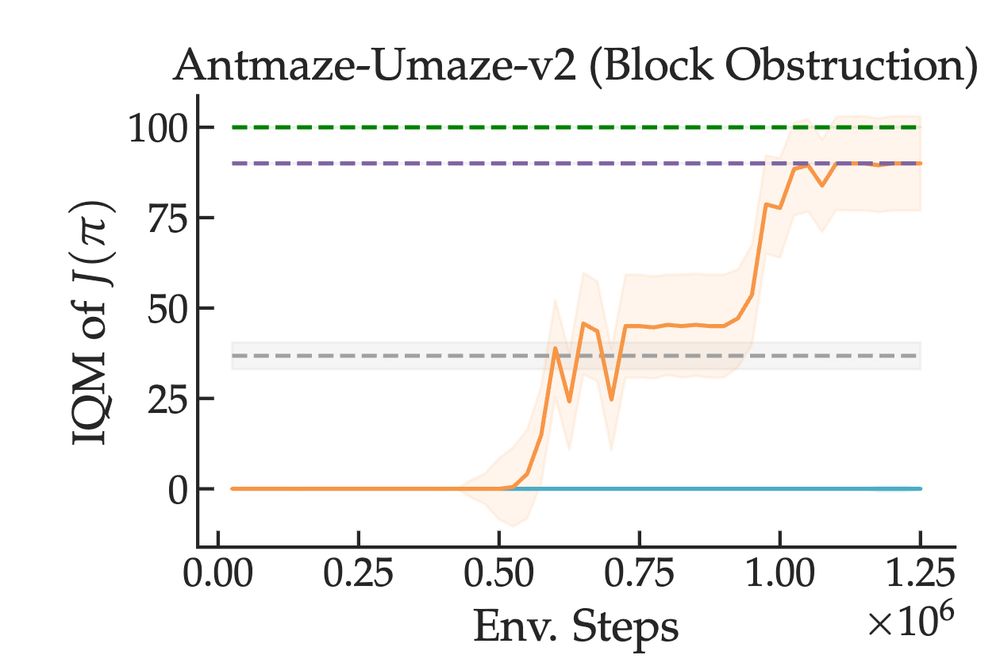
We then show that this sort of suboptimal, offline data can help significantly with speeding up local search on challenging maze-based exploration problems where the learner needs to act meaningfully different from the expert (our method in orange). [14/n]
April 7, 2025 at 7:03 PM
We then show that this sort of suboptimal, offline data can help significantly with speeding up local search on challenging maze-based exploration problems where the learner needs to act meaningfully different from the expert (our method in orange). [14/n]
Among our contributions, we give a precise (and rather aesthetically pleasingly typeset if I don't say so myself) theoretical condition under which the use of suboptimal data to help with figuring out *where* to locally search from is helps with policy performance! [13/n]

April 7, 2025 at 7:03 PM
Among our contributions, we give a precise (and rather aesthetically pleasingly typeset if I don't say so myself) theoretical condition under which the use of suboptimal data to help with figuring out *where* to locally search from is helps with policy performance! [13/n]
I think of misspecification (e.g. embodiment / sensory gaps) as the fundamental reason behavioral cloning isn't "all you need" for imitation as matching actions matching outcomes. Introducing @nico-espinosa-dice.bsky.social's #ICLR2025 paper proving that "local search" *is* all you need! [1/n]

April 7, 2025 at 7:03 PM
I think of misspecification (e.g. embodiment / sensory gaps) as the fundamental reason behavioral cloning isn't "all you need" for imitation as matching actions matching outcomes. Introducing @nico-espinosa-dice.bsky.social's #ICLR2025 paper proving that "local search" *is* all you need! [1/n]
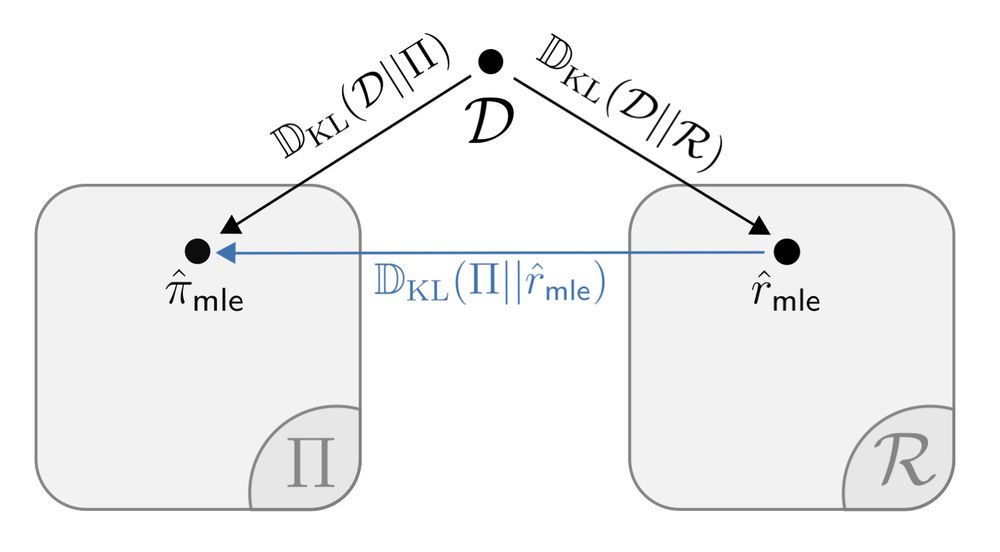
In fact, we can prove that under idealized assumptions, DPO/MLE and on-policy RLHF should produce *exactly* the same policy when policy / reward classes are isomorphic. Intuitively, this is because MLE is *invariant* to reparameterization. [6/n]
March 4, 2025 at 8:59 PM
In fact, we can prove that under idealized assumptions, DPO/MLE and on-policy RLHF should produce *exactly* the same policy when policy / reward classes are isomorphic. Intuitively, this is because MLE is *invariant* to reparameterization. [6/n]
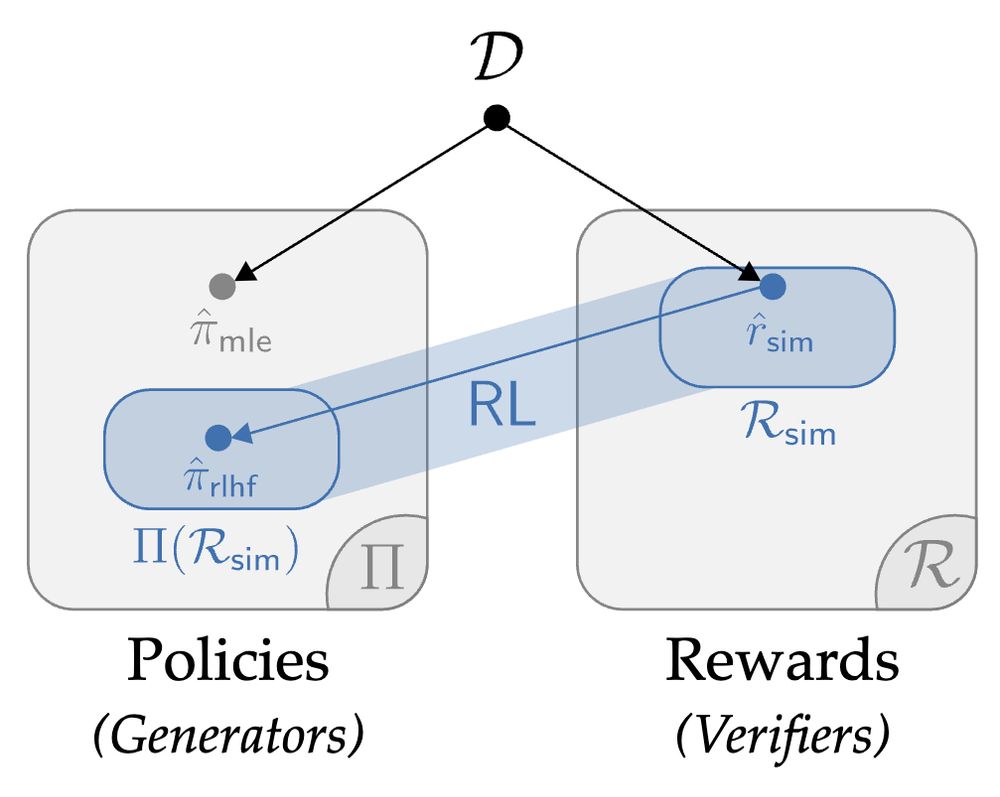
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
March 4, 2025 at 8:59 PM
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
new h-index final boss just dropped 😭😭😭: scholar.google.com/citations?hl...

February 23, 2025 at 1:55 AM
new h-index final boss just dropped 😭😭😭: scholar.google.com/citations?hl...