




Gokul Swamy
@gokul.dev
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
Pinned
Gokul Swamy
@gokul.dev
· Mar 6
I was lucky enough to be invited give a talk on our new paper on the value of RL in fine-tuning at Cornell last week! Because of my poor time management skills, the talk isn't as polished as I'd like, but I think the "vibes" are accurate enough to share: youtu.be/E4b3cSirpsg.
Reposted by Gokul Swamy

Our paper on algorithmic collusion was featured in a Quanta article! www.quantamagazine.org/the-game-the...

The Game Theory of How Algorithms Can Drive Up Prices | Quanta Magazine
Recent findings reveal that even simple pricing algorithms can make things more expensive.
www.quantamagazine.org
October 22, 2025 at 3:19 PM
Our paper on algorithmic collusion was featured in a Quanta article! www.quantamagazine.org/the-game-the...
Just discovered this lovely talk from my favorite professor from undergrad, who is still as inspiring as I remember him:
www.youtube.com/watch?v=XLZ0...
www.youtube.com/watch?v=XLZ0...

“Raising Our Sights (A Long Rant From an Accidental Engineer)”, Scott Shenker
YouTube video by Plamadiso - Platforms, Markets & Digital Society
www.youtube.com
October 22, 2025 at 2:30 AM
Just discovered this lovely talk from my favorite professor from undergrad, who is still as inspiring as I remember him:
www.youtube.com/watch?v=XLZ0...
www.youtube.com/watch?v=XLZ0...
Please apply or help out!
Queer in AI and oSTEM are launching our 2025 Grad School Application Mentorship program! Queer graduate school applicants, you can apply at openreview.net/group?id=Que... to get feedback on your application materials (e.g., CV, personal statement, etc). More info @ www.queerinai.com/grad-app-aid 1/3
QueerInAI 2024 Grad Mentor
Welcome to the OpenReview homepage for QueerInAI 2024 Grad Mentor
openreview.net
October 13, 2025 at 12:36 AM
Please apply or help out!
Late, but arxiv.org/abs/0804.2996 is *incredible*, so many good lines (e.g., "This comes close to being an accusation of a false claim of priority for a false discovery of an untrue fact, which would be a rare triple-negative in the history of intellectual property disputes.").

The Epic Story of Maximum Likelihood
At a superficial level, the idea of maximum likelihood must be prehistoric: early hunters and gatherers may not have used the words ``method of maximum likelihood'' to describe their choice of where a...
arxiv.org
September 28, 2025 at 9:13 PM
Late, but arxiv.org/abs/0804.2996 is *incredible*, so many good lines (e.g., "This comes close to being an accusation of a false claim of priority for a false discovery of an untrue fact, which would be a rare triple-negative in the history of intellectual property disputes.").
Recent work has seemed somewhat magical: how can RL with *random* rewards make LLMs reason? We pull back the curtain on these claims and find out this unexpected behavior hinges on the inclusion of certain *heuristics* in the RL algorithm. Our blog post: tinyurl.com/heuristics-c...

Heuristics Considered Harmful: RL With Random Rewards Should Not Make LLMs Reason | Notion
Owen Oertell*, Wenhao Zhao*, Gokul Swamy, Zhiwei Steven Wu, Kiante Brantley, Jason Lee, Wen Sun
tinyurl.com
July 15, 2025 at 5:46 PM
Recent work has seemed somewhat magical: how can RL with *random* rewards make LLMs reason? We pull back the curtain on these claims and find out this unexpected behavior hinges on the inclusion of certain *heuristics* in the RL algorithm. Our blog post: tinyurl.com/heuristics-c...
Reposted by Gokul Swamy

very nice lectures, watch them from time to time
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
June 20, 2025 at 6:07 AM
very nice lectures, watch them from time to time
Reposted by Gokul Swamy

Want to learn about online learning, game solving, RL, imitation learning with applications to robotics, and RLHF with applications to language modeling? Check out this course! 👍
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
June 20, 2025 at 1:11 PM
Want to learn about online learning, game solving, RL, imitation learning with applications to robotics, and RLHF with applications to language modeling? Check out this course! 👍
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
June 20, 2025 at 3:53 AM
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
Shortcut models enable scaling offline RL, both at train-time at test-time! We beat so many other algorithms on so many tasks we had to stick most of the results in the appendix 😅. Very proud of @nico-espinosa-dice.bsky.social for spearheading this project, check out his thread!

by incorporating self-consistency during offline RL training, we unlock three orthogonal directions of scaling:
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)
1. efficient training (i.e. limit backprop through time)
2. expressive model classes (e.g. flow matching)
3. inference-time scaling (sequential and parallel)

June 12, 2025 at 11:14 PM
Shortcut models enable scaling offline RL, both at train-time at test-time! We beat so many other algorithms on so many tasks we had to stick most of the results in the appendix 😅. Very proud of @nico-espinosa-dice.bsky.social for spearheading this project, check out his thread!
Boston friends: I'll be in the Cambridge area for the next few days, shoot me a message if you'd like to catch up :).
April 27, 2025 at 9:28 PM
Boston friends: I'll be in the Cambridge area for the next few days, shoot me a message if you'd like to catch up :).
I won't be at #ICLR2025 myself this time around but please go talk to lead authors Nico, Zhaolin, and Runzhe about their bleeding-edge algorithms for imitation learning and RLHF!

April 22, 2025 at 2:05 PM
I won't be at #ICLR2025 myself this time around but please go talk to lead authors Nico, Zhaolin, and Runzhe about their bleeding-edge algorithms for imitation learning and RLHF!
I think of misspecification (e.g. embodiment / sensory gaps) as the fundamental reason behavioral cloning isn't "all you need" for imitation as matching actions matching outcomes. Introducing @nico-espinosa-dice.bsky.social's #ICLR2025 paper proving that "local search" *is* all you need! [1/n]

April 7, 2025 at 7:03 PM
I think of misspecification (e.g. embodiment / sensory gaps) as the fundamental reason behavioral cloning isn't "all you need" for imitation as matching actions matching outcomes. Introducing @nico-espinosa-dice.bsky.social's #ICLR2025 paper proving that "local search" *is* all you need! [1/n]
I was lucky enough to be invited give a talk on our new paper on the value of RL in fine-tuning at Cornell last week! Because of my poor time management skills, the talk isn't as polished as I'd like, but I think the "vibes" are accurate enough to share: youtu.be/E4b3cSirpsg.
March 6, 2025 at 6:19 PM
I was lucky enough to be invited give a talk on our new paper on the value of RL in fine-tuning at Cornell last week! Because of my poor time management skills, the talk isn't as polished as I'd like, but I think the "vibes" are accurate enough to share: youtu.be/E4b3cSirpsg.
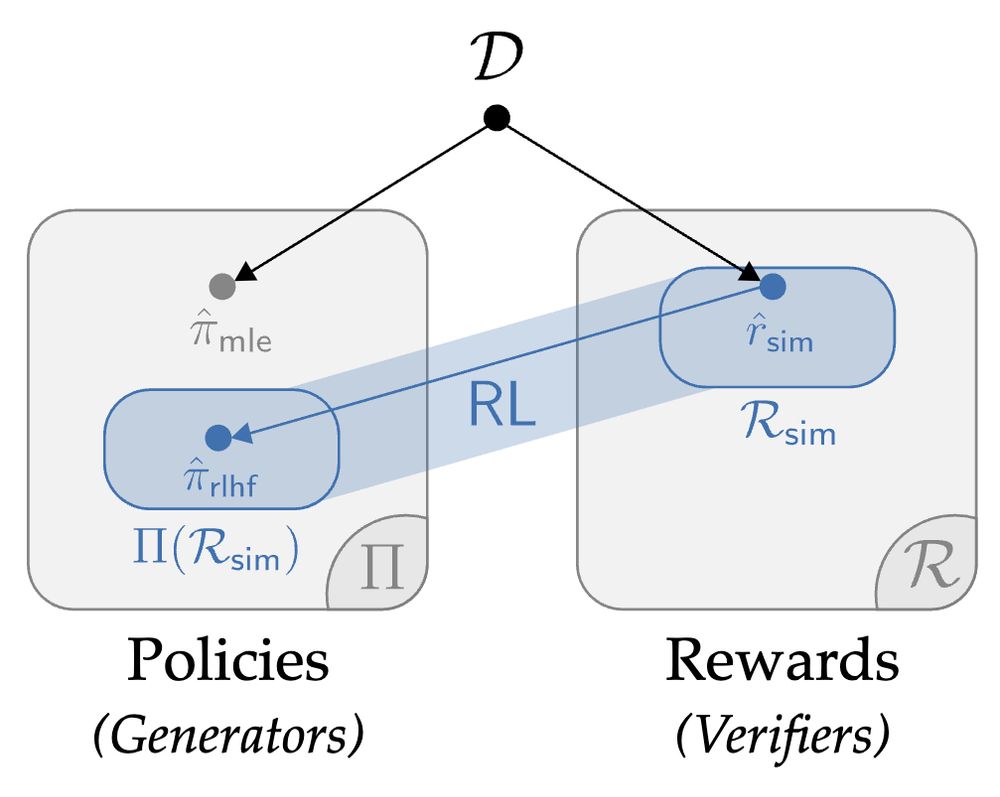
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
March 4, 2025 at 8:59 PM
1.5 yrs ago, we set out to answer a seemingly simple question: what are we *actually* getting out of RL in fine-tuning? I'm thrilled to share a pearl we found on the deepest dive of my PhD: the value of RL in RLHF seems to come from *generation-verification gaps*. Get ready to 🤿:
new h-index final boss just dropped 😭😭😭: scholar.google.com/citations?hl...

February 23, 2025 at 1:55 AM
new h-index final boss just dropped 😭😭😭: scholar.google.com/citations?hl...
Reposted by Gokul Swamy

A large group of us (spearheaded by Denizalp Goktas) have put out a position paper on paths towards foundation models for strategic decision-making. Language models still lack these capabilities so we'll need to build them: hal.science/hal-04925309...

February 18, 2025 at 6:33 PM
A large group of us (spearheaded by Denizalp Goktas) have put out a position paper on paths towards foundation models for strategic decision-making. Language models still lack these capabilities so we'll need to build them: hal.science/hal-04925309...
3/3 for #ICLR2025! Huge congratulations to lead authors Nico Espinosa-Dice, Zhaolin Gao, Runzhe Wu -- all students of the wonderful Wen Sun! I'll save a more in depth discussion of the papers for later but if you'd like a sneak peak, check out arxiv.org/abs/2410.13855 and arxiv.org/abs/2410.04612!

Diffusing States and Matching Scores: A New Framework for Imitation Learning
Adversarial Imitation Learning is traditionally framed as a two-player zero-sum game between a learner and an adversarially chosen cost function, and can therefore be thought of as the sequential gene...
arxiv.org
January 22, 2025 at 5:39 PM
3/3 for #ICLR2025! Huge congratulations to lead authors Nico Espinosa-Dice, Zhaolin Gao, Runzhe Wu -- all students of the wonderful Wen Sun! I'll save a more in depth discussion of the papers for later but if you'd like a sneak peak, check out arxiv.org/abs/2410.13855 and arxiv.org/abs/2410.04612!
Reposted by Gokul Swamy
My actual favorite niche starter pack here:
go.bsky.app/2Gibu1a
go.bsky.app/2Gibu1a
January 20, 2025 at 8:17 PM
My actual favorite niche starter pack here:
go.bsky.app/2Gibu1a
go.bsky.app/2Gibu1a
Lynch was perhaps my favorite director: it was like he lifted Murakami to the silver screen. His work had enough surrealism that his message stuck, but not so much that it was hidden. To quote my favorite Twin Peaks episode: "this is the water and this is the well, drink full and descend." RIP.

David Lynch, Visionary Director of ‘Twin Peaks’ and ‘Blue Velvet,’ Dies at 78
Director David Lynch, who radicalized American film with with a dark, surrealistic artistic vision in films like 'Blue Velvet,' has died. He was 78.
variety.com
January 16, 2025 at 10:58 PM
Lynch was perhaps my favorite director: it was like he lifted Murakami to the silver screen. His work had enough surrealism that his message stuck, but not so much that it was hidden. To quote my favorite Twin Peaks episode: "this is the water and this is the well, drink full and descend." RIP.
Congrats to my ever-amazing undergrad Juntao Ren (who is far too productive to be on here) for being named a Runner Up for the 2025 CRA Outstanding Undergraduate Researcher Award (cra.org/about/awards...)! He's on the PhD Job Market this year and I can't say enough good things about him!
January 2, 2025 at 10:52 PM
Congrats to my ever-amazing undergrad Juntao Ren (who is far too productive to be on here) for being named a Runner Up for the 2025 CRA Outstanding Undergraduate Researcher Award (cra.org/about/awards...)! He's on the PhD Job Market this year and I can't say enough good things about him!
The more time I spend on RLHF, the more I realize the devil is in the details (even more than RL for continuous control). My co-author Zhaolin Gao wrote this excellent blog post on some of these details: huggingface.co/blog/GitBag/.... Maybe it'll be your savior!

RLHF 101: A Technical Dive into RLHF
A Blog post by Zhaolin Gao on Hugging Face
huggingface.co
December 11, 2024 at 8:05 PM
The more time I spend on RLHF, the more I realize the devil is in the details (even more than RL for continuous control). My co-author Zhaolin Gao wrote this excellent blog post on some of these details: huggingface.co/blog/GitBag/.... Maybe it'll be your savior!
Reposted by Gokul Swamy

If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
December 10, 2024 at 9:55 PM
If you're at NeurIPS, RLC is hosting an RL event from 8 till late at The Pearl on Dec. 11th. Join us, meet all the RL researchers, and spread the word!
Reposted by Gokul Swamy

I will present two papers at #NeurIPS2024!
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
NeurIPS Poster The Importance of Online Data: Understanding Preference Fine-tuning via CoverageNeurIPS 2024
neurips.cc
December 9, 2024 at 7:49 PM
I will present two papers at #NeurIPS2024!
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
Happy to meet old and new friends and talk about all aspects of RL: data, environment structure, and reward! 😀
In Wed 11am-2pm poster session I will present HyPO-- best of both worlds of offline and online RLHF: neurips.cc/virtual/2024...
Reposted by Gokul Swamy

Excited to be at NeurIPS'24, where I'll be presenting at several workshops! Looking forward to chatting about (time series & tabular) foundation models, data science agents, or ML for healthcare!
Also, I'm also on the industry job market, looking forward to connect 😁!
Also, I'm also on the industry job market, looking forward to connect 😁!

December 9, 2024 at 3:25 AM
Excited to be at NeurIPS'24, where I'll be presenting at several workshops! Looking forward to chatting about (time series & tabular) foundation models, data science agents, or ML for healthcare!
Also, I'm also on the industry job market, looking forward to connect 😁!
Also, I'm also on the industry job market, looking forward to connect 😁!
I won't be at #NeurIPS2024 this year but some brilliant folks I work with will be presenting some really cool work on imitation learning and RLHF. Please stop by and check out their posters! Quick links to papers:
arxiv.org/abs/2406.04219, arxiv.org/abs/2406.01462,
arxiv.org/abs/2404.16767.
arxiv.org/abs/2406.04219, arxiv.org/abs/2406.01462,
arxiv.org/abs/2404.16767.
December 8, 2024 at 3:54 PM
I won't be at #NeurIPS2024 this year but some brilliant folks I work with will be presenting some really cool work on imitation learning and RLHF. Please stop by and check out their posters! Quick links to papers:
arxiv.org/abs/2406.04219, arxiv.org/abs/2406.01462,
arxiv.org/abs/2404.16767.
arxiv.org/abs/2406.04219, arxiv.org/abs/2406.01462,
arxiv.org/abs/2404.16767.