



vLLM Blog Alert! vLLM introduces PTPC-FP8 quantization on AMD ROCm, delivering near-BF16 accuracy at FP8 speeds. Run LLMs faster on @AMD MI300X GPUs – no pre-quantization required!
Get started: pip install -U vllm, add --quantization ptpc_fp8.
Full details: blog.vllm.ai/2025/02/24/p...
[1/2]
Get started: pip install -U vllm, add --quantization ptpc_fp8.
Full details: blog.vllm.ai/2025/02/24/p...
[1/2]

PTPC-FP8: Boosting vLLM Performance on AMD ROCm
TL;DR: vLLM on AMD ROCm now has better FP8 performance!
blog.vllm.ai
March 22, 2025 at 11:47 AM
vLLM Blog Alert! vLLM introduces PTPC-FP8 quantization on AMD ROCm, delivering near-BF16 accuracy at FP8 speeds. Run LLMs faster on @AMD MI300X GPUs – no pre-quantization required!
Get started: pip install -U vllm, add --quantization ptpc_fp8.
Full details: blog.vllm.ai/2025/02/24/p...
[1/2]
Get started: pip install -U vllm, add --quantization ptpc_fp8.
Full details: blog.vllm.ai/2025/02/24/p...
[1/2]
Recap 2024, we've embraced open-source, contributing to vLLM with 211 PRs, 65K+ LOC, and expanded VLM support. Launched #JamAIBase, an AI spreadsheet with 620+ stars, and on 🤗 we have 1.75M+. Collaborated with Liger Kernel & infinity for AMD GPU support. Let's make 2025 even more impactful together!

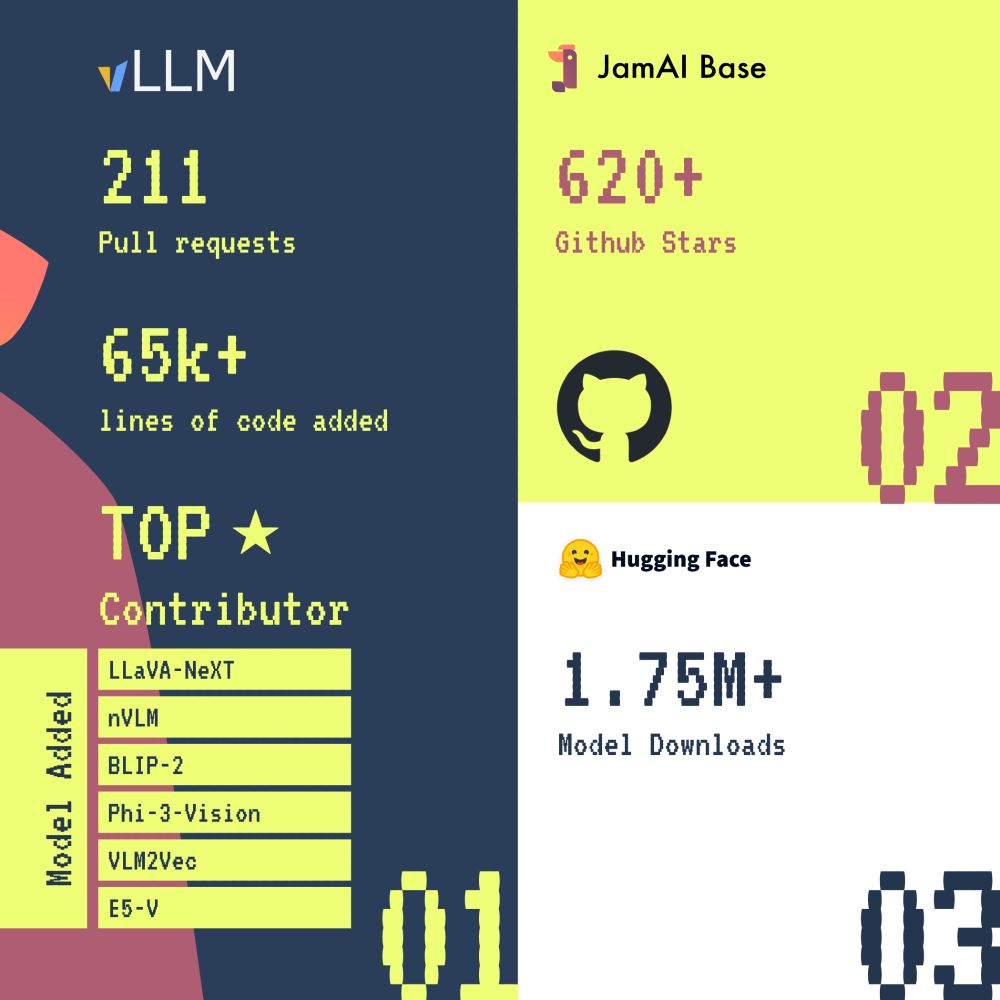
December 30, 2024 at 4:01 PM
Recap 2024, we've embraced open-source, contributing to vLLM with 211 PRs, 65K+ LOC, and expanded VLM support. Launched #JamAIBase, an AI spreadsheet with 620+ stars, and on 🤗 we have 1.75M+. Collaborated with Liger Kernel & infinity for AMD GPU support. Let's make 2025 even more impactful together!
🚀 Liger-Kernel is making waves! Check out the latest LinkedIn Eng blog post on how Liger improve #LLM training efficiency with Triton kernels.
20% throughput boost & 60% memory reduction for models like Llama, Gemma & Qwen with just one line of code! Works on AMD!
www.linkedin.com/blog/enginee...
20% throughput boost & 60% memory reduction for models like Llama, Gemma & Qwen with just one line of code! Works on AMD!
www.linkedin.com/blog/enginee...

Liger-Kernel: Empowering an open source ecosystem of Triton Kernels for Efficient LLM Training
www.linkedin.com
December 6, 2024 at 2:26 AM
🚀 Liger-Kernel is making waves! Check out the latest LinkedIn Eng blog post on how Liger improve #LLM training efficiency with Triton kernels.
20% throughput boost & 60% memory reduction for models like Llama, Gemma & Qwen with just one line of code! Works on AMD!
www.linkedin.com/blog/enginee...
20% throughput boost & 60% memory reduction for models like Llama, Gemma & Qwen with just one line of code! Works on AMD!
www.linkedin.com/blog/enginee...
🔥 Big thanks to Michael Feil for the epic collab on supercharging embedding & reranking on AMD GPUs with Infinity♾!
Check out the guide on 🤗 Hugging Face for how to leverage this high throughput embedding inference engine!
huggingface.co/blog/michael...
Check out the guide on 🤗 Hugging Face for how to leverage this high throughput embedding inference engine!
huggingface.co/blog/michael...

Accelerating Embedding & Reranking Models on AMD Using Infinity
A Blog post by Michael on Hugging Face
huggingface.co
December 4, 2024 at 2:16 PM
🔥 Big thanks to Michael Feil for the epic collab on supercharging embedding & reranking on AMD GPUs with Infinity♾!
Check out the guide on 🤗 Hugging Face for how to leverage this high throughput embedding inference engine!
huggingface.co/blog/michael...
Check out the guide on 🤗 Hugging Face for how to leverage this high throughput embedding inference engine!
huggingface.co/blog/michael...
vLLM now supports running GGUF models on AMD Radeon GPUs, with impressive performance on RX 7900XTX. Outperforms Ollama at batch size 1, with 62.66 tok/s vs 58.05 tok/s.
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
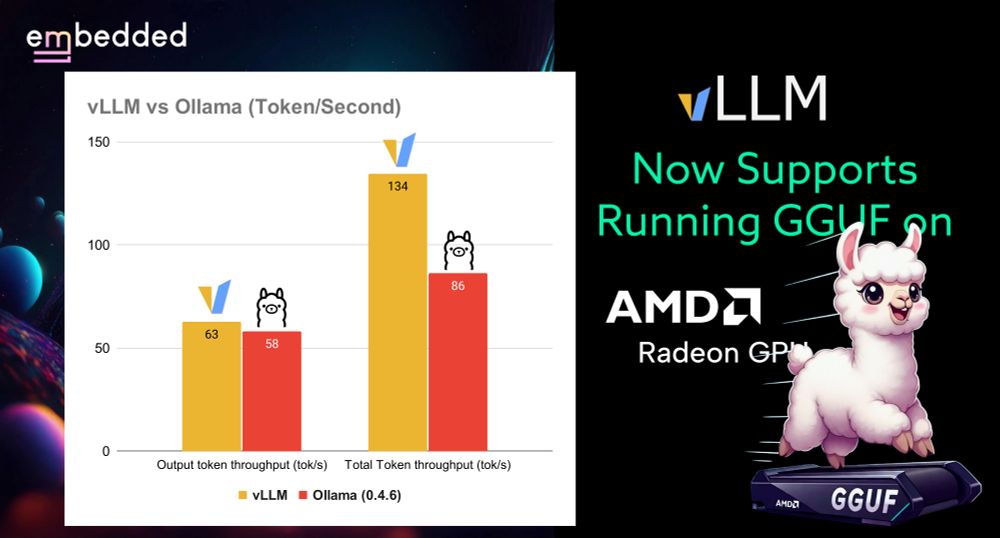
December 2, 2024 at 3:47 AM
vLLM now supports running GGUF models on AMD Radeon GPUs, with impressive performance on RX 7900XTX. Outperforms Ollama at batch size 1, with 62.66 tok/s vs 58.05 tok/s.
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
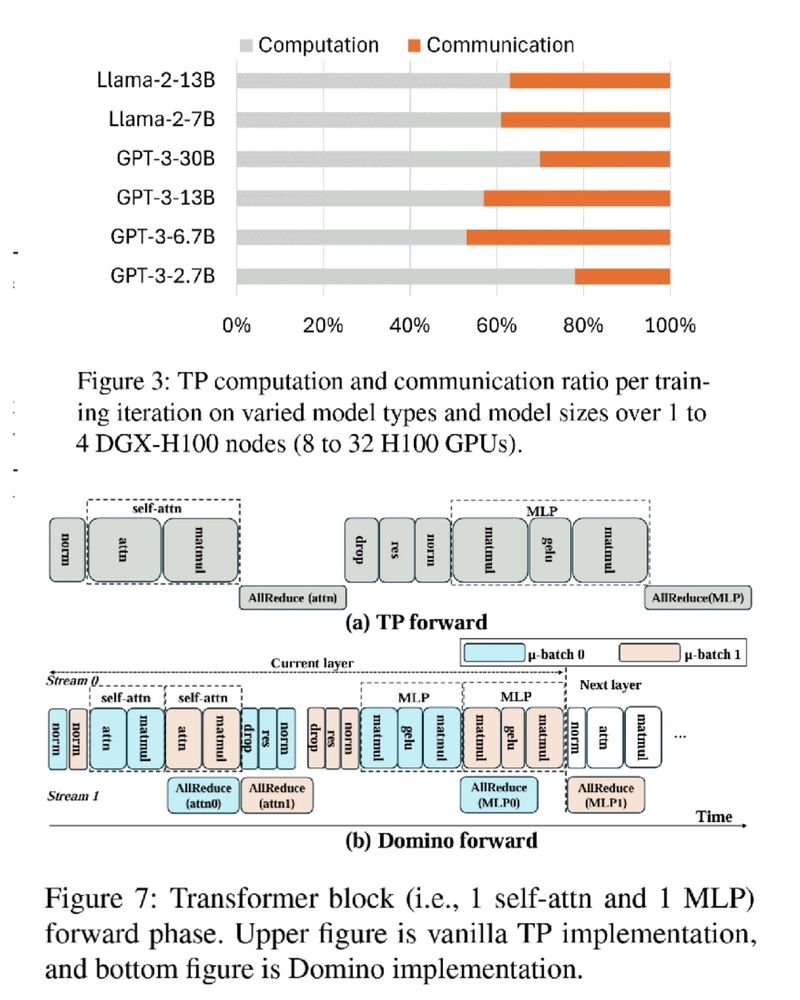
November 26, 2024 at 2:35 PM
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
Liger Kernels v0.4.0 ROARS onto AMD GPUs! 🚀 Faster LLM training, less memory, LONGER context lengths! Check out the benchmarks! embeddedllm.com/blog/cuda-to...
@hotaisle.bsky.social
@hotaisle.bsky.social

Liger Kernels Leap the CUDA Moat: A Case Study with Liger, LinkedIn's SOTA Training Kernels on AMD GPU
This guide shows the impact of Liger-Kernels Training Kernels on AMD MI300X. The build has been verified for ROCm 6.2.
embeddedllm.com
November 24, 2024 at 10:53 AM
Liger Kernels v0.4.0 ROARS onto AMD GPUs! 🚀 Faster LLM training, less memory, LONGER context lengths! Check out the benchmarks! embeddedllm.com/blog/cuda-to...
@hotaisle.bsky.social
@hotaisle.bsky.social
🔥 Pixtral Large is now supported on vLLM! 🔥
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
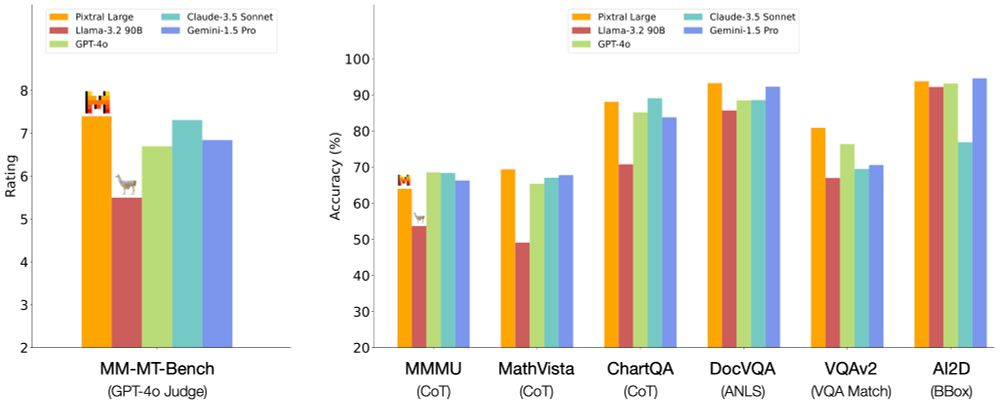
November 19, 2024 at 12:38 PM
🔥 Pixtral Large is now supported on vLLM! 🔥
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
🔥vLLM v0.6.4 is live! This release delivers significant advancements in model compatibility, hardware acceleration, and core engine optimizations.🔥
🤯 Expanded model support? ✅
💪 Intel Gaudi integration? ✅
🚀 Major engine & torch.compile boosts? ✅
🔗 github.com/vllm-project...
🤯 Expanded model support? ✅
💪 Intel Gaudi integration? ✅
🚀 Major engine & torch.compile boosts? ✅
🔗 github.com/vllm-project...

Release v0.6.4 · vllm-project/vllm
Highlights
Significant progress in V1 engine core refactor (#9826, #10135, #10288, #10211, #10225, #10228, #10268, #9954, #10272, #9971, #10224, #10166, #9289, #10058, #9888, #9972, #10059, #9945,...
github.com
November 17, 2024 at 8:59 AM
🔥vLLM v0.6.4 is live! This release delivers significant advancements in model compatibility, hardware acceleration, and core engine optimizations.🔥
🤯 Expanded model support? ✅
💪 Intel Gaudi integration? ✅
🚀 Major engine & torch.compile boosts? ✅
🔗 github.com/vllm-project...
🤯 Expanded model support? ✅
💪 Intel Gaudi integration? ✅
🚀 Major engine & torch.compile boosts? ✅
🔗 github.com/vllm-project...