



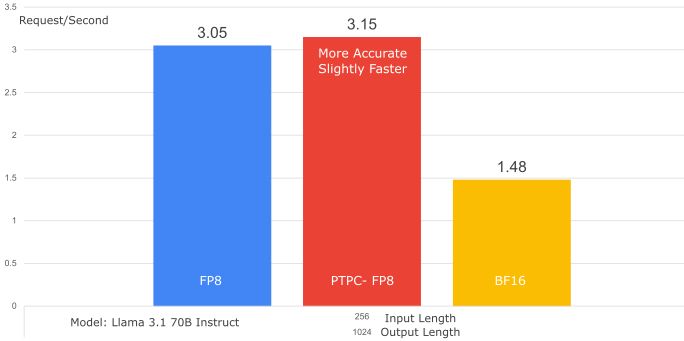
Why PTPC-FP8 rocks:
- Per-Token Activation Scaling: Each token gets its own scaling factor
- Per-Channel Weight Scaling: Each weight column (output channel) gets its own scaling factor
Delivers FP8 speed with accuracy closer to BF16 – the best FP8 option for ROCm! [2/2]
- Per-Token Activation Scaling: Each token gets its own scaling factor
- Per-Channel Weight Scaling: Each weight column (output channel) gets its own scaling factor
Delivers FP8 speed with accuracy closer to BF16 – the best FP8 option for ROCm! [2/2]
March 22, 2025 at 11:47 AM
Why PTPC-FP8 rocks:
- Per-Token Activation Scaling: Each token gets its own scaling factor
- Per-Channel Weight Scaling: Each weight column (output channel) gets its own scaling factor
Delivers FP8 speed with accuracy closer to BF16 – the best FP8 option for ROCm! [2/2]
- Per-Token Activation Scaling: Each token gets its own scaling factor
- Per-Channel Weight Scaling: Each weight column (output channel) gets its own scaling factor
Delivers FP8 speed with accuracy closer to BF16 – the best FP8 option for ROCm! [2/2]
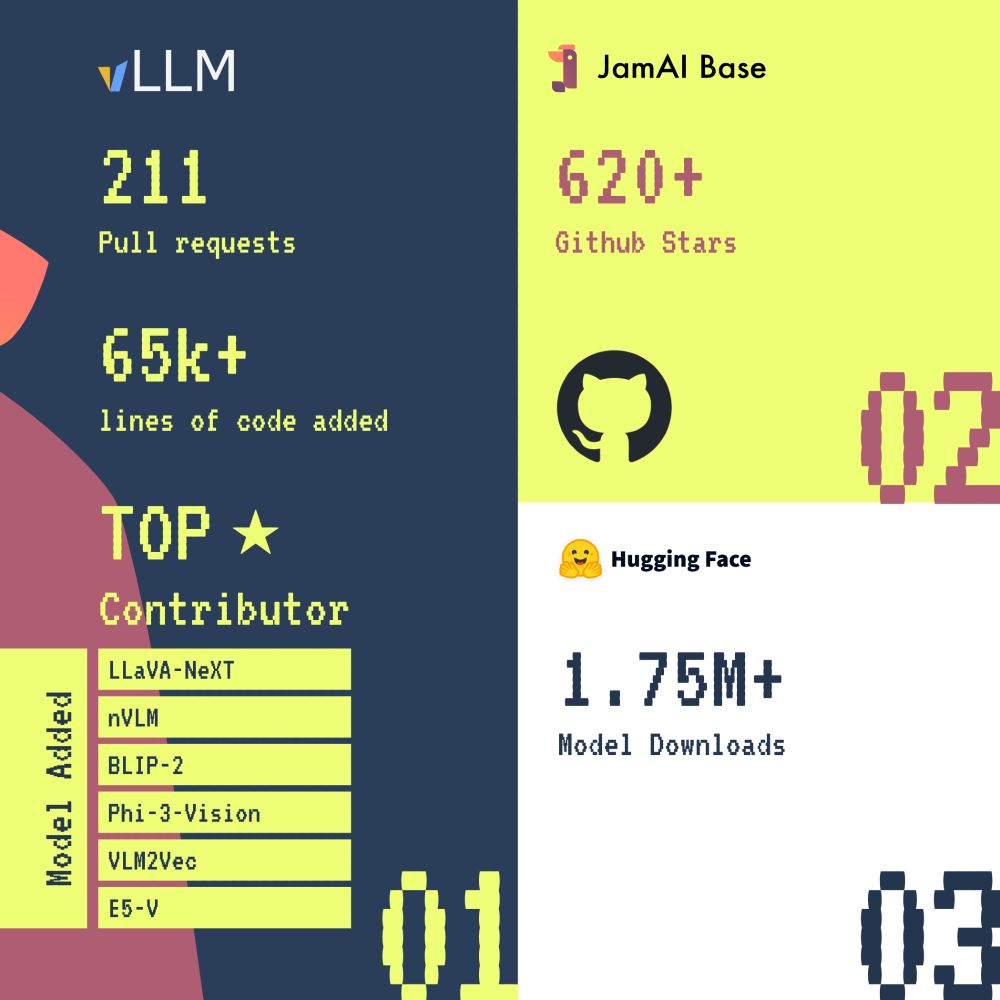
Recap 2024, we've embraced open-source, contributing to vLLM with 211 PRs, 65K+ LOC, and expanded VLM support. Launched #JamAIBase, an AI spreadsheet with 620+ stars, and on 🤗 we have 1.75M+. Collaborated with Liger Kernel & infinity for AMD GPU support. Let's make 2025 even more impactful together!

December 30, 2024 at 4:01 PM
Recap 2024, we've embraced open-source, contributing to vLLM with 211 PRs, 65K+ LOC, and expanded VLM support. Launched #JamAIBase, an AI spreadsheet with 620+ stars, and on 🤗 we have 1.75M+. Collaborated with Liger Kernel & infinity for AMD GPU support. Let's make 2025 even more impactful together!
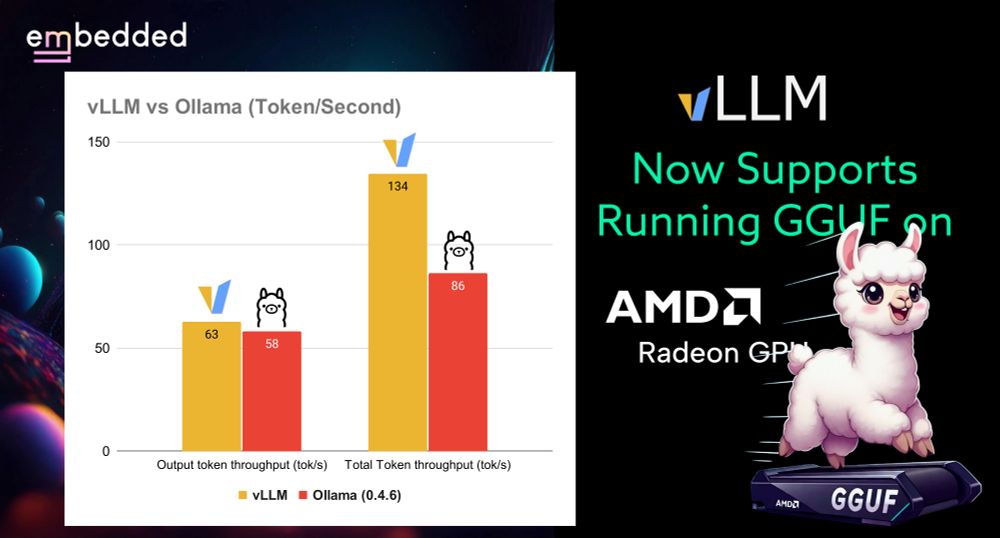
vLLM now supports running GGUF models on AMD Radeon GPUs, with impressive performance on RX 7900XTX. Outperforms Ollama at batch size 1, with 62.66 tok/s vs 58.05 tok/s.
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
December 2, 2024 at 3:47 AM
vLLM now supports running GGUF models on AMD Radeon GPUs, with impressive performance on RX 7900XTX. Outperforms Ollama at batch size 1, with 62.66 tok/s vs 58.05 tok/s.
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
Check it out: embeddedllm.com/blog/vllm-no...
What's your experience with vLLM on AMD? Any features you want to see next?
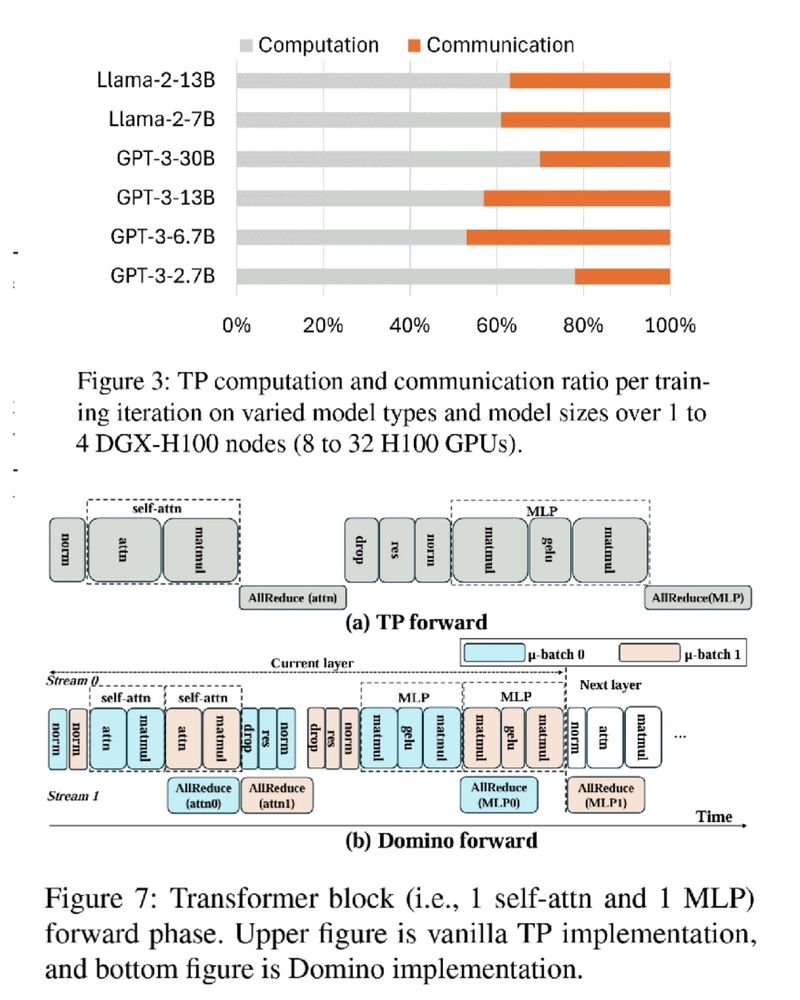
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
November 26, 2024 at 2:35 PM
🚨 GPUs wasting 75% of training time on communication 🤯 Not anymore!
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
DeepSpeed Domino, with a new tensor parallelism engine, minimizes communication overhead for faster LLM training. 🚀
✅ Near-complete communication hiding
✅ Multi-node scalable solution
Blog: github.com/microsoft/De...
🔥 Pixtral Large is now supported on vLLM! 🔥
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
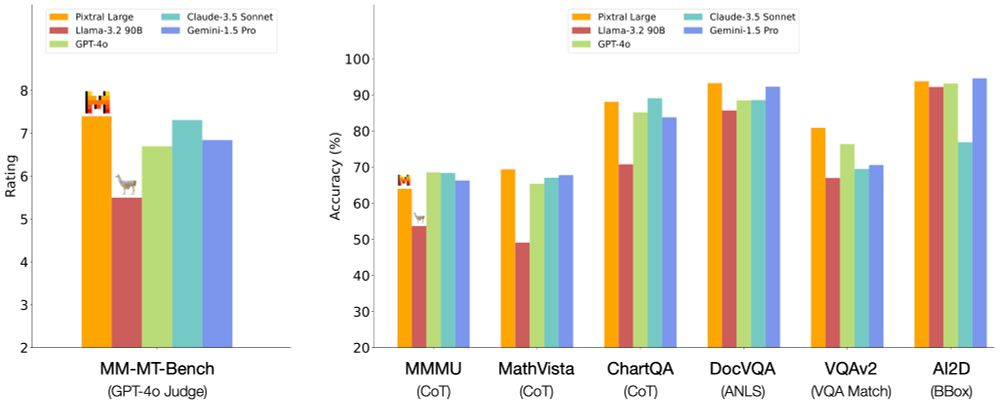
November 19, 2024 at 12:38 PM
🔥 Pixtral Large is now supported on vLLM! 🔥
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8
Run Pixtral Large with multiple input images from day 0 using vLLM.
Install vLLM:
pip install -U VLLM
Run Pixtral Large:
vllm serve mistralai/Pixtral-Large-Instruct-2411 --tokenizer_mode mistral --limit_mm_per_prompt 'image=10' --tensor-parallel-size 8