



Mimoune Djouallah
@mimdj.bsky.social
#MicrosofFabric Customer advocate, interests in Small Data & Self Service #Microsoftemployee since Dec 2023 , but my tweets are my own
DuckDB just added native write support to OneLake. It is still early, and for now it only works through the blob API, There is no Delta write yet, but it is a very exciting first step.
#MicrosoftFabric #duckdb #Python #SQL
www.youtube.com/watch?v=V01W...
#MicrosoftFabric #duckdb #Python #SQL
www.youtube.com/watch?v=V01W...

Second Look at Ducklake in Onelake
YouTube video by DataMonkey
www.youtube.com
December 10, 2025 at 12:05 PM
DuckDB just added native write support to OneLake. It is still early, and for now it only works through the blob API, There is no Delta write yet, but it is a very exciting first step.
#MicrosoftFabric #duckdb #Python #SQL
www.youtube.com/watch?v=V01W...
#MicrosoftFabric #duckdb #Python #SQL
www.youtube.com/watch?v=V01W...
how to query #onelake iceberg catalog using pure sql with #duckdb
the query cross join a table from #MicrosoftFabric Warehouse and #Snowflake, why not :)
duckdb has no read only mode, so every query check the remote table state, which create a not so great experience
www.youtube.com/watch?v=DK8i...
the query cross join a table from #MicrosoftFabric Warehouse and #Snowflake, why not :)
duckdb has no read only mode, so every query check the remote table state, which create a not so great experience
www.youtube.com/watch?v=DK8i...

Querying Onelake Iceberg REST Catalog using DuckDB CLI with pure SQL
YouTube video by DataMonkey
www.youtube.com
December 6, 2025 at 1:16 PM
how to query #onelake iceberg catalog using pure sql with #duckdb
the query cross join a table from #MicrosoftFabric Warehouse and #Snowflake, why not :)
duckdb has no read only mode, so every query check the remote table state, which create a not so great experience
www.youtube.com/watch?v=DK8i...
the query cross join a table from #MicrosoftFabric Warehouse and #Snowflake, why not :)
duckdb has no read only mode, so every query check the remote table state, which create a not so great experience
www.youtube.com/watch?v=DK8i...
Explaining how Python engines read and write #DeltaTable is not for the faint of heart.
The theory is everything will depends on the delta kernet rust for read and write, but we are not there yet
github.com/djouallah/Fa...
#duckdb #delta_rs #datafusion #chdb #daft #polars #rust #lakesail
The theory is everything will depends on the delta kernet rust for read and write, but we are not there yet
github.com/djouallah/Fa...
#duckdb #delta_rs #datafusion #chdb #daft #polars #rust #lakesail

October 27, 2025 at 10:53 AM
Explaining how Python engines read and write #DeltaTable is not for the faint of heart.
The theory is everything will depends on the delta kernet rust for read and write, but we are not there yet
github.com/djouallah/Fa...
#duckdb #delta_rs #datafusion #chdb #daft #polars #rust #lakesail
The theory is everything will depends on the delta kernet rust for read and write, but we are not there yet
github.com/djouallah/Fa...
#duckdb #delta_rs #datafusion #chdb #daft #polars #rust #lakesail
Reposted by Mimoune Djouallah

Any system that allows exchanging real money for stuff with an element of chance is morally equivalent to a casino.
Corollary: Pokémon cards, Roblox, Labubus, and even claw machines should all be 18+
Corollary: Pokémon cards, Roblox, Labubus, and even claw machines should all be 18+

Do you have any extremely niche, but serious, ethical stances?
October 20, 2025 at 11:07 AM
Any system that allows exchanging real money for stuff with an element of chance is morally equivalent to a casino.
Corollary: Pokémon cards, Roblox, Labubus, and even claw machines should all be 18+
Corollary: Pokémon cards, Roblox, Labubus, and even claw machines should all be 18+
running #duckdb at 10 TB scale using #tpch like benchmark
#delta #onelake #singlenode #MicrosoftFabric
datamonkeysite.com/2025/10/19/r...
#delta #onelake #singlenode #MicrosoftFabric
datamonkeysite.com/2025/10/19/r...

October 19, 2025 at 2:05 PM
running #duckdb at 10 TB scale using #tpch like benchmark
#delta #onelake #singlenode #MicrosoftFabric
datamonkeysite.com/2025/10/19/r...
#delta #onelake #singlenode #MicrosoftFabric
datamonkeysite.com/2025/10/19/r...
you are looking at #duckdb running tpch 1 TB with only 16 cores
it used to crash even with 64
pip install duckdb --upgrade is an act of faith basically
it used to crash even with 64
pip install duckdb --upgrade is an act of faith basically

October 10, 2025 at 5:04 AM
you are looking at #duckdb running tpch 1 TB with only 16 cores
it used to crash even with 64
pip install duckdb --upgrade is an act of faith basically
it used to crash even with 64
pip install duckdb --upgrade is an act of faith basically
Put together a small python package duckrun :) point it at a folder of SQL/Python files, define a pipeline, and it will create Delta tables in #OneLake with #DuckDB and #delta_rs
github.com/djouallah/du...
github.com/djouallah/du...

October 3, 2025 at 11:17 AM
Put together a small python package duckrun :) point it at a folder of SQL/Python files, define a pipeline, and it will create Delta tables in #OneLake with #DuckDB and #delta_rs
github.com/djouallah/du...
github.com/djouallah/du...
actually #Microsoftfabric Datawarehouse automatically expose an Iceberg rest Catalog
thanks to #duckdb UI extension, you can see proper catalog
thanks to #duckdb UI extension, you can see proper catalog

September 25, 2025 at 12:57 PM
actually #Microsoftfabric Datawarehouse automatically expose an Iceberg rest Catalog
thanks to #duckdb UI extension, you can see proper catalog
thanks to #duckdb UI extension, you can see proper catalog
First Look at #onelake #apacheiceberg REST Catalog, please notice it is coming soon and not in production yet #MicrosoftFabric
www.youtube.com/watch?v=_QRE...
www.youtube.com/watch?v=_QRE...

First Look at Onelake Iceberg REST Catalog
YouTube video by DataMonkey
www.youtube.com
September 20, 2025 at 6:23 AM
First Look at #onelake #apacheiceberg REST Catalog, please notice it is coming soon and not in production yet #MicrosoftFabric
www.youtube.com/watch?v=_QRE...
www.youtube.com/watch?v=_QRE...
Reposted by Mimoune Djouallah

#pyconau @mimdj.bsky.social Life Beyond Pandas: Workflows with DuckDB, Daft, Polars, and Datafusion http://youtu.be/SnogunyMnE8
September 19, 2025 at 2:25 PM
#pyconau @mimdj.bsky.social Life Beyond Pandas: Workflows with DuckDB, Daft, Polars, and Datafusion http://youtu.be/SnogunyMnE8
2 months ago, I got access to a beta release of #onelake #Apacheiceberg REST Catalog, first thing I run it with #duckdb 😀

September 16, 2025 at 12:49 PM
2 months ago, I got access to a beta release of #onelake #Apacheiceberg REST Catalog, first thing I run it with #duckdb 😀
storage format should not be tied to #SQL logic, #duckdb got it so right !!! but a bit sad that #deltalake is left behind :(

September 15, 2025 at 11:30 AM
storage format should not be tied to #SQL logic, #duckdb got it so right !!! but a bit sad that #deltalake is left behind :(
First look at incremental framing in #PowerBI directlake mode
#Parquet #OLAP #optimization #Performance #onelake
datamonkeysite.com/2025/09/09/f...
#Parquet #OLAP #optimization #Performance #onelake
datamonkeysite.com/2025/09/09/f...

First Look at Incremental Framing in Power BI
TL;DR: Incremental framing is like CDC to RAM :) It significantly improves cold-run performance of Direct Lake mode in some scenarios, there is an excellent documentation that explain everything in…
datamonkeysite.com
September 9, 2025 at 1:38 PM
First look at incremental framing in #PowerBI directlake mode
#Parquet #OLAP #optimization #Performance #onelake
datamonkeysite.com/2025/09/09/f...
#Parquet #OLAP #optimization #Performance #onelake
datamonkeysite.com/2025/09/09/f...

first #apacheiceberg table written by #duckdb

September 6, 2025 at 12:07 PM
first #apacheiceberg table written by #duckdb
good news #duckdb added support for reading and writing geometry data type
Bad news : other Fabric engines don't support it yet, so it is not very useful for now :(
Bad news : other Fabric engines don't support it yet, so it is not very useful for now :(

September 5, 2025 at 1:17 PM
good news #duckdb added support for reading and writing geometry data type
Bad news : other Fabric engines don't support it yet, so it is not very useful for now :(
Bad news : other Fabric engines don't support it yet, so it is not very useful for now :(

September 1, 2025 at 10:00 AM
Third time is the charm ✨
With the much needed improvements to the #MicrosoftFabric scheduler, I revisited my review of Fabric F2.
#duckdb #sql
www.youtube.com/watch?v=tchY...
With the much needed improvements to the #MicrosoftFabric scheduler, I revisited my review of Fabric F2.
#duckdb #sql
www.youtube.com/watch?v=tchY...

Third Look at Fabric F2
YouTube video by DataMonkey
www.youtube.com
August 25, 2025 at 11:43 AM
Third time is the charm ✨
With the much needed improvements to the #MicrosoftFabric scheduler, I revisited my review of Fabric F2.
#duckdb #sql
www.youtube.com/watch?v=tchY...
With the much needed improvements to the #MicrosoftFabric scheduler, I revisited my review of Fabric F2.
#duckdb #sql
www.youtube.com/watch?v=tchY...
new world record 😝 using #duckdb and #ducklake
22 cents for the 3 B rows, coffee benchmark :)
not bad at all for a single node :)
www.linkedin.com/posts/mimoun...
22 cents for the 3 B rows, coffee benchmark :)
not bad at all for a single node :)
www.linkedin.com/posts/mimoun...

☕ Coffee benchmark at 3B scale factor : $0.22 total cost 💰 | Mimoune Djouallah
☕ Coffee benchmark at 3B scale factor : $0.22 total cost 💰
7 Months later, using the latest dev release of #DuckDB with #DuckLake, we cut the cost of running the unfamous :) coffee benchmark to just ...
www.linkedin.com
August 15, 2025 at 3:12 PM
new world record 😝 using #duckdb and #ducklake
22 cents for the 3 B rows, coffee benchmark :)
not bad at all for a single node :)
www.linkedin.com/posts/mimoun...
22 cents for the 3 B rows, coffee benchmark :)
not bad at all for a single node :)
www.linkedin.com/posts/mimoun...
Writing #ApacheIceberg in Azure is not particularly hard, but you do need a catalog (essentially a database). For simple tests, you can use an in-memory DB
#ADLS #opentableformat #PyIceberg.
#ADLS #opentableformat #PyIceberg.

August 13, 2025 at 1:17 PM
Writing #ApacheIceberg in Azure is not particularly hard, but you do need a catalog (essentially a database). For simple tests, you can use an in-memory DB
#ADLS #opentableformat #PyIceberg.
#ADLS #opentableformat #PyIceberg.
Reposted by Mimoune Djouallah

mssql-python vs pyodbc: Benchmarking SQL Server Performance - devblogs.microsoft.com/python/mssql...
A pretty big rewrite, actually
A pretty big rewrite, actually

mssql-python vs pyodbc: Benchmarking SQL Server Performance - Microsoft for Python Developers Blog
Learn how the python driver for SQL Server, mssql-python, outperforms pyodbc in terms of latency and throughput for developers.
devblogs.microsoft.com
August 12, 2025 at 4:49 PM
mssql-python vs pyodbc: Benchmarking SQL Server Performance - devblogs.microsoft.com/python/mssql...
A pretty big rewrite, actually
A pretty big rewrite, actually


first impression of #qwen3 30B-A3B-Instruct-2507 Local analyzing a wide table in my laptop
it still feels strange that all that knowledge is encoded in one file in my hard drive :)
www.youtube.com/watch?v=gmk7...
#mcp #nl2sql #sql
it still feels strange that all that knowledge is encoded in one file in my hard drive :)
www.youtube.com/watch?v=gmk7...
#mcp #nl2sql #sql
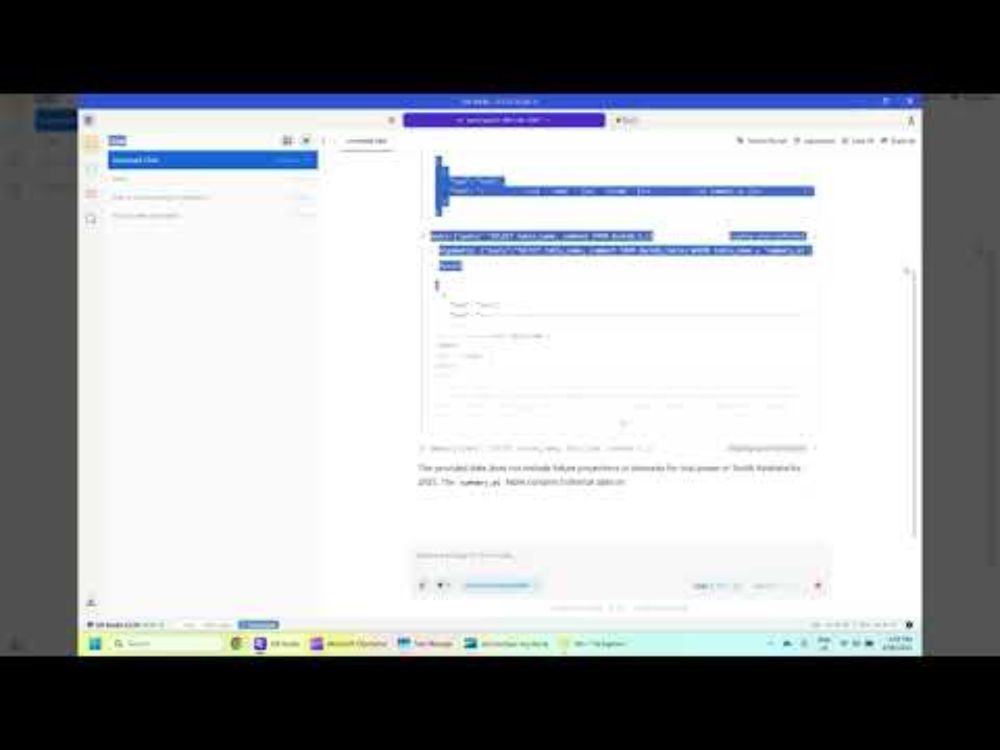
first look at Qwen3-30B-A3B-Instruct-2507 running in my laptop
YouTube video by DataMonkey
www.youtube.com
August 4, 2025 at 11:18 AM
first impression of #qwen3 30B-A3B-Instruct-2507 Local analyzing a wide table in my laptop
it still feels strange that all that knowledge is encoded in one file in my hard drive :)
www.youtube.com/watch?v=gmk7...
#mcp #nl2sql #sql
it still feels strange that all that knowledge is encoded in one file in my hard drive :)
www.youtube.com/watch?v=gmk7...
#mcp #nl2sql #sql
Reposted by Mimoune Djouallah

I see a new destination for Dataflows Gen2 in Fabric! #SharePoint destination is in preview! This opens up so many possibilities for business applications! You can save your prepared and transformed data in CSV or Excel file formats. #MicrosoftFabric #DataFactory #Dataflows

August 1, 2025 at 11:24 PM
I see a new destination for Dataflows Gen2 in Fabric! #SharePoint destination is in preview! This opens up so many possibilities for business applications! You can save your prepared and transformed data in CSV or Excel file formats. #MicrosoftFabric #DataFactory #Dataflows