



Heather Froehlich
@heatherfro.bsky.social
supporting researchers counting words in various ways with computers at university of arizona libraries; increasingly displaced new englander
Reposted by Heather Froehlich

New issue of my newsletter: "The Writing Is on the Wall for Handwriting Recognition" — One of the hardest problems in digital humanities has finally been solved, and it's a good use of AI newsletter.dancohen.org/archive/the-...

The Writing Is on the Wall for Handwriting Recognition
One of the hardest problems in digital humanities has finally been solved
newsletter.dancohen.org
November 25, 2025 at 4:35 PM
New issue of my newsletter: "The Writing Is on the Wall for Handwriting Recognition" — One of the hardest problems in digital humanities has finally been solved, and it's a good use of AI newsletter.dancohen.org/archive/the-...
Reposted by Heather Froehlich

I’ve been running around asking tech execs and academics if language was the same as intelligence for over a year now - and, well, it isn’t. @benjaminjriley.bsky.social explains how the bubble is built on ignoring cutting-edge research into the science of thought www.theverge.com/ai-artificia...

November 25, 2025 at 1:54 PM
I’ve been running around asking tech execs and academics if language was the same as intelligence for over a year now - and, well, it isn’t. @benjaminjriley.bsky.social explains how the bubble is built on ignoring cutting-edge research into the science of thought www.theverge.com/ai-artificia...
Reposted by Heather Froehlich

The UW Center for an Informed Public is looking for postdocs (for 2026-2028) from across diverse disciplines whose research sheds light on the challenges of our modern information environment, promotes civic health, and/or helps people/communities navigate online spaces: apply.interfolio.com/177901
Apply - Interfolio
{{$ctrl.$state.data.pageTitle}} - Apply - Interfolio
apply.interfolio.com
November 24, 2025 at 6:26 PM
The UW Center for an Informed Public is looking for postdocs (for 2026-2028) from across diverse disciplines whose research sheds light on the challenges of our modern information environment, promotes civic health, and/or helps people/communities navigate online spaces: apply.interfolio.com/177901
Reposted by Heather Froehlich

Journalist challenge: Use “Machine Learning” when you mean machine learning and “LLM” when you mean LLM. Ditch “AI” as a catch-all term, it’s not useful for readers and it helps companies trying to confuse the public by obscuring the roles played by different technologies. 🧪
November 22, 2025 at 4:50 PM
Journalist challenge: Use “Machine Learning” when you mean machine learning and “LLM” when you mean LLM. Ditch “AI” as a catch-all term, it’s not useful for readers and it helps companies trying to confuse the public by obscuring the roles played by different technologies. 🧪
Reposted by Heather Froehlich

I need everyone, esp anyone working in education or tech (but really everyone) to WATCH THIS CLIP of @drtanksley.bsky.social discussing the technologies infiltrating our schools & psyches and how she is addressing it with our young people. youtu.be/5mtcSL4S3HQ

Howard University AI Panel
YouTube video by Tiera Tanksley
youtu.be
November 22, 2025 at 1:43 PM
I need everyone, esp anyone working in education or tech (but really everyone) to WATCH THIS CLIP of @drtanksley.bsky.social discussing the technologies infiltrating our schools & psyches and how she is addressing it with our young people. youtu.be/5mtcSL4S3HQ
Reposted by Heather Froehlich

Seth Rockman: 'Experiential research as a method for IDing questions you didn’t know to ask, rather than providing answers you wouldn’t have had...an experiential research method lets us envision more things we want to know about the past' (experiential=do something the way it was done in the past)

November 22, 2025 at 1:32 PM
Seth Rockman: 'Experiential research as a method for IDing questions you didn’t know to ask, rather than providing answers you wouldn’t have had...an experiential research method lets us envision more things we want to know about the past' (experiential=do something the way it was done in the past)
Reposted by Heather Froehlich
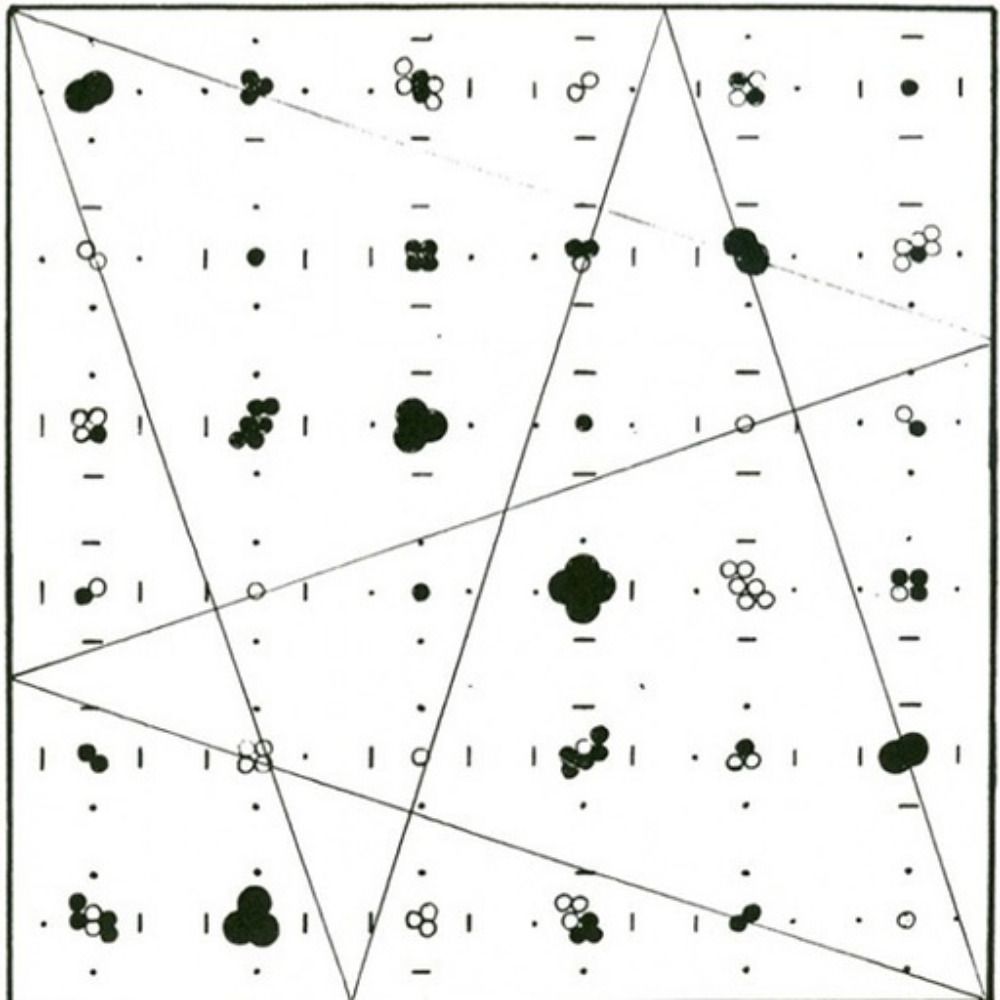
Here's a short thing on adversarial language, following yesterday's poetry news. It argues for interpretability work undertaken via literary studies and tries to acknowledge some difficulties this would entail.
For Those Who May Find Themselves on the Red Team: tylershoemaker.info/docs/shoemak...
For Those Who May Find Themselves on the Red Team: tylershoemaker.info/docs/shoemak...

November 21, 2025 at 8:39 PM
Here's a short thing on adversarial language, following yesterday's poetry news. It argues for interpretability work undertaken via literary studies and tries to acknowledge some difficulties this would entail.
For Those Who May Find Themselves on the Red Team: tylershoemaker.info/docs/shoemak...
For Those Who May Find Themselves on the Red Team: tylershoemaker.info/docs/shoemak...
Funding: @bloomberg.com is pleased to announce the 2026-2027 edition of the Bloomberg Data Science Ph.D. Fellowship Program www.techatbloomberg.com/bloomberg-da...

Data Science Ph.D. Fellowship | Bloomberg LP
Apply now for the Bloomberg Data Science Ph.D. Fellowship program. Applications are due by April 28, 2023 for the 2023-2024 academic year.
www.techatbloomberg.com
November 21, 2025 at 3:56 PM
Funding: @bloomberg.com is pleased to announce the 2026-2027 edition of the Bloomberg Data Science Ph.D. Fellowship Program www.techatbloomberg.com/bloomberg-da...
Reposted by Heather Froehlich

For those of you curious about folks who are not enthralled with AI companies but who also want to preserve broad fair use, free exchange of ideas/citation/building on what’s come before, plus are anti-monopoly, this group is good, and this newsletter interesting

Suno, Yout, Perplexity AI and §1201: AI Training and another piece of the DMCA
“No person shall circumvent a technological measure that effectively controls access to a work protected under this title.” 17 U.S.C.
open.substack.com
November 21, 2025 at 3:23 PM
For those of you curious about folks who are not enthralled with AI companies but who also want to preserve broad fair use, free exchange of ideas/citation/building on what’s come before, plus are anti-monopoly, this group is good, and this newsletter interesting
Reposted by Heather Froehlich

The word SNEEZE used to be FNESE, as in "He speketh in his nose And fneseth faste" (Canterbury Tales)
FNESE faded out in the 15thC, superseded by NESE/NEEZE. Then an s- was added, maybe to strengthen it or to align with other nose-related sn- words
Anyway I think we should bring FNESE back
FNESE faded out in the 15thC, superseded by NESE/NEEZE. Then an s- was added, maybe to strengthen it or to align with other nose-related sn- words
Anyway I think we should bring FNESE back

Man, everything is so bleak, anyone got a fun fact or little bit of trivia they want to share
November 21, 2025 at 10:33 AM
The word SNEEZE used to be FNESE, as in "He speketh in his nose And fneseth faste" (Canterbury Tales)
FNESE faded out in the 15thC, superseded by NESE/NEEZE. Then an s- was added, maybe to strengthen it or to align with other nose-related sn- words
Anyway I think we should bring FNESE back
FNESE faded out in the 15thC, superseded by NESE/NEEZE. Then an s- was added, maybe to strengthen it or to align with other nose-related sn- words
Anyway I think we should bring FNESE back
Reposted by Heather Froehlich

We are excited to welcome Dorothy Berry as the speaker for our 2025 annual lecture, "How Users Imagine Archival Research", on December 10th. Register now: https://edin.ac/4pfKrDp #EdCDCS Charing: Melissa Terras

November 21, 2025 at 1:01 PM
We are excited to welcome Dorothy Berry as the speaker for our 2025 annual lecture, "How Users Imagine Archival Research", on December 10th. Register now: https://edin.ac/4pfKrDp #EdCDCS Charing: Melissa Terras
Reposted by Heather Froehlich

This study show that using poems to jailbreak LLMs is... super effective? What the heck.

November 20, 2025 at 5:36 PM
This study show that using poems to jailbreak LLMs is... super effective? What the heck.
Reposted by Heather Froehlich

It’s all happening: Shakespeare in the Kitchen is slated for publication in April 2026 🍽️📗🎉 www.routledge.com/Shakespeare-...

Shakespeare in the Kitchen
Audiences and scholars alike have long remarked that Shakespeare’s poems and plays record the pleasures and perils of the table. Shakespeare in the Kitchen asks what Shakespeare’s works can tell us ab...
www.routledge.com
November 20, 2025 at 5:04 PM
It’s all happening: Shakespeare in the Kitchen is slated for publication in April 2026 🍽️📗🎉 www.routledge.com/Shakespeare-...
Reposted by Heather Froehlich

📣 Really proud to announce the publication of Reframing Failure in Digital Scholarship, an #OpenAccess collection of essays co-edited with @amsichani.bsky.social and published by @uolpress.bsky.social that examines the role of failure in #DH and research more broadly
@sas-news.bsky.social
@sas-news.bsky.social

Reframing Failure in Digital Scholarship - University of London Press
Failure is ordinary. From technological failures and computational obsolescence to rejected applications and challenging collaborations, failure is an unavoidable part of any scholarly endeavour. This...
uolpress.co.uk
November 20, 2025 at 9:26 AM
📣 Really proud to announce the publication of Reframing Failure in Digital Scholarship, an #OpenAccess collection of essays co-edited with @amsichani.bsky.social and published by @uolpress.bsky.social that examines the role of failure in #DH and research more broadly
@sas-news.bsky.social
@sas-news.bsky.social
Two weeks ago I gave a talk at Australian National Uni that included a list of things I would do with an Sands & Mac volume (1910) and .... THIS WAS ONE OF THEM
Love this so much
Love this so much

Good to hear today that my new Sands & Mac is already being used by front-of-house librarians at the SLV to help people with their family history queries. https://updates.timsherratt.org/2025/11/12/a-new-way-of-searching.html

In the fortnight I spent onsite at the State Library of Victoria, ‘Sands & Mac’ was mentioned many times. And no wonder. The Sands & McDougall’s directories are a goldmine for anyone researching family, local, or social history. They list thousands of names and addresses, enabling you to find individuals, and explore changing land use over time. When people ask the SLV’s librarians, ‘What can you tell me about the history of my house?’, Sands & Mac is one of the first resources consulted.
The SLV has digitised 24 volumes of Sands & Mac, one every five years from 1860 to 1974. You can browse the contents of each volume in the SLV image viewer, using the partial contents listing to help you find your way to sections of interest. To search the full text content you need to use the PDF version, either in the built-in viewer, or by downloading the PDF. There’s a handy guide to using Sands & Mac that explains the options.
**However, there’s currently no way of searching across all 24 volumes, so as part of my residency at the SLV LAB, I thought I’d make one!**
**Try it now!**
My new Sands & Mac database follows the pattern I’ve used previously to create fully-searchable versions of the NSW Post Office directories, Sydney telephone directories, and Tasmanian Post Office directories. Every line of text is saved to a database, so a single query searches for entries across all volumes. You can also use advanced search features like wildcards and boolean operators.
Search across all 24 volumes!
Once you’ve found a relevant entry you can view it in context, alongside a zoomable image of the page. You can even use Zotero to save individual entries to your own research database. This blog post from the Everyday Heritage project describes how the Tasmanian directories have been used to map Tasmania’s Chinese population.
View each entry in context! (Here's my Dad building his first house in Beaumaris in the 1950s.)
There’s still a few things I’d like to try, such as making use of the table of contents information for each volume. I’d also like to create some additional entry points to take users directly to listings for individual suburbs (maybe even streets!). Each volume has a directory of suburbs, so it would be a matter of extracting and cleaning the data and linking the entries to digitised pages. Certainly possible, but I don’t think I’ll have time to get it all done before the end of my residency. Perhaps I’ll try to get at least one volume done to demonstrate how it might work, and the value it would add. As I was writing this blog post I also realised there’s a dataset of businesses extracted from the Sands & Mac, so I need to think about how I can use that as well!
## Technical information follows…
I’ve documented the process I used to create fully-searchable versions of the Tasmanian and NSW directories in the GLAM Workbench. I followed a similar method for Sands and Mac, though with a few dead-ends and discoveries along the way.
### Downloading the PDFs
I assumed that it would be easiest to work from the PDF versions of each volume, as I’d done for Tasmania. So I set about finding a way to download them all. There’s only 24 volumes, so I _could_ have downloaded them manually, but where’s the fun in that?
I started with a CSV file listing the Sands & Mac volumes that I downloaded from the catalogue. This gave me the Alma identifiers for each volume. To download the PDFs I needed two more identifiers, the `IE` identifier assigned to each digitised item, and a file identifier that points to the PDF version of the item. The `IE` identifier can be extracted from the item’s MARC record, as I described in my post on exploring urls. The PDF file identifier was a bit more difficult to track down. The PDF links in the image viewer are generated dynamically, so the data had to be coming from somewhere. Eventually I found that the viewer loaded a JSON file with all sorts of useful metadata in it!
The url to download the JSON file is: `https://viewerapi.slv.vic.gov.au/?entity=[IE identifier]&dc_arrays=1`. In the `summary` section I found identifiers for `small_pdf` and `master_pdf`.
I could then use these identifiers to construct urls to download the PDFs themselves: `https://rosetta.slv.vic.gov.au/delivery/DeliveryManagerServlet?dps_func=stream&dps_pid=[PDF id]`
Once I had the PDFs I used PyMuPDF to extract all the text and images. As I suspected the text wasn’t really fit for purpose. The OCR was ok, but the column structures were a mess. Because I wanted to index each entry individually, it was important to try and get the columns represented as accurately as possible. The images in the small PDFs were already bitonal, so I started feeding them to Tesseract to see if I could get better results. After a bit of tweaking, things were looking pretty good. But when I came to compile all the data, I realised there was a potential problem matching the PDF pages to the images available through IIIF. I found one case where some pages were missing from the PDF, and another couple where the page order was different.
As I was looking around for a solution, I realised that those JSON files I downloaded to get the PDF identifiers also included links to ALTO XML files that contain all the original OCR data (before it got mangled by the PDF formatting). There was one ALTO file for every page. Even better, the JSON linked the identifiers for the text and the image together – no more page mismatches!
### Downloading the ALTO files
Let’s start this again shall we. After wasting several days futzing about with the PDFs, I decided to download all the ALTO files and extract the text from them. As I downloaded each XML file, I also grabbed the corresponding image identifier from the JSON and included both identifiers in the file name for safe keeping.
The ALTO files break the text down by block, line, and word. To extract the text, I just looped through every line, joining the words back together as a string, and writing the result to a new text file – one for each page.
It’s worth noting that the ALTO files include _all_ the positional data generated by the OCR process, so you have the size and position of every word on every page. I just pulled out the text, but there are many more interesting things you could do…
### Assembling and publishing the database
From here on everything pretty much followed the pattern of the NSW and Tasmanian directories. I looped through each volume, page, and line of text, adding the text and metadata to a SQLite database using sqlite_utils. I then indexed the text for full-text searching. At the same time I populated a metadata file with titles, urls, and few configuration details. The metadata file is used by Datasette to fill in parts of the interface.
I made some minor changes to the Datasette template I used for the other directories. In particular, I had to update the urls that loaded the IIIF images into the OpenSeadragon viewer. But it mostly just worked. It’s so nice to be able to reuse existing patterns!
Finally, I used Datasette’s `publish` command to push everything to Google Cloudrun. The final database contains details of more than 50,000 pages, and over 19 million lines of text! It weighs in at about 1.7gb. The Cloudrun service will ‘scale to zero’ when not in use. This saves some money and resources, but means it can take a little while to spin up. Once it’s loaded, it’s very fast. My original post on the Tasmanian directories included a little note on costs, if you’re interested.
## More information
The notebooks I used are on GitHub:
* Download Sands and Mac PDFs and OCR text
* Load data from the Sands and Mac directories into an SQLite database (for use with Datasette)
Here are some posts about the NSW and Tasmanian directories:
* Making NSW Postal Directories (and other digitised directories) easier to search with the GLAM Workbench and Datasette (September 2022)
* From 48 PDFs to one searchable database – opening up the Tasmanian Post Office Directories with the GLAM Workbench (September 2022)
* Where’s 1920? Missing volume added to Tasmanian Post Office Directories! (September 2024)
* Six more volumes added to the searchable database of Tasmanian Post Office Directories! (November 2024)
updates.timsherratt.org
November 20, 2025 at 2:22 AM
Two weeks ago I gave a talk at Australian National Uni that included a list of things I would do with an Sands & Mac volume (1910) and .... THIS WAS ONE OF THEM
Love this so much
Love this so much
Reposted by Heather Froehlich

My PhD dissertation is now available for download to anyone in the world 🙂
‘Learning To Talk to Generative AI Chatbots’: A Corpus Study of Generative AI Prompts, an Emerging Genre for AI Literacy
repository.arizona.edu/handle/10150...
‘Learning To Talk to Generative AI Chatbots’: A Corpus Study of Generative AI Prompts, an Emerging Genre for AI Literacy
repository.arizona.edu/handle/10150...
‘Learning To Talk to Generative AI Chatbots’: A Corpus Study of Generative AI Prompts, an Emerging Genre for AI Literacy
repository.arizona.edu
November 19, 2025 at 8:33 PM
My PhD dissertation is now available for download to anyone in the world 🙂
‘Learning To Talk to Generative AI Chatbots’: A Corpus Study of Generative AI Prompts, an Emerging Genre for AI Literacy
repository.arizona.edu/handle/10150...
‘Learning To Talk to Generative AI Chatbots’: A Corpus Study of Generative AI Prompts, an Emerging Genre for AI Literacy
repository.arizona.edu/handle/10150...
Reposted by Heather Froehlich

if you are considering submitting an application for this position, you still have just under 2 weeks to do so
any and all suitable candidates, please apply. everyone else, pls share with your networks
any and all suitable candidates, please apply. everyone else, pls share with your networks
📣 I am hiring a postdoc! aial.ie/hiring/postd...
applications from suitable candidates that are passionate about investigating the use of genAI in public service operations with the aim of keeping governments transparent and accountable are welcome
pls share with your networks
applications from suitable candidates that are passionate about investigating the use of genAI in public service operations with the aim of keeping governments transparent and accountable are welcome
pls share with your networks
November 19, 2025 at 2:44 PM
if you are considering submitting an application for this position, you still have just under 2 weeks to do so
any and all suitable candidates, please apply. everyone else, pls share with your networks
any and all suitable candidates, please apply. everyone else, pls share with your networks
Reposted by Heather Froehlich

📢Here's a fully funded 4-year PhD position at Leiden within the ERC project LangPro led by Dr Alisa van de Haar, and co-supervised by yours truly, on professional opportunities for women in the early modern language sector bit.ly/47Y3hYI
Apply by 15 Feb. 2026; starting date 1 Aug. 2026
Apply by 15 Feb. 2026; starting date 1 Aug. 2026
PhD position, project: LangPro Women in the Early Modern Language Sector
PhD position, project: LangPro Women in the Early Modern Language Sector
careers.universiteitleiden.nl
November 18, 2025 at 4:22 PM
📢Here's a fully funded 4-year PhD position at Leiden within the ERC project LangPro led by Dr Alisa van de Haar, and co-supervised by yours truly, on professional opportunities for women in the early modern language sector bit.ly/47Y3hYI
Apply by 15 Feb. 2026; starting date 1 Aug. 2026
Apply by 15 Feb. 2026; starting date 1 Aug. 2026
Reposted by Heather Froehlich

1/ Announcing GovScape – a public search system for 10 million U.S. government PDFs (70 million pages)! GovScape offers visual search, semantic text search, and keyword search. Explore below:
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
www.govscape.net
November 18, 2025 at 8:19 PM
1/ Announcing GovScape – a public search system for 10 million U.S. government PDFs (70 million pages)! GovScape offers visual search, semantic text search, and keyword search. Explore below:
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Website: www.govscape.net
ArXiv link: arxiv.org/abs/2511.11010
Reposted by Heather Froehlich

📢 The #CHR2025 proceedings are out!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!

Edited by Taylor Arnold, Margherita Fantoli, and Ruben Ros
anthology.ach.org
November 19, 2025 at 12:53 PM
📢 The #CHR2025 proceedings are out!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
97 papers, ~1600 pages of computational humanities 🔥 Now published via the new Anthology of Computers and the Humanities, with DOIs for every paper.
🔗 anthology.ach.org/volumes/vol0...
And don’t forget: registration closes tomorrow (20 Nov)!
Reposted by Heather Froehlich

Solange Knowles’ Saint Heron has launched a free digital archival library of literature by Black and brown authors, poets, and artists. Readers can borrow rare and out-of-print books for up to 45 days

Solange Opens Free Digital Library Of Rare Black Books
Solange has launched a digital library archive of Black and brown authors where readers can borrow books at no cost.
peopleofcolorintech.com
November 18, 2025 at 11:58 PM
Solange Knowles’ Saint Heron has launched a free digital archival library of literature by Black and brown authors, poets, and artists. Readers can borrow rare and out-of-print books for up to 45 days
Reposted by Heather Froehlich

JOB POSTING!
Andrew W. Mellon Curator of Rare Books and Prints at the @folger.edu
amherst.wd5.myworkdayjobs.com/en-US/FSL_Em...
Andrew W. Mellon Curator of Rare Books and Prints at the @folger.edu
amherst.wd5.myworkdayjobs.com/en-US/FSL_Em...
Andrew W. Mellon Curator of Rare Books and Prints
The Folger Shakespeare Library knows that an exceptional staff is the backbone of any great organization. We hire exceptionally qualified individuals who are committed to the mission, vision, and valu...
amherst.wd5.myworkdayjobs.com
November 19, 2025 at 1:34 AM
JOB POSTING!
Andrew W. Mellon Curator of Rare Books and Prints at the @folger.edu
amherst.wd5.myworkdayjobs.com/en-US/FSL_Em...
Andrew W. Mellon Curator of Rare Books and Prints at the @folger.edu
amherst.wd5.myworkdayjobs.com/en-US/FSL_Em...
I may have read this paper a few times and I may have been very happy to see it come out in print


November 18, 2025 at 6:20 PM
I may have read this paper a few times and I may have been very happy to see it come out in print
Reposted by Heather Froehlich


I have been away for 3 weeks and the mail finally came - with @dorothyjberry.bsky.social’s new book from @wehere.bsky.social. Can’t wait to get stuck in

November 18, 2025 at 5:35 PM
I have been away for 3 weeks and the mail finally came - with @dorothyjberry.bsky.social’s new book from @wehere.bsky.social. Can’t wait to get stuck in