



Guilherme Duarte
@guilhermeduarte.bsky.social
Postdoc researcher, incoming Assistant Professor (@Harvard -- Government). PhD (@Wharton - @Penn). interests: causality, ML
Reposted by Guilherme Duarte

Fun exercise for students in a causal inference class: draw a DAG for this debate.

Look. It would be great if there was one simple trick for winning elections. But 'just be more moderate' isn't it.
In fact, you can use the NYT's exact method to 'prove' a 'Progressive Advantage' of +1.4 pts.
This piece shows what's really going on: funded candidates do better than unfunded ones.
In fact, you can use the NYT's exact method to 'prove' a 'Progressive Advantage' of +1.4 pts.
This piece shows what's really going on: funded candidates do better than unfunded ones.

The New York Times’ “Moderation Advantage” Is a Statistical Illusion
After accounting for money and incumbency the supposed electoral bonus for moderate candidates vanishes entirely.
open.substack.com
October 24, 2025 at 4:28 PM
Fun exercise for students in a causal inference class: draw a DAG for this debate.
Interesting response by @yiqingxu.bsky.social and others to @urisohn.bsky.social: arxiv.org/pdf/2502.05717 Causal inference is serious job. In Pearl's parlance, "define first, identify second, estimate last". If the 2 first parts are correct, one can use adaptive models in semiparametric fashion.
arxiv.org
February 11, 2025 at 3:41 PM
Interesting response by @yiqingxu.bsky.social and others to @urisohn.bsky.social: arxiv.org/pdf/2502.05717 Causal inference is serious job. In Pearl's parlance, "define first, identify second, estimate last". If the 2 first parts are correct, one can use adaptive models in semiparametric fashion.
Reposted by Guilherme Duarte

A very cool Econometrics Journal editorial by @jaapabbring.bsky.social, @victorchernozhukov.bsky.social & Fernandez-Val on Wright's 1928 contribution to causal inference and IV.
Very interesting stuff!
Link: arxiv.org/abs/2501.16395
Very interesting stuff!
Link: arxiv.org/abs/2501.16395

January 29, 2025 at 1:16 PM
A very cool Econometrics Journal editorial by @jaapabbring.bsky.social, @victorchernozhukov.bsky.social & Fernandez-Val on Wright's 1928 contribution to causal inference and IV.
Very interesting stuff!
Link: arxiv.org/abs/2501.16395
Very interesting stuff!
Link: arxiv.org/abs/2501.16395
Reposted by Guilherme Duarte

Here are the first five sets of slides:
01 Introduction: psantanna.com/DiD/01_Intro...
02 Classical 2x2 setup: psantanna.com/DiD/02_two_b...
03 Clustering issues: psantanna.com/DiD/03_Clust...
04 Functional form: psantanna.com/DiD/04_Funct...
05 Covariates: psantanna.com/DiD/05_Covar...
01 Introduction: psantanna.com/DiD/01_Intro...
02 Classical 2x2 setup: psantanna.com/DiD/02_two_b...
03 Clustering issues: psantanna.com/DiD/03_Clust...
04 Functional form: psantanna.com/DiD/04_Funct...
05 Covariates: psantanna.com/DiD/05_Covar...
December 30, 2024 at 5:19 AM
Here are the first five sets of slides:
01 Introduction: psantanna.com/DiD/01_Intro...
02 Classical 2x2 setup: psantanna.com/DiD/02_two_b...
03 Clustering issues: psantanna.com/DiD/03_Clust...
04 Functional form: psantanna.com/DiD/04_Funct...
05 Covariates: psantanna.com/DiD/05_Covar...
01 Introduction: psantanna.com/DiD/01_Intro...
02 Classical 2x2 setup: psantanna.com/DiD/02_two_b...
03 Clustering issues: psantanna.com/DiD/03_Clust...
04 Functional form: psantanna.com/DiD/04_Funct...
05 Covariates: psantanna.com/DiD/05_Covar...
I am thrilled to announce that I will be joining Department of Government at Harvard University, first as a postdoctoral fellow (2025) and then as an assistant professor (2026). I am grateful and really excited for this new opportunity.
December 17, 2024 at 3:14 PM
I am thrilled to announce that I will be joining Department of Government at Harvard University, first as a postdoctoral fellow (2025) and then as an assistant professor (2026). I am grateful and really excited for this new opportunity.
Reposted by Guilherme Duarte

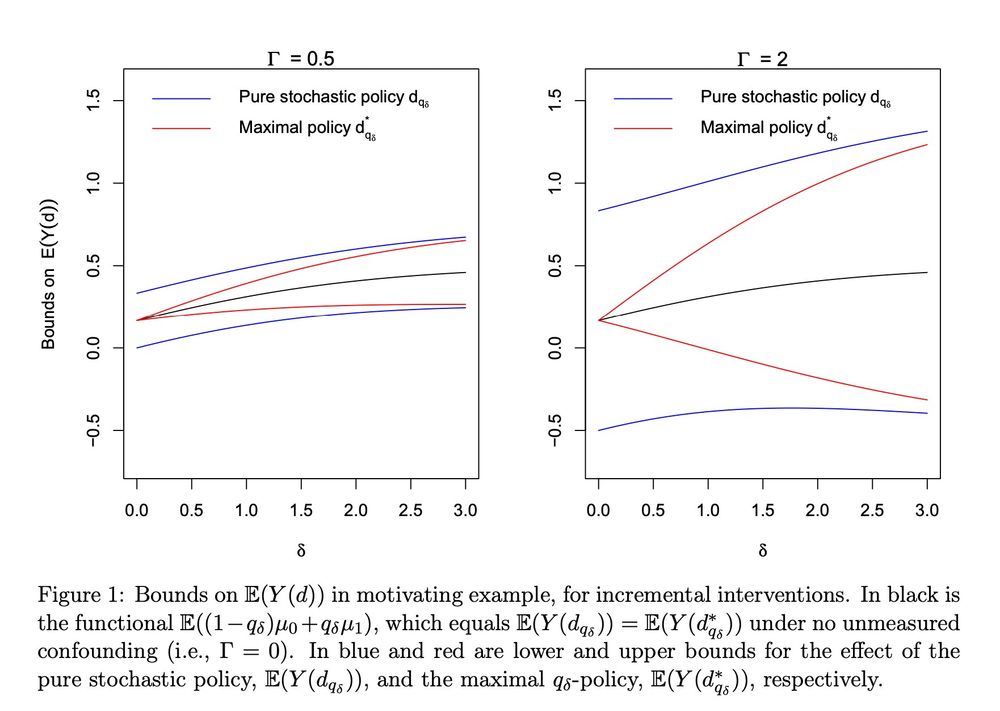
New paper! arxiv.org/pdf/2411.14285
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport



November 22, 2024 at 4:39 AM
New paper! arxiv.org/pdf/2411.14285
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
Led by amazing postdoc Alex Levis: www.awlevis.com/about/
We show causal effects of new "soft" interventions are less sensitive to unmeasured confounding
& study which effects are *least* sensitive to confounding -> makes new connections to optimal transport
Reposted by Guilherme Duarte


Reposted by Guilherme Duarte

#Rstats `MatchIt` v4.6.0 is out! `MatchIt` implements propensity score matching and other matching methods for causal effect estimation. This isn't a major release, but here are the main updates: 🧵
#causalsky #econsky #episky #statsky
#causalsky #econsky #episky #statsky
November 16, 2024 at 6:16 PM
#Rstats `MatchIt` v4.6.0 is out! `MatchIt` implements propensity score matching and other matching methods for causal effect estimation. This isn't a major release, but here are the main updates: 🧵
#causalsky #econsky #episky #statsky
#causalsky #econsky #episky #statsky
Reposted by Guilherme Duarte

I made a starter-pack for Statistics and Statistics-related groups, departments or organisations. Please share, and suggest accounts that I have missed.
go.bsky.app/q6MfWL
go.bsky.app/q6MfWL
November 15, 2024 at 10:23 AM
I made a starter-pack for Statistics and Statistics-related groups, departments or organisations. Please share, and suggest accounts that I have missed.
go.bsky.app/q6MfWL
go.bsky.app/q6MfWL
Reposted by Guilherme Duarte

Econ has some ML gems. One of my favorite's is Sandroni's sweeping result that no empirical test can distinguish an informed from an uninformed forecaster. I teach it in my ML class: www.youtube.com/watch?v=7OAI... But it is presented as negative, when it is in fact a sweeping positive result.

CIS 6200: Learning with Conditional Guarantees, Lecture 21.
YouTube video by Aaron Roth
www.youtube.com
November 15, 2024 at 1:18 PM
Econ has some ML gems. One of my favorite's is Sandroni's sweeping result that no empirical test can distinguish an informed from an uninformed forecaster. I teach it in my ML class: www.youtube.com/watch?v=7OAI... But it is presented as negative, when it is in fact a sweeping positive result.
Reposted by Guilherme Duarte

(brand new, WIP) python package for synthetic control estimators with a fast weight solver (pyensmallen). Currently implements jacknife CIs since inference in single-treated setting is basically made up anyway.
hope this passes muster, @paulgp.com ?
github.com/apoorvalal/s...
hope this passes muster, @paulgp.com ?
github.com/apoorvalal/s...

GitHub - apoorvalal/synthlearners: fast synthetic control estimators for panel data problems
fast synthetic control estimators for panel data problems - apoorvalal/synthlearners
github.com
November 12, 2024 at 4:09 PM
(brand new, WIP) python package for synthetic control estimators with a fast weight solver (pyensmallen). Currently implements jacknife CIs since inference in single-treated setting is basically made up anyway.
hope this passes muster, @paulgp.com ?
github.com/apoorvalal/s...
hope this passes muster, @paulgp.com ?
github.com/apoorvalal/s...
Reposted by Guilherme Duarte

"Recent Developments in Partial Identification" by Kline and Tamer (2023). #stats 📉📈
For those curious about Manski bounds and partial identification more generally, a nice review!
Open access: www.annualreviews.org/content/jour...
For those curious about Manski bounds and partial identification more generally, a nice review!
Open access: www.annualreviews.org/content/jour...

October 22, 2024 at 11:33 AM
"Recent Developments in Partial Identification" by Kline and Tamer (2023). #stats 📉📈
For those curious about Manski bounds and partial identification more generally, a nice review!
Open access: www.annualreviews.org/content/jour...
For those curious about Manski bounds and partial identification more generally, a nice review!
Open access: www.annualreviews.org/content/jour...
Reposted by Guilherme Duarte

The only part of Twitter worth preserving are those Wooldridge threads on Poisson QMLE.
September 18, 2024 at 12:13 AM
The only part of Twitter worth preserving are those Wooldridge threads on Poisson QMLE.
Reposted by Guilherme Duarte

🚨GRAVE: usuário do Bluesky cria lista que permite bloquear de uma vez uma penca de perfis caça-clique que espalham fofoca, exagero, inutilidade e desinformação.
bsky.app/profile/did:...
bsky.app/profile/did:...
September 1, 2024 at 11:43 AM
🚨GRAVE: usuário do Bluesky cria lista que permite bloquear de uma vez uma penca de perfis caça-clique que espalham fofoca, exagero, inutilidade e desinformação.
bsky.app/profile/did:...
bsky.app/profile/did:...
Reposted by Guilherme Duarte

I, of course, would never pander to the delightful new community of folks joining Bluesky by pointing out that Brazilian mayoral elections are a major use case for difference-in-differences methods.
🚨 Job Market Paper alert!
"How Much Should We Trust Modern Difference-in-Differences Estimates?" at osf.io/bqmws
I assess the fit between modern DID-style estimators and real-world data features, and point to approaches for improving inference.
Quick thread ⬇️
"How Much Should We Trust Modern Difference-in-Differences Estimates?" at osf.io/bqmws
I assess the fit between modern DID-style estimators and real-world data features, and point to approaches for improving inference.
Quick thread ⬇️

August 31, 2024 at 7:07 PM
I, of course, would never pander to the delightful new community of folks joining Bluesky by pointing out that Brazilian mayoral elections are a major use case for difference-in-differences methods.
A starter pack with causal inference I know. Unsure if this is the correct way of doing this, but I'm learning go.bsky.app/FdemGAZ
September 1, 2024 at 12:48 AM
A starter pack with causal inference I know. Unsure if this is the correct way of doing this, but I'm learning go.bsky.app/FdemGAZ
Based on this skeet by @stephenjwild.bsky.social , I will start a skeet thread on free resources for causal inference I know.
First one is obviously this recent book by Peng Ding. Strengths of this book are the focus on statistical inference (randomization, matching, and sensitivity analysis).
First one is obviously this recent book by Peng Ding. Strengths of this book are the focus on statistical inference (randomization, matching, and sensitivity analysis).
If you want a sneak peak of the whole book: arxiv.org/abs/2305.18793
I prefer physical copies, but I won't hold it against anyone who prefers electronic versions.
I prefer physical copies, but I won't hold it against anyone who prefers electronic versions.

A First Course in Causal Inference
I developed the lecture notes based on my ``Causal Inference'' course at the University of California Berkeley over the past seven years. Since half of the students were undergraduates, my lecture...
arxiv.org
August 31, 2024 at 11:42 PM
Based on this skeet by @stephenjwild.bsky.social , I will start a skeet thread on free resources for causal inference I know.
First one is obviously this recent book by Peng Ding. Strengths of this book are the focus on statistical inference (randomization, matching, and sensitivity analysis).
First one is obviously this recent book by Peng Ding. Strengths of this book are the focus on statistical inference (randomization, matching, and sensitivity analysis).
Reposted by Guilherme Duarte

Where are the causality people?

Any stats or machine learning researchers in Blue Sky?
August 31, 2024 at 11:28 PM
Where are the causality people?
Any stats or machine learning researchers in Blue Sky?
August 31, 2024 at 11:24 PM
Where are the causality people?
Reposted by Guilherme Duarte

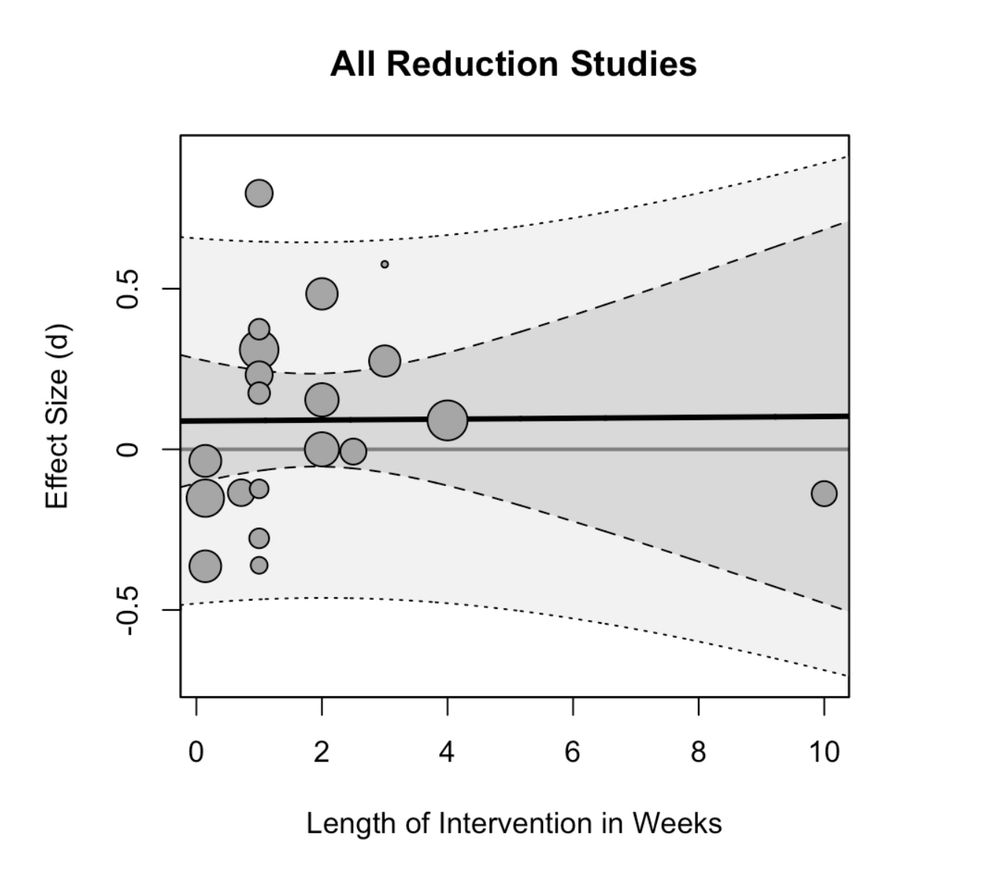
My blog post critical of this re-analysis is up: matthewbjane.com/blog-posts/blo…
The re-analysis conducted by Rausch & Haidt does not follow a principled statistical approach. I re-do their re-analysis with appropriate statistical methods
The re-analysis conducted by Rausch & Haidt does not follow a principled statistical approach. I re-do their re-analysis with appropriate statistical methods
August 30, 2024 at 9:06 PM
My blog post critical of this re-analysis is up: matthewbjane.com/blog-posts/blo…
The re-analysis conducted by Rausch & Haidt does not follow a principled statistical approach. I re-do their re-analysis with appropriate statistical methods
The re-analysis conducted by Rausch & Haidt does not follow a principled statistical approach. I re-do their re-analysis with appropriate statistical methods
Reposted by Guilherme Duarte

Pra quem ta chegando agora, pf usem o mesmo avatar que tinham na outra rede por enquanto.
August 31, 2024 at 4:03 PM
Pra quem ta chegando agora, pf usem o mesmo avatar que tinham na outra rede por enquanto.
Reposted by Guilherme Duarte
