



Donald Szlosek
@dszlosek.bsky.social
Biostatistician @IDEXX formerly at harvardmed, @BIDMChealth, @nasa. Big data, clinical trials, and medical diagnostics. Mainer. Opinions are my own. he/him
A good title for a chapter on estimation: "What to expect when you're expectation value"
December 8, 2025 at 4:41 PM
A good title for a chapter on estimation: "What to expect when you're expectation value"
Translating written / whiteboard statistics to Latex is still an incredibly painful experience. #academicsky #mathsky #statssky
December 7, 2025 at 11:16 PM
Translating written / whiteboard statistics to Latex is still an incredibly painful experience. #academicsky #mathsky #statssky
Reposted by Donald Szlosek

One thing @statberry.bsky.social does a lot that we should all be doing more is showing investigators the results of simulating their trial several times. When you know the true treatment effect but you get wild estimates with non-large N it usually gets their attention.
December 1, 2025 at 12:54 PM
One thing @statberry.bsky.social does a lot that we should all be doing more is showing investigators the results of simulating their trial several times. When you know the true treatment effect but you get wild estimates with non-large N it usually gets their attention.
I didn't realize this until the other day but I usually keep matches and a candle on my coffee table (an old wooden chest) and it is essentially all the ingredients you need to estimate pi and solve Buffons Needle problem. I can't unsee it now. My poor future houseguests. #statssky #statistics #math

November 30, 2025 at 3:33 PM
I didn't realize this until the other day but I usually keep matches and a candle on my coffee table (an old wooden chest) and it is essentially all the ingredients you need to estimate pi and solve Buffons Needle problem. I can't unsee it now. My poor future houseguests. #statssky #statistics #math
Reposted by Donald Szlosek

#rstats
It is with profound sadness I heard that my long-time friend and colleague, John Fox passed away this week.
He was the author of {car}, {effects}, {Rcmdr}, ... and numerous influential books. I will miss him greatly.
www.john-fox.ca
It is with profound sadness I heard that my long-time friend and colleague, John Fox passed away this week.
He was the author of {car}, {effects}, {Rcmdr}, ... and numerous influential books. I will miss him greatly.
www.john-fox.ca
John Fox: Books and Software
www.john-fox.ca
November 28, 2025 at 3:26 PM
#rstats
It is with profound sadness I heard that my long-time friend and colleague, John Fox passed away this week.
He was the author of {car}, {effects}, {Rcmdr}, ... and numerous influential books. I will miss him greatly.
www.john-fox.ca
It is with profound sadness I heard that my long-time friend and colleague, John Fox passed away this week.
He was the author of {car}, {effects}, {Rcmdr}, ... and numerous influential books. I will miss him greatly.
www.john-fox.ca
Interesting move of a preprint server to ban papers on AI, apparently due to record numbers of submissions of which low quality content was generated using AI #academicsky #AI #statssky

1. Pausing new submissions about AI topics for 90 days. That is, papers about AI models, testing AI models, proposing AI models, theories about the future of AI, etc. We will make exceptions for papers that are already accepted for publication (or published) in peer-reviewed scholarly journals
/2
/2

November 27, 2025 at 8:37 PM
Interesting move of a preprint server to ban papers on AI, apparently due to record numbers of submissions of which low quality content was generated using AI #academicsky #AI #statssky
This whole interaction. Is exactly why I am on this platform. Experts, discussing and debating. Sharing resources. 👏 👏 More of this please

Why does every target trial emulation study have to include a bit that says "this shows how great target trial emulation is. RCTs are non-generalisable and expensive"? Imagine if every RCT said "this shows how great RCTs are. We did not have to rely on strong, untestable assumptions".
November 27, 2025 at 4:18 PM
This whole interaction. Is exactly why I am on this platform. Experts, discussing and debating. Sharing resources. 👏 👏 More of this please
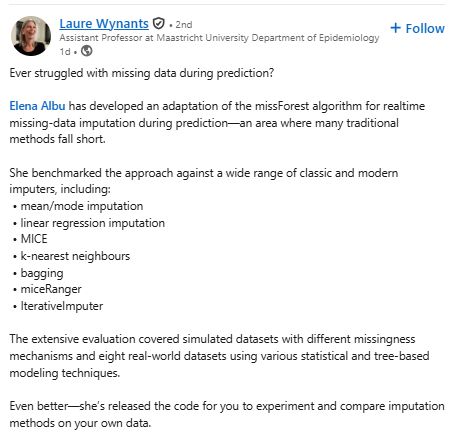
Because @laurewynants.bsky.social and @benvancalster.bsky.social do no get on here much #DataScience #MachineLearning #MissingData #Imputation #Rstats #Python #AI journals.plos.org/plosone/arti...
November 23, 2025 at 2:08 PM
Because @laurewynants.bsky.social and @benvancalster.bsky.social do no get on here much #DataScience #MachineLearning #MissingData #Imputation #Rstats #Python #AI journals.plos.org/plosone/arti...
Reposted by Donald Szlosek

One of the most upsetting articles I've read in a long time www.theargumentmag.com/p/when-grade...
UCSD report senate.ucsd.edu/media/740347...
We are failing a generation of kids.
UCSD report senate.ucsd.edu/media/740347...
We are failing a generation of kids.

When grades stop meaning anything
The UC San Diego math scandal is a warning
www.theargumentmag.com
November 19, 2025 at 2:05 AM
One of the most upsetting articles I've read in a long time www.theargumentmag.com/p/when-grade...
UCSD report senate.ucsd.edu/media/740347...
We are failing a generation of kids.
UCSD report senate.ucsd.edu/media/740347...
We are failing a generation of kids.
Reposted by Donald Szlosek

@f2harrell.bsky.social you were right. Coverage for TMLE xgboost grid search size 5 appeared better than 20 but still the coverage is disappointing. I’ve updated this examination for my learning. Thanks again for the guidance. www.kenkoonwong.com/blog/tmle/

November 22, 2025 at 11:52 PM
@f2harrell.bsky.social you were right. Coverage for TMLE xgboost grid search size 5 appeared better than 20 but still the coverage is disappointing. I’ve updated this examination for my learning. Thanks again for the guidance. www.kenkoonwong.com/blog/tmle/
I was thinking about the efficiency of nonparametric tests and remembered this SO post about the Wilcox being 96% as efficient as T test, even in small samples. For those who have a copy, Lehman & Romano did an thorough job in <5 pages detailing situation. #statssky #statistics #rstats #AcademicSky

November 21, 2025 at 1:22 PM
I was thinking about the efficiency of nonparametric tests and remembered this SO post about the Wilcox being 96% as efficient as T test, even in small samples. For those who have a copy, Lehman & Romano did an thorough job in <5 pages detailing situation. #statssky #statistics #rstats #AcademicSky
Reposted by Donald Szlosek

We wrote the Strain on scientific publishing to highlight the problems of time & trust. With a fantastic group of co-authors, we present The Drain of Scientific Publishing:
a 🧵 1/n
Drain: arxiv.org/abs/2511.04820
Strain: direct.mit.edu/qss/article/...
Oligopoly: direct.mit.edu/qss/article/...
a 🧵 1/n
Drain: arxiv.org/abs/2511.04820
Strain: direct.mit.edu/qss/article/...
Oligopoly: direct.mit.edu/qss/article/...




November 11, 2025 at 11:52 AM
We wrote the Strain on scientific publishing to highlight the problems of time & trust. With a fantastic group of co-authors, we present The Drain of Scientific Publishing:
a 🧵 1/n
Drain: arxiv.org/abs/2511.04820
Strain: direct.mit.edu/qss/article/...
Oligopoly: direct.mit.edu/qss/article/...
a 🧵 1/n
Drain: arxiv.org/abs/2511.04820
Strain: direct.mit.edu/qss/article/...
Oligopoly: direct.mit.edu/qss/article/...
I have been a reviewer on 5 papers this year for AI/ML validation and each time they used R or R Squared. Had to request a Bier Score, Emax, even slope and intercept would be more ideal. Would be nice if ICI was more popular too


November 18, 2025 at 6:02 PM
I have been a reviewer on 5 papers this year for AI/ML validation and each time they used R or R Squared. Had to request a Bier Score, Emax, even slope and intercept would be more ideal. Would be nice if ICI was more popular too
Reposted by Donald Szlosek
Survey Statistics: weights and MRP for voters
statmodeling.stat.columbia.edu/2025/11/11/s...
statmodeling.stat.columbia.edu/2025/11/11/s...
Survey Statistics: weights and MRP for voters | Statistical Modeling, Causal Inference, and Social Science
statmodeling.stat.columbia.edu
November 12, 2025 at 10:05 PM
Survey Statistics: weights and MRP for voters
statmodeling.stat.columbia.edu/2025/11/11/s...
statmodeling.stat.columbia.edu/2025/11/11/s...
It’s fascinating how cohorts of statisticians have parallel pockets of hyper-specific knowledge due to textbooks, like the collective familiarity with blue fiddler crab mating patterns, courtesy of Agresti. Palmer penguins, iris data, ect, any others I'm missing? #statssky #statistics #rstats
November 12, 2025 at 5:09 PM
It’s fascinating how cohorts of statisticians have parallel pockets of hyper-specific knowledge due to textbooks, like the collective familiarity with blue fiddler crab mating patterns, courtesy of Agresti. Palmer penguins, iris data, ect, any others I'm missing? #statssky #statistics #rstats
Reposted by Donald Szlosek

Well, it's official. #UNL Chancellor Bennett submitted his final proposal and it includes eliminating the #statistics department. budgetprocess.unl.edu/final-budget...
Guess it's time to go look for jobs. Anyone looking for a couple of very talented #datavis researchers?
Guess it's time to go look for jobs. Anyone looking for a couple of very talented #datavis researchers?
Final Budget Reduction Plan | Budget Process | Nebraska
budgetprocess.unl.edu
November 10, 2025 at 10:09 PM
Well, it's official. #UNL Chancellor Bennett submitted his final proposal and it includes eliminating the #statistics department. budgetprocess.unl.edu/final-budget...
Guess it's time to go look for jobs. Anyone looking for a couple of very talented #datavis researchers?
Guess it's time to go look for jobs. Anyone looking for a couple of very talented #datavis researchers?
Reposted by Donald Szlosek

Quick thread on the BBC and the political and societal significance of recent developments:
One of the main reasons the UK has historically been so much less polarised than the US, is that Britain has a shared source of information, consumed and trusted by most people regardless of their politics.
One of the main reasons the UK has historically been so much less polarised than the US, is that Britain has a shared source of information, consumed and trusted by most people regardless of their politics.

November 10, 2025 at 1:43 PM
Quick thread on the BBC and the political and societal significance of recent developments:
One of the main reasons the UK has historically been so much less polarised than the US, is that Britain has a shared source of information, consumed and trusted by most people regardless of their politics.
One of the main reasons the UK has historically been so much less polarised than the US, is that Britain has a shared source of information, consumed and trusted by most people regardless of their politics.
One thing I have noticed a lot in meta-analysis (thinking of those involving comparison of prognostic models) is that most focus on Embase and Medline, but no mention of Compendium (think IEEE) WoS or Scopus. Granted the sheer volume for data extraction would be astronomical.

OK So here’s a list of errors in meta-analysis in (mainly) Cochrane Collaboration work. bmcmedresmethodol.biomedcentral.com/articles/10....
I don’t think any of them have been withdrawn. Which ones should have been?
I don’t think any of them have been withdrawn. Which ones should have been?

Overstating the evidence – double counting in meta-analysis and related problems - BMC Medical Research Methodology
Background The problem of missing studies in meta-analysis has received much attention. Less attention has been paid to the more serious problem of double counting of evidence. Methods Various problem...
bmcmedresmethodol.biomedcentral.com
November 8, 2025 at 7:21 PM
One thing I have noticed a lot in meta-analysis (thinking of those involving comparison of prognostic models) is that most focus on Embase and Medline, but no mention of Compendium (think IEEE) WoS or Scopus. Granted the sheer volume for data extraction would be astronomical.
Does anyone else automictically reach for the PDF symbol when opening a new article on a journal site? It just seems like I can read the them faster. #AcademicSky
November 8, 2025 at 2:31 PM
Does anyone else automictically reach for the PDF symbol when opening a new article on a journal site? It just seems like I can read the them faster. #AcademicSky
It's a shame I didn't find this before Oct. 31st. And also a shame the term "Ghost-time bias" never caught on.

November 7, 2025 at 6:16 PM
It's a shame I didn't find this before Oct. 31st. And also a shame the term "Ghost-time bias" never caught on.
Reposted by Donald Szlosek

NEW PAPER: "Reporting guidelines for studies involving generative artificial intelligence applications: what do I use, and when?"
--> www.nature.com/articles/s41...
#HealthTech #ClinicalAI #MachineLearning #MedAI #AIinMedicine #TransparentAI #HealthInnovation #GenAI
--> www.nature.com/articles/s41...
#HealthTech #ClinicalAI #MachineLearning #MedAI #AIinMedicine #TransparentAI #HealthInnovation #GenAI

November 7, 2025 at 12:44 PM
NEW PAPER: "Reporting guidelines for studies involving generative artificial intelligence applications: what do I use, and when?"
--> www.nature.com/articles/s41...
#HealthTech #ClinicalAI #MachineLearning #MedAI #AIinMedicine #TransparentAI #HealthInnovation #GenAI
--> www.nature.com/articles/s41...
#HealthTech #ClinicalAI #MachineLearning #MedAI #AIinMedicine #TransparentAI #HealthInnovation #GenAI
Probably the papers I share the most often are @f2harrell.bsky.social 1996 on how to effectively develop multivariate models and @benvancalster.bsky.social 2019 paper on Calibration. Both extremely well written and informative. What are you most shared stats paper? #statistics #statssky #academicsky

November 7, 2025 at 12:12 PM
Probably the papers I share the most often are @f2harrell.bsky.social 1996 on how to effectively develop multivariate models and @benvancalster.bsky.social 2019 paper on Calibration. Both extremely well written and informative. What are you most shared stats paper? #statistics #statssky #academicsky
I recently rederived the poisson pdf distribution from the binomial. Reminds me of @kareemcarr.bsky.social recent blog about memorization vs proof. No computer around and needed it for something. Certainly there are times where knowing something will be time saving then re-deriving it from scratch.
November 6, 2025 at 1:21 PM
I recently rederived the poisson pdf distribution from the binomial. Reminds me of @kareemcarr.bsky.social recent blog about memorization vs proof. No computer around and needed it for something. Certainly there are times where knowing something will be time saving then re-deriving it from scratch.
Reposted by Donald Szlosek

Can Game Theory Help Us with Causal Discovery?
What's Your Guess?
In this week's issue of Causal Python Weekly, expect a solid mix of history, fresh discoveries, and good teaching:
1/
#CausalSky #EconSky #StatSky #MLSky #EpiSky
What's Your Guess?
In this week's issue of Causal Python Weekly, expect a solid mix of history, fresh discoveries, and good teaching:
1/
#CausalSky #EconSky #StatSky #MLSky #EpiSky

November 2, 2025 at 10:19 AM
Can Game Theory Help Us with Causal Discovery?
What's Your Guess?
In this week's issue of Causal Python Weekly, expect a solid mix of history, fresh discoveries, and good teaching:
1/
#CausalSky #EconSky #StatSky #MLSky #EpiSky
What's Your Guess?
In this week's issue of Causal Python Weekly, expect a solid mix of history, fresh discoveries, and good teaching:
1/
#CausalSky #EconSky #StatSky #MLSky #EpiSky
Reposted by Donald Szlosek

We wrote an article explaining why you shouldn't put several variables into a regression model and report which are statistically significant - even as exploratory research. bmjmedicine.bmj.com/content/4/1/.... How did we do?

October 27, 2025 at 5:39 PM
We wrote an article explaining why you shouldn't put several variables into a regression model and report which are statistically significant - even as exploratory research. bmjmedicine.bmj.com/content/4/1/.... How did we do?