Matteo Paloni
@betterwithchem.bsky.social
470 followers
400 following
12 posts
PDRA at MME-UCL, previously PD at CBS-Montpellier ( @cbsmontpellier.bsky.social). Interested in MD simulations of order and chaos.
https://scholar.google.com/citations?user=fK55KfEAAAAJ&hl=en
Posts
Media
Videos
Starter Packs
Pinned



Reposted by Matteo Paloni



Reposted by Matteo Paloni


Reposted by Matteo Paloni




Reposted by Matteo Paloni


Reposted by Matteo Paloni

Reposted by Matteo Paloni



Reposted by Matteo Paloni
Reposted by Matteo Paloni

David Emmett
@motomatters.com
· Sep 13
Reposted by Matteo Paloni




Reposted by Matteo Paloni



Reposted by Matteo Paloni


Reposted by Matteo Paloni


Reposted by Matteo Paloni





Reposted by Matteo Paloni
Reposted by Matteo Paloni


Reposted by Matteo Paloni


Reposted by Matteo Paloni

SpruijtLab
@spruijtlab.bsky.social
· Jul 16

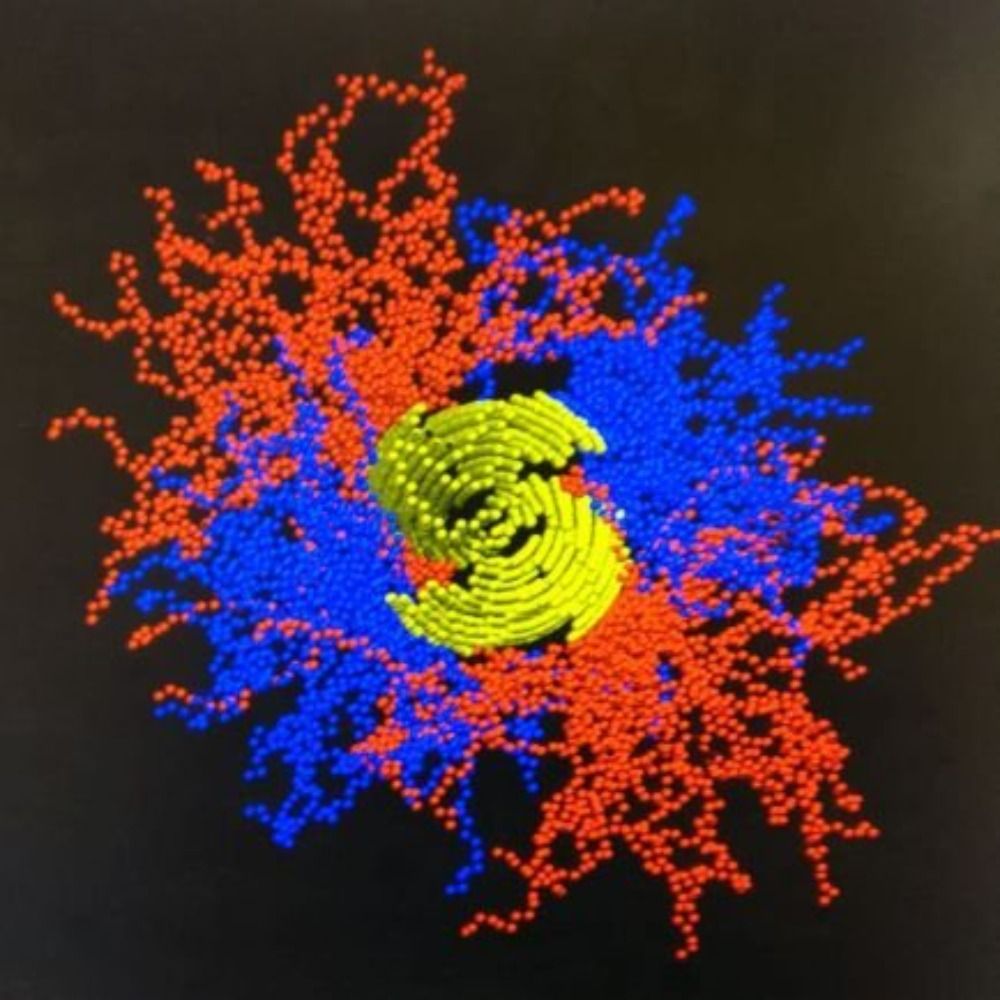
Selective Ion Binding and Uptake Shape the Microenvironment of Biomolecular Condensates
Biomolecular condensates modulate various ion-dependent cellular processes and can regulate subcellular ion distributions by selective uptake of ions. To understand these processes, it is essential to...
doi.org
Reposted by Matteo Paloni


Reposted by Matteo Paloni

Reposted by Matteo Paloni

Reposted by Matteo Paloni