



Andrea Mariani
@andreamariani.bsky.social
PhD Student in Systems Medicine | Comp Bio | Genomics and seq2function models | Biology is stochastic
Pinned
Andrea Mariani
@andreamariani.bsky.social
· Feb 17
Hey #Genomics people, I need ur help. I have a goal, wanna learn Polycomb complex’s regulatory (repression) syntax. I’m using DL models like BPNet (from @juliazeitlinger.bsky.social @anshulkundaje.bsky.social labs) but syntax is not as clear as for pioneering TFs.
Reposted by Andrea Mariani

Last week I released bpnet-lite v0.5.0.
BPNet/ChromBPNet are powerful models for understanding regulatory genomics from @anshulkundaje.bsky.social's group, and now it's way easier to go from raw data to trained models and analysis + results in PyTorch
Try it out with `pip install bpnet-lite`
BPNet/ChromBPNet are powerful models for understanding regulatory genomics from @anshulkundaje.bsky.social's group, and now it's way easier to go from raw data to trained models and analysis + results in PyTorch
Try it out with `pip install bpnet-lite`
June 18, 2025 at 9:48 AM
Last week I released bpnet-lite v0.5.0.
BPNet/ChromBPNet are powerful models for understanding regulatory genomics from @anshulkundaje.bsky.social's group, and now it's way easier to go from raw data to trained models and analysis + results in PyTorch
Try it out with `pip install bpnet-lite`
BPNet/ChromBPNet are powerful models for understanding regulatory genomics from @anshulkundaje.bsky.social's group, and now it's way easier to go from raw data to trained models and analysis + results in PyTorch
Try it out with `pip install bpnet-lite`
Reposted by Andrea Mariani

Regulatory sequence ML has been widely applied to predict substitution SNP effects (to promising results!), but most teams have shied away from indels. www.biorxiv.org/content/10.1...

Shift augmentation improves DNA convolutional neural network indel effect predictions
Determining genetic variant effects on molecular phenotypes like gene expression is a task of paramount importance to medical genetics. DNA convolutional neural networks (CNNs) attain state-of-the-art...
www.biorxiv.org
April 17, 2025 at 12:39 AM
Regulatory sequence ML has been widely applied to predict substitution SNP effects (to promising results!), but most teams have shied away from indels. www.biorxiv.org/content/10.1...
Reposted by Andrea Mariani

Our new preprint is out! Want to better visualize what your sequence-to-function profile learned? Here is PISA. It also comes in a new BPNet package, which can be used to train many genomics data sets, including MNase-seq data.

PISA: a versatile interpretation tool for visualizing cis-regulatory rules in genomic data https://www.biorxiv.org/content/10.1101/2025.04.07.647613v1
April 8, 2025 at 1:31 PM
Our new preprint is out! Want to better visualize what your sequence-to-function profile learned? Here is PISA. It also comes in a new BPNet package, which can be used to train many genomics data sets, including MNase-seq data.
Reposted by Andrea Mariani


Reposted by Andrea Mariani

Deep Learning is Not So Mysterious or Different - arxiv.org/abs/2503.02113
Section 8, listing properties unique to neural networks, is quite interesting.
Section 8, listing properties unique to neural networks, is quite interesting.

Deep Learning is Not So Mysterious or Different
Deep neural networks are often seen as different from other model classes by defying conventional notions of generalization. Popular examples of anomalous generalization behaviour include benign overf...
arxiv.org
March 17, 2025 at 7:20 PM
Deep Learning is Not So Mysterious or Different - arxiv.org/abs/2503.02113
Section 8, listing properties unique to neural networks, is quite interesting.
Section 8, listing properties unique to neural networks, is quite interesting.
Reposted by Andrea Mariani

Our new pre-print, investigating a few important questions when we train S2F models on different types of MPRA datasets. Congrats to Yilun and @xinmingtu.bsky.social www.biorxiv.org/content/10.1...

Investigating Data Size, Sequence Diversity, and Model Complexity in MPRA-based Sequence-to-Function Prediction
We created the MPRA Dataset Collection (MDC), a curated resource of MPRA data from 12 studies comprising over 150 million labeled DNA subsequences. These datasets include both random and natural genom...
www.biorxiv.org
March 15, 2025 at 3:02 AM
Our new pre-print, investigating a few important questions when we train S2F models on different types of MPRA datasets. Congrats to Yilun and @xinmingtu.bsky.social www.biorxiv.org/content/10.1...
Reposted by Andrea Mariani

*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
March 10, 2025 at 6:14 PM
*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
Reposted by Andrea Mariani
Evaluation of deep learning approaches for high-resolution chromatin accessibility prediction from genomic sequence
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...

Evaluation of deep learning approaches for high-resolution chromatin accessibility prediction from genomic sequence
Accurately predicting high-resolution chromatin accessibility signals is crucial for precisely identifying regulatory elements and understanding their role in gene expression regulation. In the absenc...
www.biorxiv.org
March 7, 2025 at 7:55 AM
Evaluation of deep learning approaches for high-resolution chromatin accessibility prediction from genomic sequence
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Reposted by Andrea Mariani


Reposted by Andrea Mariani

Peto's Paradox—that cancer does not increase with body size of mammals—was wrong.
A new, comprehensive study of 263 species documents higher cancer prevalence with increasing body mass. Some large animals (e.g. elephants) have some built-in genetic adaptations
www.pnas.org/doi/10.1073/... @pnas.org
A new, comprehensive study of 263 species documents higher cancer prevalence with increasing body mass. Some large animals (e.g. elephants) have some built-in genetic adaptations
www.pnas.org/doi/10.1073/... @pnas.org
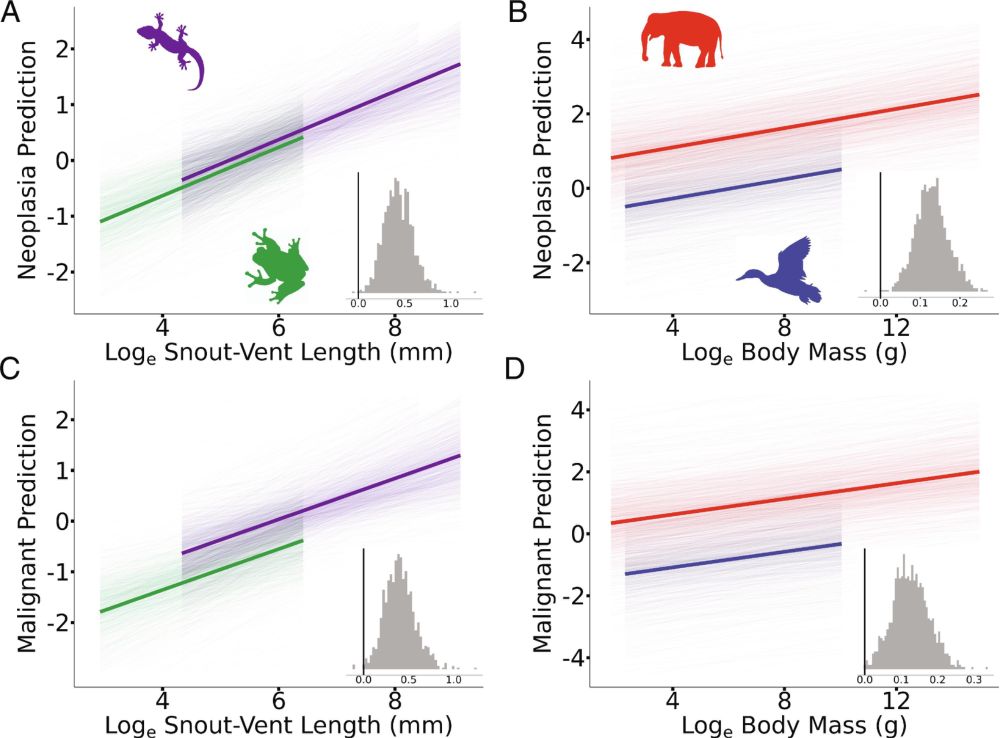
No evidence for Peto’s paradox in terrestrial vertebrates | PNAS
Larger, longer-lived species are expected to have a higher cancer prevalence compared
to smaller, shorter-lived species owing to the greater number...
www.pnas.org
February 25, 2025 at 6:15 PM
Peto's Paradox—that cancer does not increase with body size of mammals—was wrong.
A new, comprehensive study of 263 species documents higher cancer prevalence with increasing body mass. Some large animals (e.g. elephants) have some built-in genetic adaptations
www.pnas.org/doi/10.1073/... @pnas.org
A new, comprehensive study of 263 species documents higher cancer prevalence with increasing body mass. Some large animals (e.g. elephants) have some built-in genetic adaptations
www.pnas.org/doi/10.1073/... @pnas.org
Every single time there's a gigantic (read *expensive*) model that does stuff well, I have to keep in mind that i need to balance excitement and skepticism.

AI provides a universal framework that leverages data and compute at scale to uncover higher-order patterns
Today, @arcinstitute.org in collaboration with Nvidia releases Evo 2—a fully open source biological foundation model trained on genomes spanning the entire tree of life.
Today, @arcinstitute.org in collaboration with Nvidia releases Evo 2—a fully open source biological foundation model trained on genomes spanning the entire tree of life.

February 25, 2025 at 3:16 PM
Every single time there's a gigantic (read *expensive*) model that does stuff well, I have to keep in mind that i need to balance excitement and skepticism.
Reposted by Andrea Mariani
Probabilistic and machine-learning methods for predicting local rates of transcription elongation from nascent RNA sequencing data
academic.oup.com/nar/article/...
academic.oup.com/nar/article/...

Probabilistic and machine-learning methods for predicting local rates of transcription elongation from nascent RNA sequencing data
Abstract. Rates of transcription elongation vary within and across eukaryotic gene bodies. Here, we introduce new methods for predicting elongation rates f
academic.oup.com
February 22, 2025 at 3:51 PM
Probabilistic and machine-learning methods for predicting local rates of transcription elongation from nascent RNA sequencing data
academic.oup.com/nar/article/...
academic.oup.com/nar/article/...
Reposted by Andrea Mariani

Paper out !!🥳big thanks to all authors @marliesoomen.bsky.social @diego-rt.bsky.social @kaessmannlab.bsky.social @jonathangoeke.bsky.social @lorenzamottes.bsky.social & 'bluesky-less'
Lots of interesting new TE (& genes) biology
Data fully browsable💻 👉 embryo.helmholtz-munich.de/shiny_embryo/
Lots of interesting new TE (& genes) biology
Data fully browsable💻 👉 embryo.helmholtz-munich.de/shiny_embryo/
February 21, 2025 at 3:50 PM
Paper out !!🥳big thanks to all authors @marliesoomen.bsky.social @diego-rt.bsky.social @kaessmannlab.bsky.social @jonathangoeke.bsky.social @lorenzamottes.bsky.social & 'bluesky-less'
Lots of interesting new TE (& genes) biology
Data fully browsable💻 👉 embryo.helmholtz-munich.de/shiny_embryo/
Lots of interesting new TE (& genes) biology
Data fully browsable💻 👉 embryo.helmholtz-munich.de/shiny_embryo/
Hey #Genomics people, I need ur help. I have a goal, wanna learn Polycomb complex’s regulatory (repression) syntax. I’m using DL models like BPNet (from @juliazeitlinger.bsky.social @anshulkundaje.bsky.social labs) but syntax is not as clear as for pioneering TFs.
February 17, 2025 at 1:20 PM
Hey #Genomics people, I need ur help. I have a goal, wanna learn Polycomb complex’s regulatory (repression) syntax. I’m using DL models like BPNet (from @juliazeitlinger.bsky.social @anshulkundaje.bsky.social labs) but syntax is not as clear as for pioneering TFs.
Reposted by Andrea Mariani

(1/4) Thrilled to announce another major release of the HOCOMOCO motif collection, well-known for its silly name and rigorous approach to constructing and benchmarking DNA sequence motifs recognized by human and mouse transcription factors.
hocomoco.autosome.org
hocomoco.autosome.org

February 17, 2025 at 11:38 AM
(1/4) Thrilled to announce another major release of the HOCOMOCO motif collection, well-known for its silly name and rigorous approach to constructing and benchmarking DNA sequence motifs recognized by human and mouse transcription factors.
hocomoco.autosome.org
hocomoco.autosome.org
A great reminder that sequence context (i.e. flanking regions here), drive contact probability which we interpret as TFs binding strength.

Thermodynamic principles link in vitro transcription factor affinities to single-molecule chromatin states in cells www.biorxiv.org/content/10.1...
▶️40-fold flanking sequence effect on TF binding
▶️Motif recognition beats kinetics
▶️Minutes-long residence times
▶️Models of TF-nucleosome competiton
▶️40-fold flanking sequence effect on TF binding
▶️Motif recognition beats kinetics
▶️Minutes-long residence times
▶️Models of TF-nucleosome competiton




February 7, 2025 at 1:48 PM
A great reminder that sequence context (i.e. flanking regions here), drive contact probability which we interpret as TFs binding strength.
Reposted by Andrea Mariani

Literally prioritizing LLM parsing over human readability

"We shape our tools, and thereafter our tools shape us" 🫠


February 7, 2025 at 1:06 PM
Literally prioritizing LLM parsing over human readability
Sequence based models, homology, data leakage and other wonderful stories

0/ Essential reading for anyone training or using sequence-function models trained on genomic sequences! 🚨 In our new preprint, we explore the ways homology within genomes can cause leakage when training sequence-based models and ways to prevent it
January 28, 2025 at 5:42 PM
Sequence based models, homology, data leakage and other wonderful stories
Reposted by Andrea Mariani
Detecting and avoiding homology-based data leakage in genome-trained sequence models
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Detecting and avoiding homology-based data leakage in genome-trained sequence models
Models that predict function from DNA sequence have become critical tools in deciphering the roles of genomic sequences and genetic variation within them. However, traditional approaches for dividing ...
www.biorxiv.org
January 27, 2025 at 5:15 PM
Detecting and avoiding homology-based data leakage in genome-trained sequence models
www.biorxiv.org/content/10.1...
www.biorxiv.org/content/10.1...
Reposted by Andrea Mariani
Multiscale footprints reveal the organization of cis-regulatory elements
www.nature.com/articles/s41...
www.nature.com/articles/s41...
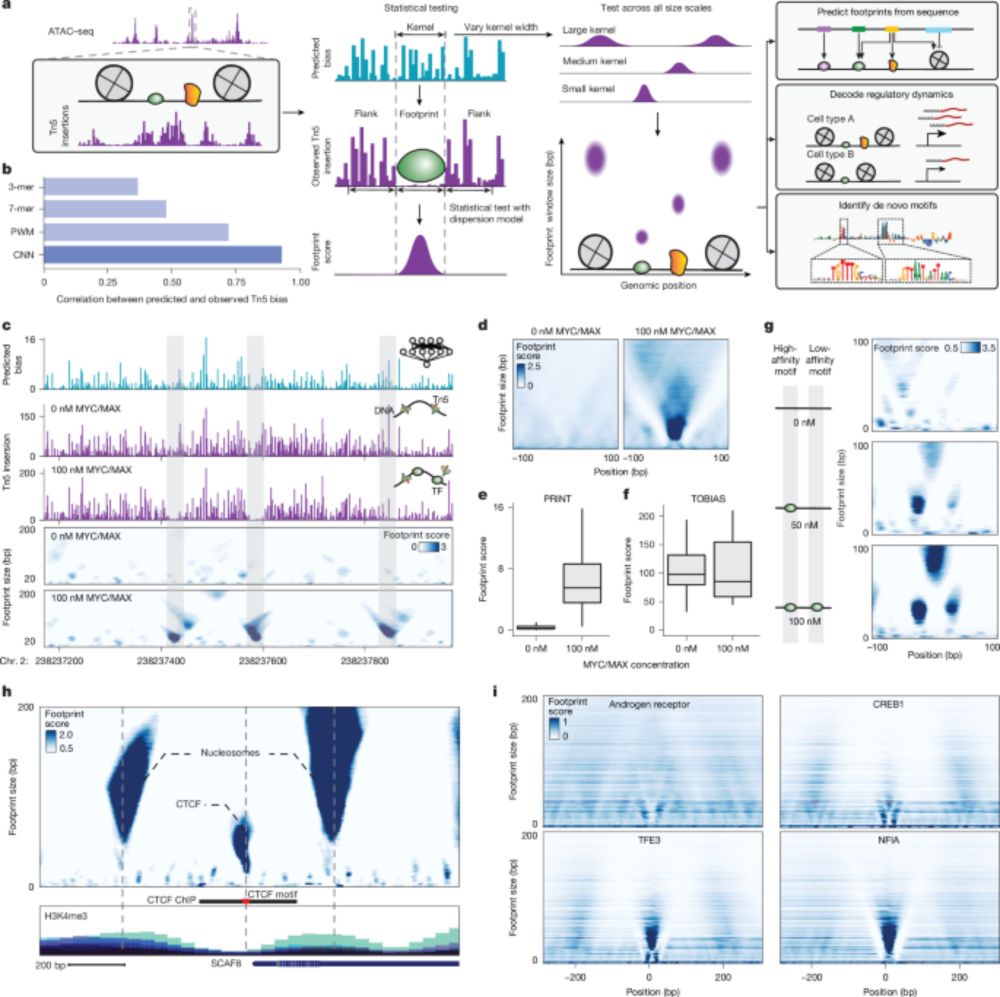
Multiscale footprints reveal the organization of cis-regulatory elements - Nature
We developed PRINT, a computational method that identifies footprints of DNA–protein interactions from bulk and single-cell chromatin accessibility data across multiple scales of protein size.
www.nature.com
January 22, 2025 at 8:21 PM
Multiscale footprints reveal the organization of cis-regulatory elements
www.nature.com/articles/s41...
www.nature.com/articles/s41...
A great repo on how to review papers i wish i'd found before. TL;DR don't be a jerk, be quick, be skeptic

I think one low cost, high impact intervention to improve peer review is training trainees on what peer review should look like. I wrote this guide for my students: github.com/jtleek/reviews that includes an opinionated approach to what is/isn't important in review (pretty computationally flavored)
December 13, 2024 at 3:52 PM
A great repo on how to review papers i wish i'd found before. TL;DR don't be a jerk, be quick, be skeptic
Reposted by Andrea Mariani

For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...

Writing a good scientific paper
perceiving-systems.blog
November 20, 2024 at 10:18 AM
For those who missed this post on the-network-that-is-not-to-be-named, I made public my "secrets" for writing a good CVPR paper (or any scientific paper). I've compiled these tips of many years. It's long but hopefully it helps people write better papers. perceiving-systems.blog/en/post/writ...
Sounds like a nice side quest

I taught some probabilistic programming yesterday, specifically the eternal battle against the demons of floating point arithmetic. I have an old (2023) 15 minute bonus lecture online on the topic, for those who fancy battling monsters. Link to video (starts at 1h mark): youtu.be/mt9WKbQJrI4?...

November 27, 2024 at 9:32 AM
Sounds like a nice side quest
Reposted by Andrea Mariani

To be fair to Seurat it’s really applicable to all of ggplot2 but amplified by single cell visuals with lots of groups on single plot.
scCustomize sets some better defaults that help with lots of the issues. :)
samuel-marsh.github.io/scCustomize/...
scCustomize sets some better defaults that help with lots of the issues. :)
samuel-marsh.github.io/scCustomize/...
Customized Color Palettes & Themes
scCustomize
samuel-marsh.github.io
November 25, 2024 at 9:51 PM
To be fair to Seurat it’s really applicable to all of ggplot2 but amplified by single cell visuals with lots of groups on single plot.
scCustomize sets some better defaults that help with lots of the issues. :)
samuel-marsh.github.io/scCustomize/...
scCustomize sets some better defaults that help with lots of the issues. :)
samuel-marsh.github.io/scCustomize/...