



ADA is a generalized version of C-Mixup that mixes multiple samples based on cluster membership, preserving nonlinear relationships in augmented regression data #dataaugmentation

Anchor Data Augmentation as a Generalized Variant of C-Mixup
hackernoon.com
November 14, 2024 at 7:30 PM
ADA is a generalized version of C-Mixup that mixes multiple samples based on cluster membership, preserving nonlinear relationships in augmented regression data #dataaugmentation

A study of 100+ configurations finds LLM‑generated synthetic data improves dual‑encoder retrieval, but gains taper after a point; even modest‑sized LLMs match larger ones. https://getnews.me/llm-data-augmentation-boosts-retrieval-performance-large-study-finds/ #llm #retrieval #dataaugmentation

September 24, 2025 at 6:35 AM
A study of 100+ configurations finds LLM‑generated synthetic data improves dual‑encoder retrieval, but gains taper after a point; even modest‑sized LLMs match larger ones. https://getnews.me/llm-data-augmentation-boosts-retrieval-performance-large-study-finds/ #llm #retrieval #dataaugmentation
This paper compares ADA's performance on out-of-distribution robustness tasks, highlighting its superiority with datasets like SkillCraft and RCFashionMNIST. #dataaugmentation
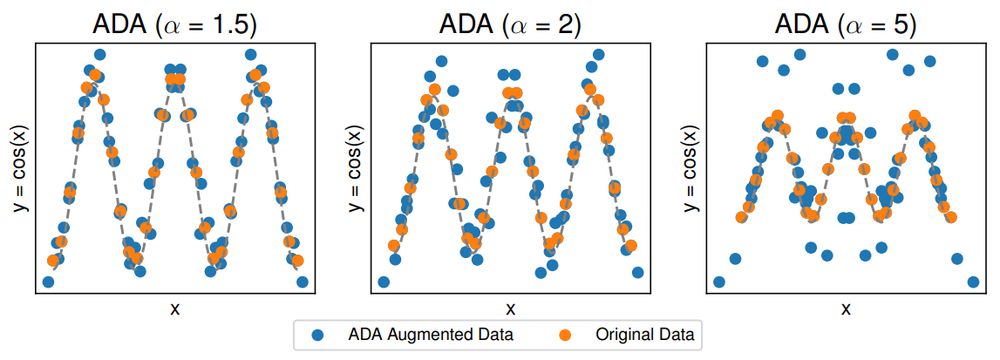
ADA's Impact on Out-of-Distribution Robustness
hackernoon.com
November 14, 2024 at 7:31 PM
This paper compares ADA's performance on out-of-distribution robustness tasks, highlighting its superiority with datasets like SkillCraft and RCFashionMNIST. #dataaugmentation
This paper explores various data augmentation methods, from human-designed domain-specific transformations to automated techniques using reinforcement learning. #dataaugmentation
November 14, 2024 at 7:30 PM
This paper explores various data augmentation methods, from human-designed domain-specific transformations to automated techniques using reinforcement learning. #dataaugmentation
This paper evaluates ADA's performance on in-distribution generalization tasks, comparing it to C-Mixup, Mixup, and other strategies. #dataaugmentation

ADA Outperforms ERM and Competes with C-Mixup in In-Distribution Generalization Tasks
hackernoon.com
November 14, 2024 at 7:31 PM
This paper evaluates ADA's performance on in-distribution generalization tasks, comparing it to C-Mixup, Mixup, and other strategies. #dataaugmentation
This paper presents experimental evaluations of ADA, comparing it with C-Mixup, vanilla augmentation, and classical risk minimization. #dataaugmentation

Evaluating ADA: Experimental Results on Linear and Housing Datasets
hackernoon.com
November 14, 2024 at 7:30 PM
This paper presents experimental evaluations of ADA, comparing it with C-Mixup, vanilla augmentation, and classical risk minimization. #dataaugmentation

Thinking about using #SyntheticData in your #MarketingResearch?
Good idea, but do it mindfully and in good balance with #DataAugmentation.
#DataInnovation #CrossDisciplinaryInsights #3StandardDeviations
Good idea, but do it mindfully and in good balance with #DataAugmentation.
#DataInnovation #CrossDisciplinaryInsights #3StandardDeviations

Cecilia Dones on LinkedIn: #dataaugmentation #syntheticdata #creative #inspired #marketingresearch…
❓ Have you ever been inspired by some research you're doing? NERD ALERT 🚨 I can get very excited by ideas and research and feel compelled to share. You've…
buff.ly
February 11, 2025 at 3:00 PM
Thinking about using #SyntheticData in your #MarketingResearch?
Good idea, but do it mindfully and in good balance with #DataAugmentation.
#DataInnovation #CrossDisciplinaryInsights #3StandardDeviations
Good idea, but do it mindfully and in good balance with #DataAugmentation.
#DataInnovation #CrossDisciplinaryInsights #3StandardDeviations

Tomorrow Prof. Jeremy Bradbury & MSc student Riddhi More will be presenting "FlakyXbert: A Few-Shot Learning Framework for Detecting and Classifying Flaky Tests" at the AI Meets Software Quality International Colloquium (bit.ly/42DAZ4M)
#AI #LLM #testing #flakytests #dataaugmentation #bias
#AI #LLM #testing #flakytests #dataaugmentation #bias

February 2, 2025 at 8:34 PM
Tomorrow Prof. Jeremy Bradbury & MSc student Riddhi More will be presenting "FlakyXbert: A Few-Shot Learning Framework for Detecting and Classifying Flaky Tests" at the AI Meets Software Quality International Colloquium (bit.ly/42DAZ4M)
#AI #LLM #testing #flakytests #dataaugmentation #bias
#AI #LLM #testing #flakytests #dataaugmentation #bias
This paper introduces Anchor Data Augmentation (ADA), a novel algorithm for enhancing nonlinear over-parameterized regression models. #dataaugmentation
November 14, 2024 at 7:29 PM
This paper introduces Anchor Data Augmentation (ADA), a novel algorithm for enhancing nonlinear over-parameterized regression models. #dataaugmentation
IPF‑RDA adds an information‑preserving layer to augmentation pipelines, boosting accuracy on CIFAR‑10, CIFAR‑100 and Tiny‑ImageNet. Code is open‑source on GitHub. Read more: https://getnews.me/ipf-rda-framework-boosts-robustness-of-data-augmentation-for-deep-learning/ #deeplearning #dataaugmentation

September 24, 2025 at 12:19 PM
IPF‑RDA adds an information‑preserving layer to augmentation pipelines, boosting accuracy on CIFAR‑10, CIFAR‑100 and Tiny‑ImageNet. Code is open‑source on GitHub. Read more: https://getnews.me/ipf-rda-framework-boosts-robustness-of-data-augmentation-for-deep-learning/ #deeplearning #dataaugmentation
Anchor Data Augmentation (ADA) is a domain-agnostic method for regression, using clustering to improve generalization with minimal computational cost. #dataaugmentation

Anchor Data Augmentation (ADA): A Domain-Agnostic Method for Enhancing Regression Models
hackernoon.com
November 14, 2024 at 7:30 PM
Anchor Data Augmentation (ADA) is a domain-agnostic method for regression, using clustering to improve generalization with minimal computational cost. #dataaugmentation
Quantum harmonic analysis shows data augmentation moves PCA eigenfunctions into modulation space M¹(ℝᵈ), making components smoother; synthetic and audio experiments confirm. Read more: https://getnews.me/data-augmentation-boosts-pca-smoothness-via-quantum-harmonic-analysis/ #dataaugmentation #pca

September 26, 2025 at 10:44 PM
Quantum harmonic analysis shows data augmentation moves PCA eigenfunctions into modulation space M¹(ℝᵈ), making components smoother; synthetic and audio experiments confirm. Read more: https://getnews.me/data-augmentation-boosts-pca-smoothness-via-quantum-harmonic-analysis/ #dataaugmentation #pca

We create synthetic data points that follow the patterns in your dataset, expanding your sample size for better results.
Learn More: dataprudence.com
#DataAugmentation
Learn More: dataprudence.com
#DataAugmentation

March 12, 2025 at 12:07 PM
We create synthetic data points that follow the patterns in your dataset, expanding your sample size for better results.
Learn More: dataprudence.com
#DataAugmentation
Learn More: dataprudence.com
#DataAugmentation
Data simulation can give your life science research a real edge, enabling more robust models and faster discoveries, even with limited real-world data. Learn more: dataprudence.com/ai-machine-l...
#datasimulation #dataaugmentation #artificialintelligence #machinelearning
#datasimulation #dataaugmentation #artificialintelligence #machinelearning

June 11, 2025 at 10:13 AM
Data simulation can give your life science research a real edge, enabling more robust models and faster discoveries, even with limited real-world data. Learn more: dataprudence.com/ai-machine-l...
#datasimulation #dataaugmentation #artificialintelligence #machinelearning
#datasimulation #dataaugmentation #artificialintelligence #machinelearning
Anchor Regression (AR) optimizes predictive accuracy while enhancing robustness to distribution shifts. #dataaugmentation
November 14, 2024 at 7:30 PM
Anchor Regression (AR) optimizes predictive accuracy while enhancing robustness to distribution shifts. #dataaugmentation

🚀 #DataAugmentation helps generate synthetic data when real data is scarce. In this #KNIME tutorial, Carlos Enrique Díaz & Dr. Lori Bradford use #copulas to model dependencies & create new data—no code needed with their "Synthetic Data (Copulas)" component!
📌 #READ → medium.com/low-code-for...
📌 #READ → medium.com/low-code-for...
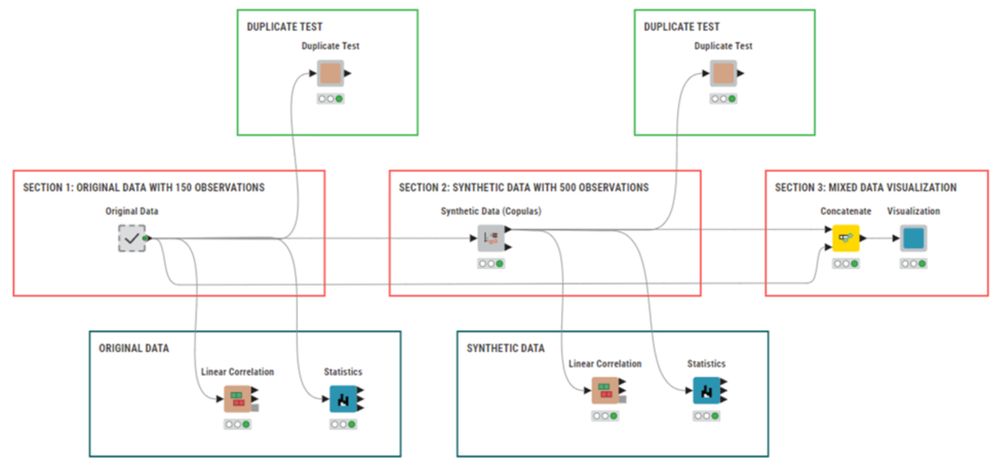
Not Enough Data? A No-Code Guide to Tabular Data Augmentation
A step-by-step KNIME tutorial to using copulas with the Synthetic Data (Copulas) component
medium.com
July 9, 2025 at 6:49 AM
🚀 #DataAugmentation helps generate synthetic data when real data is scarce. In this #KNIME tutorial, Carlos Enrique Díaz & Dr. Lori Bradford use #copulas to model dependencies & create new data—no code needed with their "Synthetic Data (Copulas)" component!
📌 #READ → medium.com/low-code-for...
📌 #READ → medium.com/low-code-for...

Unlock next gen AI capabilities with expert curated best practices for #syntheticdata generation. Discover how to build scalable, privacy-compliant datasets that accelerate smarter #machinelearning development.
bit.ly/4kSImL5
#dataaugmentation #Aimodeltraining #MLtrainingdata
bit.ly/4kSImL5
#dataaugmentation #Aimodeltraining #MLtrainingdata

Best Practices for Generating Synthetic Data: Unlock AI's Full Potential
Elevate your AI projects with expert synthetic data best practices. Learn to generate high-quality, privacy-compliant datasets, accelerate ML training, and ensure data utility.
bit.ly
July 22, 2025 at 7:33 AM
Unlock next gen AI capabilities with expert curated best practices for #syntheticdata generation. Discover how to build scalable, privacy-compliant datasets that accelerate smarter #machinelearning development.
bit.ly/4kSImL5
#dataaugmentation #Aimodeltraining #MLtrainingdata
bit.ly/4kSImL5
#dataaugmentation #Aimodeltraining #MLtrainingdata
This paper extends ADA’s evaluation to nonlinear regression on the California and Boston housing datasets, comparing its performance against C-Mixup. #dataaugmentation

ADA vs C-Mixup: Performance on California and Boston Housing Datasets
hackernoon.com
November 14, 2024 at 7:31 PM
This paper extends ADA’s evaluation to nonlinear regression on the California and Boston housing datasets, comparing its performance against C-Mixup. #dataaugmentation
This paper presents the ADA algorithm for generating minibatches in nonlinear regression models, using stochastic gradient descent. #dataaugmentation

How to Implement ADA for Data Augmentation in Nonlinear Regression Models
hackernoon.com
November 14, 2024 at 7:30 PM
This paper presents the ADA algorithm for generating minibatches in nonlinear regression models, using stochastic gradient descent. #dataaugmentation