




Vilém Zouhar #EMNLP
@zouharvi.bsky.social
PhD student @ ETH Zürich | all aspects of NLP but mostly evaluation and MT | go vegan | https://vilda.net
NLP evaluation is often detached from practical applications. Today I extrinsically evaluated one WMT25 translation system on the task of getting hair done without knowing Chinese.
Yes you got 67 BLEU points but is the resulting hair slaying? 💇
See the result on one datapoint (my head) at EMNLP.
Yes you got 67 BLEU points but is the resulting hair slaying? 💇
See the result on one datapoint (my head) at EMNLP.

November 3, 2025 at 5:49 AM
NLP evaluation is often detached from practical applications. Today I extrinsically evaluated one WMT25 translation system on the task of getting hair done without knowing Chinese.
Yes you got 67 BLEU points but is the resulting hair slaying? 💇
See the result on one datapoint (my head) at EMNLP.
Yes you got 67 BLEU points but is the resulting hair slaying? 💇
See the result on one datapoint (my head) at EMNLP.
The inspiration for the subset2evaluate poster comes from Henri Matisse's The Horse, the Rider and the Clown. 🐎🚴♀️🤡

October 28, 2025 at 5:13 PM
The inspiration for the subset2evaluate poster comes from Henri Matisse's The Horse, the Rider and the Clown. 🐎🚴♀️🤡
Let's talk about eval (automatic or human) and multilinguality at #EMNLP in Suzhou! 🇨🇳
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )



October 28, 2025 at 9:45 AM
Let's talk about eval (automatic or human) and multilinguality at #EMNLP in Suzhou! 🇨🇳
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025

October 20, 2025 at 10:37 AM
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
My two biggest take-aways are:
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎


September 16, 2025 at 8:49 AM
My two biggest take-aways are:
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
So what works? Selecting inputs that expose model differences:
1️⃣ high variance in metric scores
2️⃣ diversity in model outputs
3️⃣ high metric consistency with the rest of the dataset
We now need almost 30% fewer annotated examples to get the same model ranking.
1️⃣ high variance in metric scores
2️⃣ diversity in model outputs
3️⃣ high metric consistency with the rest of the dataset
We now need almost 30% fewer annotated examples to get the same model ranking.

July 15, 2025 at 1:03 PM
So what works? Selecting inputs that expose model differences:
1️⃣ high variance in metric scores
2️⃣ diversity in model outputs
3️⃣ high metric consistency with the rest of the dataset
We now need almost 30% fewer annotated examples to get the same model ranking.
1️⃣ high variance in metric scores
2️⃣ diversity in model outputs
3️⃣ high metric consistency with the rest of the dataset
We now need almost 30% fewer annotated examples to get the same model ranking.
We frame this as finding the smallest subset of data (Y ⊆ X) that gives the same model ranking as on the full dataset.
Simply picking the hardest examples (lowest average metric score) is a step up but can backfire by selecting the most expensive items to annotate.
Simply picking the hardest examples (lowest average metric score) is a step up but can backfire by selecting the most expensive items to annotate.

July 15, 2025 at 1:03 PM
We frame this as finding the smallest subset of data (Y ⊆ X) that gives the same model ranking as on the full dataset.
Simply picking the hardest examples (lowest average metric score) is a step up but can backfire by selecting the most expensive items to annotate.
Simply picking the hardest examples (lowest average metric score) is a step up but can backfire by selecting the most expensive items to annotate.
You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)

July 15, 2025 at 1:03 PM
You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
TIL that since python3.4 there's default `statistics` module with things like mean, mode, quantiles, variance, covariance, correlations, zscore, and more!. No more needless numpy imports!

July 9, 2025 at 12:49 AM
TIL that since python3.4 there's default `statistics` module with things like mean, mode, quantiles, variance, covariance, correlations, zscore, and more!. No more needless numpy imports!
For the longest time I've been using Google Translate as a gateway to explain machine translation concepts to people as it's a tool that everyone knows. Now I get to contribute over the summer. 🌞
If you're near Mountain View, let's talk evaluation. 📏
If you're near Mountain View, let's talk evaluation. 📏

July 3, 2025 at 4:15 AM
For the longest time I've been using Google Translate as a gateway to explain machine translation concepts to people as it's a tool that everyone knows. Now I get to contribute over the summer. 🌞
If you're near Mountain View, let's talk evaluation. 📏
If you're near Mountain View, let's talk evaluation. 📏

May 31, 2025 at 10:11 AM
arxiv submission process got an update!
(still requires a manual bbl)
(still requires a manual bbl)

May 31, 2025 at 9:56 AM
arxiv submission process got an update!
(still requires a manual bbl)
(still requires a manual bbl)
incredible monetization opportunity
(this is a joke)
(this is a joke)

May 14, 2025 at 8:52 AM
incredible monetization opportunity
(this is a joke)
(this is a joke)
Meticulously scanning through the whole text to find possible errors is really slow for humans and they miss many errors. Let's automate this process but keep the final judgments in human hands to avoid bias.

May 2, 2025 at 12:30 AM
Meticulously scanning through the whole text to find possible errors is really slow for humans and they miss many errors. Let's automate this process but keep the final judgments in human hands to avoid bias.
Ever looked down from a hot air balloon and despaired at how expensive it is to run thorough human evaluation of machine translation?
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.


May 2, 2025 at 12:30 AM
Ever looked down from a hot air balloon and despaired at how expensive it is to run thorough human evaluation of machine translation?
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
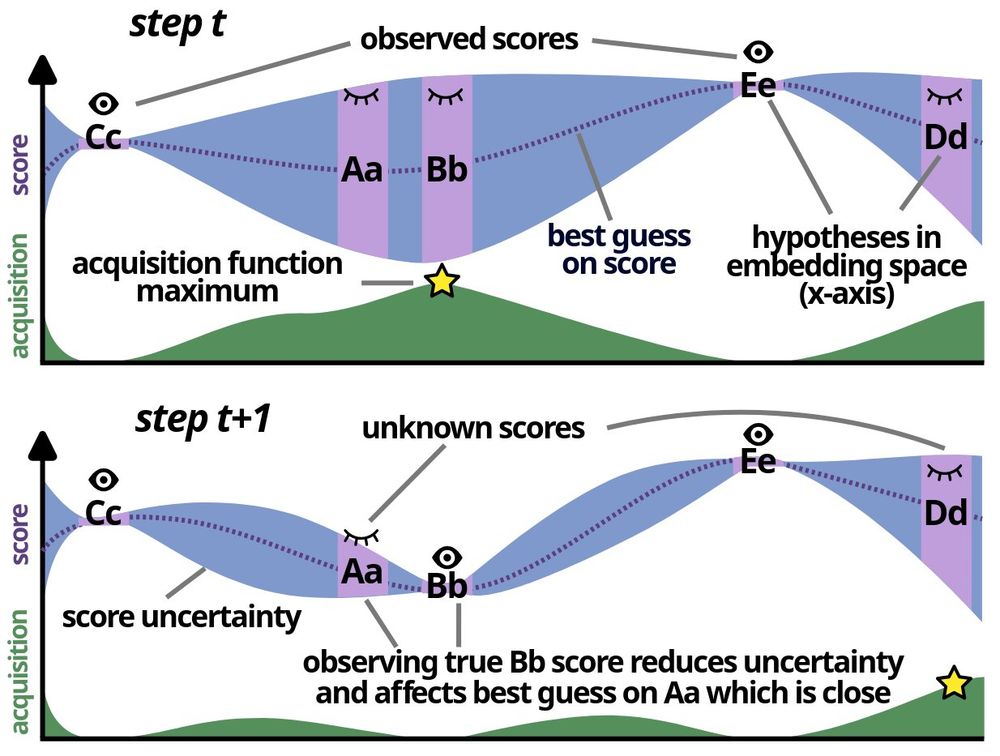
We pose reranking as a Bayesian optimization problem. By strategically selecting candidates to score based on a balance of exploration and exploitation, it is possible to find top-scoring candidate when scoring only a fraction of all possible ones.

May 2, 2025 at 12:26 AM
We pose reranking as a Bayesian optimization problem. By strategically selecting candidates to score based on a balance of exploration and exploitation, it is possible to find top-scoring candidate when scoring only a fraction of all possible ones.
Being in a hot air balloon in Albuquerque really makes one ponder *how to efficiently pick the best translation candidate without running expensive evaluation metrics on all of them.*
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
See you tomorrow at 9:00 in Hall 3 #NAACL2025.

May 2, 2025 at 12:26 AM
Being in a hot air balloon in Albuquerque really makes one ponder *how to efficiently pick the best translation candidate without running expensive evaluation metrics on all of them.*
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social

April 30, 2025 at 11:18 PM
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
Let's chat at #NAACL2025 about evaluation et al! ⚗️


April 22, 2025 at 7:35 AM
Let's chat at #NAACL2025 about evaluation et al! ⚗️
(Automatic) span annotations are the future of evaluation and diagnosis in NLP! 🖊️

April 15, 2025 at 11:30 AM
(Automatic) span annotations are the future of evaluation and diagnosis in NLP! 🖊️
Panopticon, but instead of prison cells, it's a stack of Overleaf tabs. You can’t watch them all at once, but at any moment, you *could* be watching any of them. And they know it.

March 25, 2025 at 9:48 AM
Panopticon, but instead of prison cells, it's a stack of Overleaf tabs. You can’t watch them all at once, but at any moment, you *could* be watching any of them. And they know it.

Bad times to be doing Direct Assessment in Pakistan these days.

March 4, 2025 at 2:19 PM
Bad times to be doing Direct Assessment in Pakistan these days.
This but replace Wittgenstein with yourself, colors with morphemes, the classroom with syntax, the ta...-

February 28, 2025 at 2:46 PM
This but replace Wittgenstein with yourself, colors with morphemes, the classroom with syntax, the ta...-
Some of the posters are truly beautiful




February 24, 2025 at 5:19 PM
Some of the posters are truly beautiful