




Visual Inference Lab
@visinf.bsky.social
Visual Inference Lab of @stefanroth.bsky.social at @tuda.bsky.social - Research in Computer Vision and Machine Learning.
See https://www.visinf.tu-darmstadt.de/visual_inference
See https://www.visinf.tu-darmstadt.de/visual_inference
[7/8] Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation
by @dustin-carrion.bsky.social, @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/emat
📄 arxiv.org/abs/2507.23642
💻 github.com/visinf/emat
Poster: Sun 4:40 PM - Exhibit Hall II #73
by @dustin-carrion.bsky.social, @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/emat
📄 arxiv.org/abs/2507.23642
💻 github.com/visinf/emat
Poster: Sun 4:40 PM - Exhibit Hall II #73

October 19, 2025 at 3:35 PM
[7/8] Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation
by @dustin-carrion.bsky.social, @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/emat
📄 arxiv.org/abs/2507.23642
💻 github.com/visinf/emat
Poster: Sun 4:40 PM - Exhibit Hall II #73
by @dustin-carrion.bsky.social, @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/emat
📄 arxiv.org/abs/2507.23642
💻 github.com/visinf/emat
Poster: Sun 4:40 PM - Exhibit Hall II #73
[6/8] Motion-Refined DINOSAUR for Unsupervised Multi-Object Discovery (Oral at ILR+G Workshop)
by Xinrui Gong*, @olvrhhn.bsky.social *, @christophreich.bsky.social , Krishnakant Singh, @simoneschaub.bsky.social , @dcremers.bsky.social @stefanroth.bsky.social
by Xinrui Gong*, @olvrhhn.bsky.social *, @christophreich.bsky.social , Krishnakant Singh, @simoneschaub.bsky.social , @dcremers.bsky.social @stefanroth.bsky.social
October 19, 2025 at 3:35 PM
[6/8] Motion-Refined DINOSAUR for Unsupervised Multi-Object Discovery (Oral at ILR+G Workshop)
by Xinrui Gong*, @olvrhhn.bsky.social *, @christophreich.bsky.social , Krishnakant Singh, @simoneschaub.bsky.social , @dcremers.bsky.social @stefanroth.bsky.social
by Xinrui Gong*, @olvrhhn.bsky.social *, @christophreich.bsky.social , Krishnakant Singh, @simoneschaub.bsky.social , @dcremers.bsky.social @stefanroth.bsky.social
[5/8] ART: Adaptive Relation Tuning for Generalized Relation Prediction
by Gopika Sudhakaran, Hikaru Shindo, Patrick Schramowski, @simoneschaub.bsky.social, @kerstingaiml.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2507.23543
Poster: Wed 2:45 PM, Exhibit Hall I #1501
by Gopika Sudhakaran, Hikaru Shindo, Patrick Schramowski, @simoneschaub.bsky.social, @kerstingaiml.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2507.23543
Poster: Wed 2:45 PM, Exhibit Hall I #1501

October 19, 2025 at 3:35 PM
[5/8] ART: Adaptive Relation Tuning for Generalized Relation Prediction
by Gopika Sudhakaran, Hikaru Shindo, Patrick Schramowski, @simoneschaub.bsky.social, @kerstingaiml.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2507.23543
Poster: Wed 2:45 PM, Exhibit Hall I #1501
by Gopika Sudhakaran, Hikaru Shindo, Patrick Schramowski, @simoneschaub.bsky.social, @kerstingaiml.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2507.23543
Poster: Wed 2:45 PM, Exhibit Hall I #1501
[4/8] Activation Subspaces for Out-of-Distribution Detection
by Baris Zongur, @robinhesse.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2508.21695
Poster: Tue 11:45 AM, Exhibit Hall I #326
by Baris Zongur, @robinhesse.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2508.21695
Poster: Tue 11:45 AM, Exhibit Hall I #326

October 19, 2025 at 3:35 PM
[4/8] Activation Subspaces for Out-of-Distribution Detection
by Baris Zongur, @robinhesse.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2508.21695
Poster: Tue 11:45 AM, Exhibit Hall I #326
by Baris Zongur, @robinhesse.bsky.social, @stefanroth.bsky.social
📄 arxiv.org/abs/2508.21695
Poster: Tue 11:45 AM, Exhibit Hall I #326
[3/8] Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion
by @jev-aleks.bsky.social *, @christophreich.bsky.social *, @fwimbauer.bsky.social , @olvrhhn.bsky.social , Christian Rupprecht, @stefanroth.bsky.social, @dcremers.bsky.social
🌍 visinf.github.io/scenedino/
by @jev-aleks.bsky.social *, @christophreich.bsky.social *, @fwimbauer.bsky.social , @olvrhhn.bsky.social , Christian Rupprecht, @stefanroth.bsky.social, @dcremers.bsky.social
🌍 visinf.github.io/scenedino/
October 19, 2025 at 3:35 PM
[3/8] Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion
by @jev-aleks.bsky.social *, @christophreich.bsky.social *, @fwimbauer.bsky.social , @olvrhhn.bsky.social , Christian Rupprecht, @stefanroth.bsky.social, @dcremers.bsky.social
🌍 visinf.github.io/scenedino/
by @jev-aleks.bsky.social *, @christophreich.bsky.social *, @fwimbauer.bsky.social , @olvrhhn.bsky.social , Christian Rupprecht, @stefanroth.bsky.social, @dcremers.bsky.social
🌍 visinf.github.io/scenedino/
[2/8] Removing Cost Volumes from Optical Flow Estimators (Oral)
by @skiefhaber.de , @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/recover
Talk: Tue 09:30 AM, Kalakaua Ballroom
Poster: Tue 11:45 AM, Exhibit Hall I #76
by @skiefhaber.de , @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/recover
Talk: Tue 09:30 AM, Kalakaua Ballroom
Poster: Tue 11:45 AM, Exhibit Hall I #76

October 19, 2025 at 3:35 PM
[2/8] Removing Cost Volumes from Optical Flow Estimators (Oral)
by @skiefhaber.de , @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/recover
Talk: Tue 09:30 AM, Kalakaua Ballroom
Poster: Tue 11:45 AM, Exhibit Hall I #76
by @skiefhaber.de , @stefanroth.bsky.social @simoneschaub.bsky.social
🌍 visinf.github.io/recover
Talk: Tue 09:30 AM, Kalakaua Ballroom
Poster: Tue 11:45 AM, Exhibit Hall I #76
TLDR: Given images captured by two vertically stacked omnidirectional cameras, DFI–OmniStereo integrates a pre-trained monocular depth foundation model into an iterative stereo matching approach. DFI–OmniStereo improves depth estimation accuracy, significantly outperforming the previous SotA.

October 17, 2025 at 9:27 PM
TLDR: Given images captured by two vertically stacked omnidirectional cameras, DFI–OmniStereo integrates a pre-trained monocular depth foundation model into an iterative stereo matching approach. DFI–OmniStereo improves depth estimation accuracy, significantly outperforming the previous SotA.
📢Excited to share our IROS 2025 paper “Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation Model”!
Work by Jannik Endres, @olvrhhn.bsky.social, Charles Cobière, @simoneschaub.bsky.social, @stefanroth.bsky.social and Alexandre Alahi.
Work by Jannik Endres, @olvrhhn.bsky.social, Charles Cobière, @simoneschaub.bsky.social, @stefanroth.bsky.social and Alexandre Alahi.
October 17, 2025 at 9:27 PM
📢Excited to share our IROS 2025 paper “Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation Model”!
Work by Jannik Endres, @olvrhhn.bsky.social, Charles Cobière, @simoneschaub.bsky.social, @stefanroth.bsky.social and Alexandre Alahi.
Work by Jannik Endres, @olvrhhn.bsky.social, Charles Cobière, @simoneschaub.bsky.social, @stefanroth.bsky.social and Alexandre Alahi.
Activation Subspaces for Out-of-Distribution Detection (ICCV 2025)
by Baris Zongur, @robinhesse.bsky.social, and @stefanroth.bsky.social
📄: arxiv.org/abs/2508.21695
Talk: Wednesday, 1:30 PM, Oral Session 2
Poster: Wednesday, 3:30 PM, Poster 12
by Baris Zongur, @robinhesse.bsky.social, and @stefanroth.bsky.social
📄: arxiv.org/abs/2508.21695
Talk: Wednesday, 1:30 PM, Oral Session 2
Poster: Wednesday, 3:30 PM, Poster 12

September 23, 2025 at 5:46 PM
Activation Subspaces for Out-of-Distribution Detection (ICCV 2025)
by Baris Zongur, @robinhesse.bsky.social, and @stefanroth.bsky.social
📄: arxiv.org/abs/2508.21695
Talk: Wednesday, 1:30 PM, Oral Session 2
Poster: Wednesday, 3:30 PM, Poster 12
by Baris Zongur, @robinhesse.bsky.social, and @stefanroth.bsky.social
📄: arxiv.org/abs/2508.21695
Talk: Wednesday, 1:30 PM, Oral Session 2
Poster: Wednesday, 3:30 PM, Poster 12
Removing Cost Volumes from Optical Flow Estimators (ICCV 2025 Oral)
by @skiefhaber.de, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/recover
Poster: Friday, 10:30 AM, Poster 14
by @skiefhaber.de, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/recover
Poster: Friday, 10:30 AM, Poster 14
September 23, 2025 at 5:46 PM
Removing Cost Volumes from Optical Flow Estimators (ICCV 2025 Oral)
by @skiefhaber.de, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/recover
Poster: Friday, 10:30 AM, Poster 14
by @skiefhaber.de, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/recover
Poster: Friday, 10:30 AM, Poster 14
Scene-Centric Unsupervised Panoptic Segmentation (CVPR 2025 Highlight)
by @olvrhhn.bsky.social *, @christophreich.bsky.social *, @neekans.bsky.social, @dcremers.bsky.social, Christian Rupprecht, @stefanroth.bsky.social 🌍: visinf.github.io/cups
Poster: Thursday, 1:30 PM, Poster 19
by @olvrhhn.bsky.social *, @christophreich.bsky.social *, @neekans.bsky.social, @dcremers.bsky.social, Christian Rupprecht, @stefanroth.bsky.social 🌍: visinf.github.io/cups
Poster: Thursday, 1:30 PM, Poster 19
September 23, 2025 at 5:46 PM
Scene-Centric Unsupervised Panoptic Segmentation (CVPR 2025 Highlight)
by @olvrhhn.bsky.social *, @christophreich.bsky.social *, @neekans.bsky.social, @dcremers.bsky.social, Christian Rupprecht, @stefanroth.bsky.social 🌍: visinf.github.io/cups
Poster: Thursday, 1:30 PM, Poster 19
by @olvrhhn.bsky.social *, @christophreich.bsky.social *, @neekans.bsky.social, @dcremers.bsky.social, Christian Rupprecht, @stefanroth.bsky.social 🌍: visinf.github.io/cups
Poster: Thursday, 1:30 PM, Poster 19
🌍: visinf.github.io/scenedino/
Talk: Friday, 10:00 AM, Oral Session 5
Poster: Friday, 10:30 AM, Poster 12
Talk: Friday, 10:00 AM, Oral Session 5
Poster: Friday, 10:30 AM, Poster 12
September 23, 2025 at 5:46 PM
🌍: visinf.github.io/scenedino/
Talk: Friday, 10:00 AM, Oral Session 5
Poster: Friday, 10:30 AM, Poster 12
Talk: Friday, 10:00 AM, Oral Session 5
Poster: Friday, 10:30 AM, Poster 12
Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation (GCPR 2025)
by @dustin-carrion.bsky.social, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/emat
Poster: Wednesday, 03:30 PM, Postern 8
by @dustin-carrion.bsky.social, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/emat
Poster: Wednesday, 03:30 PM, Postern 8

September 23, 2025 at 5:46 PM
Efficient Masked Attention Transformer for Few-Shot Classification and Segmentation (GCPR 2025)
by @dustin-carrion.bsky.social, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/emat
Poster: Wednesday, 03:30 PM, Postern 8
by @dustin-carrion.bsky.social, @stefanroth.bsky.social, and @simoneschaub.bsky.social
🌍: visinf.github.io/emat
Poster: Wednesday, 03:30 PM, Postern 8
Some impressions from our VISINF summer retreat at Lizumer Hütte in the Tirol Alps — including a hike up Geier Mountain and new research ideas at 2,857 m! 🇦🇹🏔️




August 29, 2025 at 12:48 PM
Some impressions from our VISINF summer retreat at Lizumer Hütte in the Tirol Alps — including a hike up Geier Mountain and new research ideas at 2,857 m! 🇦🇹🏔️




Disentangling Polysemantic Channels in Convolutional Neural Networks
by @robinhesse.bsky.social, Jonas Fischer, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Paper: arxiv.org/abs/2504.12939
Talk: Thursday 11:40 AM, Grand ballroom C1
Poster: Thursday, 12:30 PM, ExHall D, Poster 31-60
by @robinhesse.bsky.social, Jonas Fischer, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Paper: arxiv.org/abs/2504.12939
Talk: Thursday 11:40 AM, Grand ballroom C1
Poster: Thursday, 12:30 PM, ExHall D, Poster 31-60

June 11, 2025 at 8:56 PM
Disentangling Polysemantic Channels in Convolutional Neural Networks
by @robinhesse.bsky.social, Jonas Fischer, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Paper: arxiv.org/abs/2504.12939
Talk: Thursday 11:40 AM, Grand ballroom C1
Poster: Thursday, 12:30 PM, ExHall D, Poster 31-60
by @robinhesse.bsky.social, Jonas Fischer, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Paper: arxiv.org/abs/2504.12939
Talk: Thursday 11:40 AM, Grand ballroom C1
Poster: Thursday, 12:30 PM, ExHall D, Poster 31-60
GLASS: Guided Latent Slot Diffusion for Object-Centric Learning
by Krishnakant Singh, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Project Page: visinf.github.io/glass
Sunday 4:00 PM, ExHall D, Poster 239
by Krishnakant Singh, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Project Page: visinf.github.io/glass
Sunday 4:00 PM, ExHall D, Poster 239

June 11, 2025 at 8:56 PM
GLASS: Guided Latent Slot Diffusion for Object-Centric Learning
by Krishnakant Singh, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Project Page: visinf.github.io/glass
Sunday 4:00 PM, ExHall D, Poster 239
by Krishnakant Singh, @simoneschaub.bsky.social, and @stefanroth.bsky.social
Project Page: visinf.github.io/glass
Sunday 4:00 PM, ExHall D, Poster 239
Scene-Centric Unsupervised Panoptic Segmentation
by @olvrhhn.bsky.social , @christophreich.bsky.social , @neekans.bsky.social , @dcremers.bsky.social, Christian Rupprecht, and @stefanroth.bsky.social
Sunday, 8:30 AM, ExHall D, Poster 330
Project Page: visinf.github.io/cups
by @olvrhhn.bsky.social , @christophreich.bsky.social , @neekans.bsky.social , @dcremers.bsky.social, Christian Rupprecht, and @stefanroth.bsky.social
Sunday, 8:30 AM, ExHall D, Poster 330
Project Page: visinf.github.io/cups

June 11, 2025 at 8:56 PM
Scene-Centric Unsupervised Panoptic Segmentation
by @olvrhhn.bsky.social , @christophreich.bsky.social , @neekans.bsky.social , @dcremers.bsky.social, Christian Rupprecht, and @stefanroth.bsky.social
Sunday, 8:30 AM, ExHall D, Poster 330
Project Page: visinf.github.io/cups
by @olvrhhn.bsky.social , @christophreich.bsky.social , @neekans.bsky.social , @dcremers.bsky.social, Christian Rupprecht, and @stefanroth.bsky.social
Sunday, 8:30 AM, ExHall D, Poster 330
Project Page: visinf.github.io/cups
✅ Outperform the SotA by a significant margin.
✅ Generalize to different datasets, including an OOD setting.
✅ Stable performance across domains, different from supervised learning.
✅ Generalize to different datasets, including an OOD setting.
✅ Stable performance across domains, different from supervised learning.

April 4, 2025 at 1:38 PM
✅ Outperform the SotA by a significant margin.
✅ Generalize to different datasets, including an OOD setting.
✅ Stable performance across domains, different from supervised learning.
✅ Generalize to different datasets, including an OOD setting.
✅ Stable performance across domains, different from supervised learning.
We train a panoptic network on our high-precision pseudo-labels using self-enhanced copy-paste augmentation. Self-training refines predictions via a momentum network, aligning and filtering augmented outputs into self-labels. 🚀

April 4, 2025 at 1:38 PM
We train a panoptic network on our high-precision pseudo-labels using self-enhanced copy-paste augmentation. Self-training refines predictions via a momentum network, aligning and filtering augmented outputs into self-labels. 🚀
CUPS consists of pseudo-label generation, network bootstrapping, and self-training. We take inspiration from Gestalt principles (similarity, invariance, & common fate) and generate high-res. panoptic pseudo labels by complementing visual representations with depth & motion cues.

April 4, 2025 at 1:38 PM
CUPS consists of pseudo-label generation, network bootstrapping, and self-training. We take inspiration from Gestalt principles (similarity, invariance, & common fate) and generate high-res. panoptic pseudo labels by complementing visual representations with depth & motion cues.
📢 #CVPR2025 Highlight: Scene-Centric Unsupervised Panoptic Segmentation 🔥
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
April 4, 2025 at 1:38 PM
📢 #CVPR2025 Highlight: Scene-Centric Unsupervised Panoptic Segmentation 🔥
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
We present CUPS, the first unsupervised panoptic segmentation method trained directly on scene-centric imagery.
Using self-supervised features, depth & motion, we achieve SotA results!
🌎 visinf.github.io/cups
🏔️⛷️ Looking back on a fantastic week full of talks, research discussions, and skiing in the Austrian mountains!

January 31, 2025 at 7:38 PM
🏔️⛷️ Looking back on a fantastic week full of talks, research discussions, and skiing in the Austrian mountains!
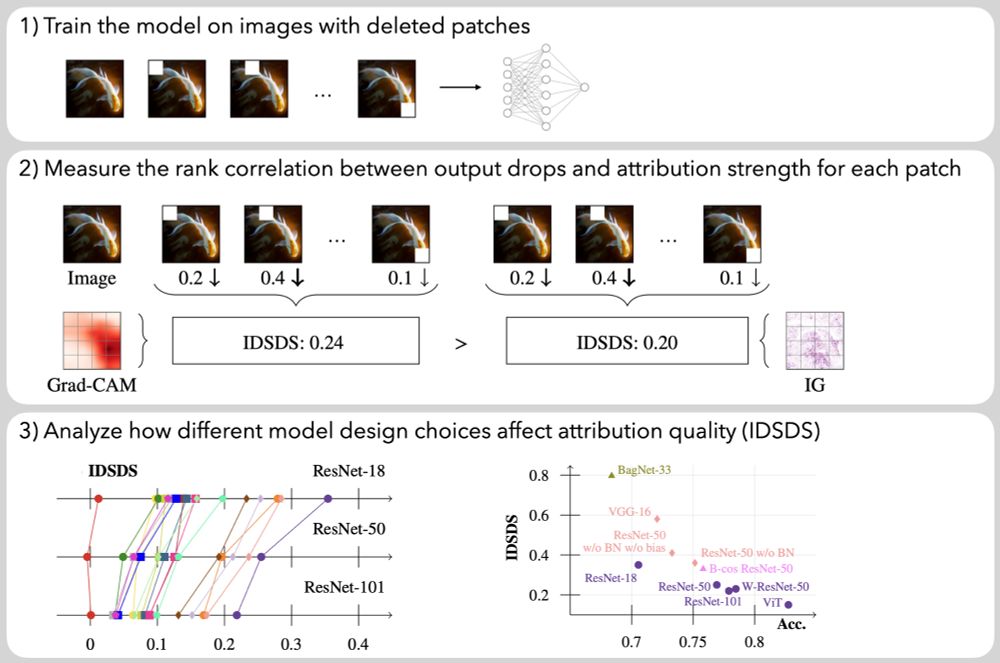
Want to learn about how model design choices affect the attribution quality of vision models? Visit our #NeurIPS2024 poster on Friday afternoon (East Exhibition Hall A-C #2910)!
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
December 13, 2024 at 10:10 AM
Want to learn about how model design choices affect the attribution quality of vision models? Visit our #NeurIPS2024 poster on Friday afternoon (East Exhibition Hall A-C #2910)!
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
Try PriMaPs with your own photos using our 🤗 demo at huggingface.co/spaces/olvrh...
@hf.co @gradio-hf.bsky.social
@hf.co @gradio-hf.bsky.social
November 28, 2024 at 5:41 PM
Try PriMaPs with your own photos using our 🤗 demo at huggingface.co/spaces/olvrh...
@hf.co @gradio-hf.bsky.social
@hf.co @gradio-hf.bsky.social