



Vishaal Udandarao
@vishaalurao.bsky.social
@ELLISforEurope PhD Student @bethgelab @caml_lab @Cambridge_Uni @uni_tue; Currently SR @GoogleAI; Previously MPhil @Cambridge_Uni, RA @RutgersU, UG @iiitdelhi
vishaal27.github.io
vishaal27.github.io
Reposted by Vishaal Udandarao

Our workshop in numbers:
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels

December 19, 2024 at 4:59 AM
Our workshop in numbers:
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
This was work done during my internship with amazing folks @google @deep-mind.bsky.social: @nikparth1.bsky.social (joint-first) Ferjad Talfan @samuelalbanie.bsky.social Federico Yongqin Alessio & @olivierhenaff.bsky.social
Super excited about this direction of strong pretraining for smol models!
Super excited about this direction of strong pretraining for smol models!
December 2, 2024 at 6:06 PM
This was work done during my internship with amazing folks @google @deep-mind.bsky.social: @nikparth1.bsky.social (joint-first) Ferjad Talfan @samuelalbanie.bsky.social Federico Yongqin Alessio & @olivierhenaff.bsky.social
Super excited about this direction of strong pretraining for smol models!
Super excited about this direction of strong pretraining for smol models!
Bonus: Along the way, we found current state of CLIP zero-shot benchmarking in disarray—some test datasets have a seed std of ~12%!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!

December 2, 2024 at 6:03 PM
Bonus: Along the way, we found current state of CLIP zero-shot benchmarking in disarray—some test datasets have a seed std of ~12%!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
We construct a stable & reliable set of evaluations (StableEval) inspired by the inverse-variance-weighting method, to prune out unreliable evals!
Finally, we scale all our insights to pretrain SoTA FLOP-efficient models across three different FLOP-scales: ACED-F{0,1,2}
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!

December 2, 2024 at 6:02 PM
Finally, we scale all our insights to pretrain SoTA FLOP-efficient models across three different FLOP-scales: ACED-F{0,1,2}
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
Outperforming strong baselines including Apple's MobileCLIP, TinyCLIP and @datologyai.com CLIP models!
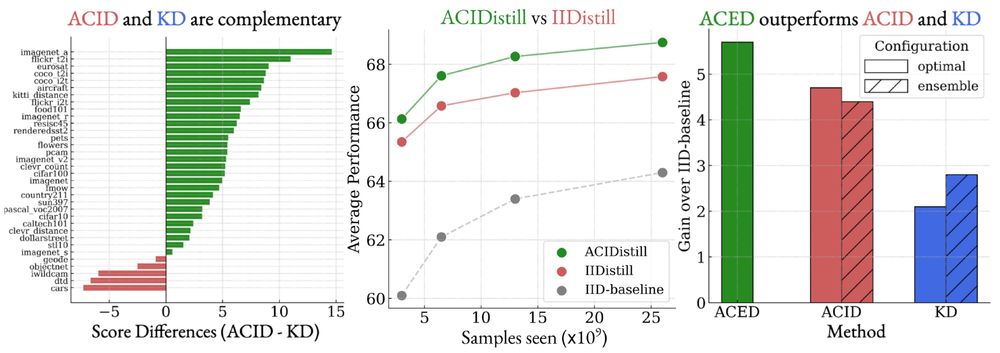
There's more! ACID and KD are complementary — they can be profitably combined, at scale! Our simple pretraining recipe ACED-ACIDistill showcases continued benefits as we scale to 26B samples seen!
December 2, 2024 at 6:02 PM
There's more! ACID and KD are complementary — they can be profitably combined, at scale! Our simple pretraining recipe ACED-ACIDistill showcases continued benefits as we scale to 26B samples seen!
We also show that ACID strongly outperforms KD across different reference/teacher training datasets, KD objectives, and student sizes.

December 2, 2024 at 6:01 PM
We also show that ACID strongly outperforms KD across different reference/teacher training datasets, KD objectives, and student sizes.
Our ACID method shows very strong scaling properties as the size of the reference model increases, until we hit a saturation point — the optimal reference-student capacity ratio.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.

December 2, 2024 at 6:01 PM
Our ACID method shows very strong scaling properties as the size of the reference model increases, until we hit a saturation point — the optimal reference-student capacity ratio.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
Further, ACID significantly outperforms KD as we scale up the reference/teacher sizes.
As our ACID method performs implicit distillation, we can further combine our data curation strategy with an explicit distillation objective, and conduct a series of experiments to determine the optimal combination strategy.

December 2, 2024 at 6:00 PM
As our ACID method performs implicit distillation, we can further combine our data curation strategy with an explicit distillation objective, and conduct a series of experiments to determine the optimal combination strategy.
Our online curation method (ACID) uses large pretrained reference models (adopting from prior work: JEST) & we show a theoretical equivalence b/w KD and ACID (appx C in paper).

December 2, 2024 at 6:00 PM
Our online curation method (ACID) uses large pretrained reference models (adopting from prior work: JEST) & we show a theoretical equivalence b/w KD and ACID (appx C in paper).
TLDR: We introduce an online data curation method that when coupled with simple softmax knowledge distillation produces a very effective pretraining recipe yielding SoTA inference-efficient two-tower contrastive VLMs!

December 2, 2024 at 5:59 PM
TLDR: We introduce an online data curation method that when coupled with simple softmax knowledge distillation produces a very effective pretraining recipe yielding SoTA inference-efficient two-tower contrastive VLMs!
Great paper! Why do you think it doesn’t make sense for pretraining to be made aware of the model being used in a few-shot setting downstream? Do you see any potential downsides of this kind of approach?
November 29, 2024 at 9:39 AM
Great paper! Why do you think it doesn’t make sense for pretraining to be made aware of the model being used in a few-shot setting downstream? Do you see any potential downsides of this kind of approach?
@bayesiankitten.bsky.social @dziadzio.bsky.social and I also work on continual pretraining :)
November 28, 2024 at 9:13 PM
@bayesiankitten.bsky.social @dziadzio.bsky.social and I also work on continual pretraining :)
Congrats, super exciting!!
November 22, 2024 at 12:50 PM
Congrats, super exciting!!