



Vishaal Udandarao
@vishaalurao.bsky.social
@ELLISforEurope PhD Student @bethgelab @caml_lab @Cambridge_Uni @uni_tue; Currently SR @GoogleAI; Previously MPhil @Cambridge_Uni, RA @RutgersU, UG @iiitdelhi
vishaal27.github.io
vishaal27.github.io
Pinned

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
Reposted by Vishaal Udandarao

CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
February 17, 2025 at 6:22 PM
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵
Reposted by Vishaal Udandarao

Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
January 7, 2025 at 10:25 PM
Ever wondered why presenting more facts can sometimes *worsen* disagreements, even among rational people? 🤔
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
It turns out, Bayesian reasoning has some surprising answers - no cognitive biases needed! Let's explore this fascinating paradox quickly ☺️
Reposted by Vishaal Udandarao

🎉 Had fun at #NeurIPS2024 Workshop on #AdaptiveFoundationModels!
🚀 Speakers: @rsalakhu.bsky.social @sedielem.bsky.social Kate Saenko, Matthias Bethge / @vishaalurao.bsky.social Minjoon Seo, Bing Liu, Tianqi Chen
🌐Posters: adaptive-foundation-models.org/papers
🎬 neurips.cc/virtual/2024...
🧵Recap!
🚀 Speakers: @rsalakhu.bsky.social @sedielem.bsky.social Kate Saenko, Matthias Bethge / @vishaalurao.bsky.social Minjoon Seo, Bing Liu, Tianqi Chen
🌐Posters: adaptive-foundation-models.org/papers
🎬 neurips.cc/virtual/2024...
🧵Recap!

December 19, 2024 at 4:59 AM
🎉 Had fun at #NeurIPS2024 Workshop on #AdaptiveFoundationModels!
🚀 Speakers: @rsalakhu.bsky.social @sedielem.bsky.social Kate Saenko, Matthias Bethge / @vishaalurao.bsky.social Minjoon Seo, Bing Liu, Tianqi Chen
🌐Posters: adaptive-foundation-models.org/papers
🎬 neurips.cc/virtual/2024...
🧵Recap!
🚀 Speakers: @rsalakhu.bsky.social @sedielem.bsky.social Kate Saenko, Matthias Bethge / @vishaalurao.bsky.social Minjoon Seo, Bing Liu, Tianqi Chen
🌐Posters: adaptive-foundation-models.org/papers
🎬 neurips.cc/virtual/2024...
🧵Recap!
Reposted by Vishaal Udandarao
Our workshop in numbers:
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels

December 19, 2024 at 4:59 AM
Our workshop in numbers:
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
🖇️ 128 Papers
💬 8 Orals
🖋️ 564 Authors
✅ 40 Reviewers
🔊 7 Invited Speakers
👕 100 T-Shirts
🔥 Organizers: Paul Vicol, Mengye Ren, Renjie Liao, Naila Murray, Wei-Chiu Ma, Beidi Chen
#NeurIPS2024 #AdaptiveFoundationModels
Reposted by Vishaal Udandarao

🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745

December 10, 2024 at 5:44 PM
🚨Looking to test your foundation model on an arbitrary and open-ended set of capabilities, not explicitly captured by static benchmarks? 🚨
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Check out ✨ONEBench✨, where we show how sample-level evaluation is the solution.
🔎 arxiv.org/abs/2412.06745
Reposted by Vishaal Udandarao

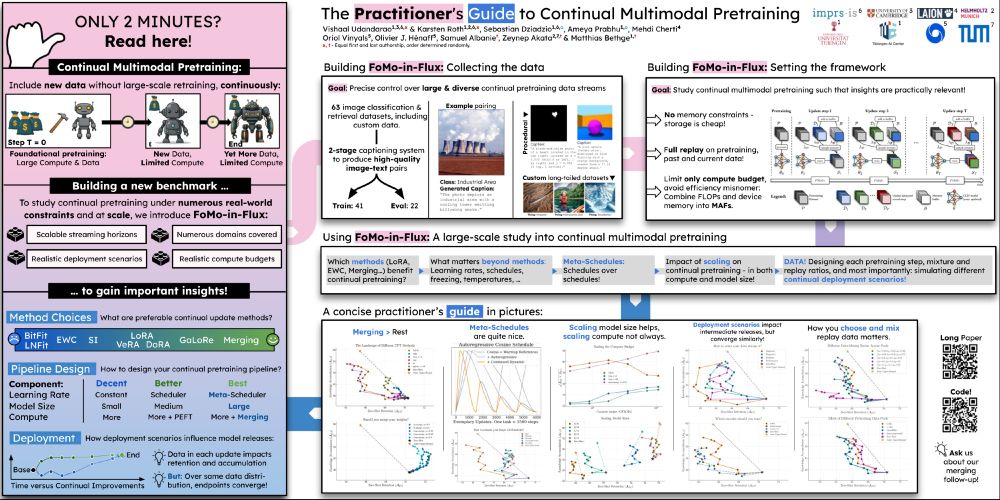
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
December 10, 2024 at 4:42 PM
😵💫 Continually pretraining large multimodal models to keep them up-to-date all-the-time is tough, covering everything from adapters, merging, meta-scheduling to data design and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
So I'm really happy to present our large-scale study at #NeurIPS2024!
Come drop by to talk about all that and more!
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
December 2, 2024 at 5:59 PM
🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
Reposted by Vishaal Udandarao

ICYMI, check out our latest results @datologyai.com on curating data for LLMs.
Intervening only on training data, our pipeline can train models faster (7.7x less compute), better (+8.5% performance), and smaller (models half the size outperform by >5%)!
www.datologyai.com/post/technic...
Intervening only on training data, our pipeline can train models faster (7.7x less compute), better (+8.5% performance), and smaller (models half the size outperform by >5%)!
www.datologyai.com/post/technic...

Technical Deep-Dive: Curating Our Way to a State-of-the-Art Text Dataset
Our data curation pipeline to obtain substantial improvements in LLM quality, training speed, and inference efficiency.
www.datologyai.com
November 29, 2024 at 4:36 PM
ICYMI, check out our latest results @datologyai.com on curating data for LLMs.
Intervening only on training data, our pipeline can train models faster (7.7x less compute), better (+8.5% performance), and smaller (models half the size outperform by >5%)!
www.datologyai.com/post/technic...
Intervening only on training data, our pipeline can train models faster (7.7x less compute), better (+8.5% performance), and smaller (models half the size outperform by >5%)!
www.datologyai.com/post/technic...
Reposted by Vishaal Udandarao
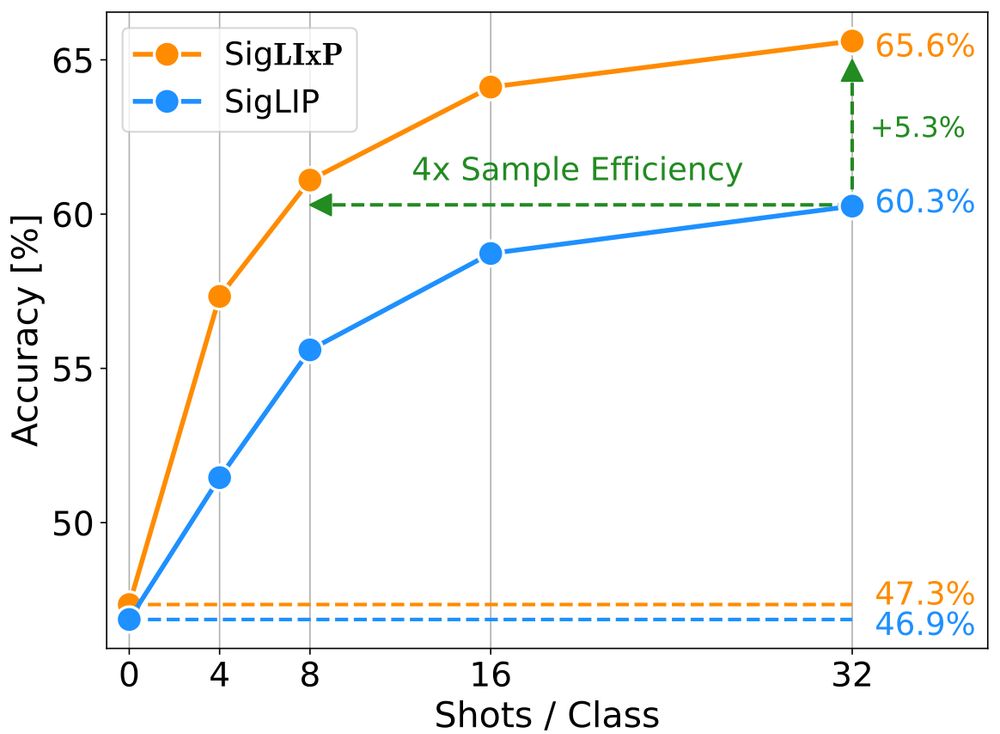
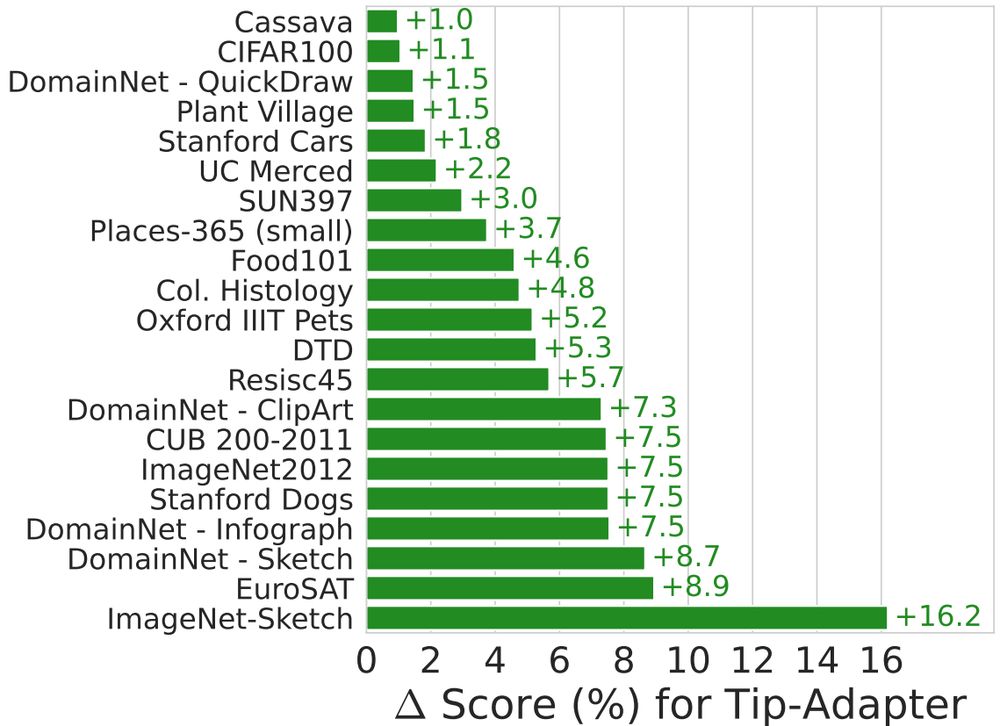
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Vishaal Udandarao

1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
November 19, 2024 at 4:30 PM
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
Reposted by Vishaal Udandarao

Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA

Tübingen AI
Join the conversation
go.bsky.app
November 19, 2024 at 1:14 PM
Here's a fledgling starter pack for the AI community in Tübingen. Let me know if you'd like to be added!
go.bsky.app/NFbVzrA
go.bsky.app/NFbVzrA