




Valentina Pyatkin
@valentinapy.bsky.social
Postdoc in AI at the Allen Institute for AI & the University of Washington.
🌐 https://valentinapy.github.io
🌐 https://valentinapy.github.io
Reposted by Valentina Pyatkin


Reposted by Valentina Pyatkin

There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
Are LLMs biased when they write about political issues?
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇
We just released IssueBench – the largest, most realistic benchmark of its kind – to answer this question more robustly than ever before.
Long 🧵with spicy results 👇

October 29, 2025 at 4:12 PM
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
I will be giving a talk at @eth-ai-center.bsky.social next week, on RLVR for verifiable instruction following, generalization, and reasoning! 📢
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social

October 27, 2025 at 2:22 PM
I will be giving a talk at @eth-ai-center.bsky.social next week, on RLVR for verifiable instruction following, generalization, and reasoning! 📢
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
Reposted by Valentina Pyatkin

"Although I hate leafy vegetables, I prefer daxes to blickets." Can you tell if daxes are leafy vegetables? LM's can't seem to! 📷
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social

October 16, 2025 at 3:27 PM
"Although I hate leafy vegetables, I prefer daxes to blickets." Can you tell if daxes are leafy vegetables? LM's can't seem to! 📷
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
💡We kicked off the SoLaR workshop at #COLM2025 with a great opinion talk by @michelleding.bsky.social & Jo Gasior Kavishe (joint work with @victorojewale.bsky.social and
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."

October 10, 2025 at 2:31 PM
💡We kicked off the SoLaR workshop at #COLM2025 with a great opinion talk by @michelleding.bsky.social & Jo Gasior Kavishe (joint work with @victorojewale.bsky.social and
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
Reposted by Valentina Pyatkin

Hi #COLM2025! 🇨🇦 I will be presenting a talk on the importance of community-driven LLM evaluations based on an opinion abstract I wrote with Jo Kavishe, @victorojewale.bsky.social and @geomblog.bsky.social tomorrow at 9:30am in 524b for solar-colm.github.io
Hope to see you there!
Hope to see you there!

Third Workshop on Socially Responsible Language Modelling Research (SoLaR) 2025
COLM 2025 in-person Workshop, October 10th at the Palais des Congrès in Montreal, Canada
solar-colm.github.io
October 9, 2025 at 7:32 PM
Hi #COLM2025! 🇨🇦 I will be presenting a talk on the importance of community-driven LLM evaluations based on an opinion abstract I wrote with Jo Kavishe, @victorojewale.bsky.social and @geomblog.bsky.social tomorrow at 9:30am in 524b for solar-colm.github.io
Hope to see you there!
Hope to see you there!
Now accepted to #neurips25 datasets & benchmarks!
See you in San Diego! 🥳
See you in San Diego! 🥳
💡Beyond math/code, instruction following with verifiable constraints is suitable to be learned with RLVR.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.

September 20, 2025 at 6:56 AM
Now accepted to #neurips25 datasets & benchmarks!
See you in San Diego! 🥳
See you in San Diego! 🥳
Reposted by Valentina Pyatkin

🚀 Can open science beat closed AI? Tülu 3 makes a powerful case. In our new #WiAIRpodcast, we speak with Valentina Pyatkin (@valentinapy.bsky.social) of @ai2.bsky.social and the University of Washington about a fully open post-training recipe—models, data, code, evals, and infra. #WomenInAI 1/8🧵


September 19, 2025 at 4:13 PM
🚀 Can open science beat closed AI? Tülu 3 makes a powerful case. In our new #WiAIRpodcast, we speak with Valentina Pyatkin (@valentinapy.bsky.social) of @ai2.bsky.social and the University of Washington about a fully open post-training recipe—models, data, code, evals, and infra. #WomenInAI 1/8🧵
Reposted by Valentina Pyatkin
"𝐋𝐋𝐌 𝐏𝐨𝐬𝐭-𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: 𝐎𝐩𝐞𝐧 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 𝐓𝐡𝐚𝐭 𝐏𝐨𝐰𝐞𝐫𝐬 𝐏𝐫𝐨𝐠𝐫𝐞𝐬𝐬 " 🎙️
On Sept 17, the #WiAIRpodcast speaks with @valentinapy.bsky.social (@ai2.bsky.social & University of Washington) about open science, post-training, mentorship, and visibility
#WiAIR #NLProc
On Sept 17, the #WiAIRpodcast speaks with @valentinapy.bsky.social (@ai2.bsky.social & University of Washington) about open science, post-training, mentorship, and visibility
#WiAIR #NLProc

September 12, 2025 at 3:00 PM
"𝐋𝐋𝐌 𝐏𝐨𝐬𝐭-𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: 𝐎𝐩𝐞𝐧 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 𝐓𝐡𝐚𝐭 𝐏𝐨𝐰𝐞𝐫𝐬 𝐏𝐫𝐨𝐠𝐫𝐞𝐬𝐬 " 🎙️
On Sept 17, the #WiAIRpodcast speaks with @valentinapy.bsky.social (@ai2.bsky.social & University of Washington) about open science, post-training, mentorship, and visibility
#WiAIR #NLProc
On Sept 17, the #WiAIRpodcast speaks with @valentinapy.bsky.social (@ai2.bsky.social & University of Washington) about open science, post-training, mentorship, and visibility
#WiAIR #NLProc
Reposted by Valentina Pyatkin

With fresh support of $75M from NSF and $77M from NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡

August 14, 2025 at 12:16 PM
With fresh support of $75M from NSF and $77M from NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡
On my way to Oxford: Looking forward to speaking at OxML 2025

August 10, 2025 at 8:09 AM
On my way to Oxford: Looking forward to speaking at OxML 2025
🔈For the SoLaR workshop
@COLM_conf
we are soliciting opinion abstracts to encourage new perspectives and opinions on responsible language modeling, 1-2 of which will be selected to be presented at the workshop.
Please use the google form below to submit your opinion abstract ⬇️
@COLM_conf
we are soliciting opinion abstracts to encourage new perspectives and opinions on responsible language modeling, 1-2 of which will be selected to be presented at the workshop.
Please use the google form below to submit your opinion abstract ⬇️
August 8, 2025 at 12:40 PM
🔈For the SoLaR workshop
@COLM_conf
we are soliciting opinion abstracts to encourage new perspectives and opinions on responsible language modeling, 1-2 of which will be selected to be presented at the workshop.
Please use the google form below to submit your opinion abstract ⬇️
@COLM_conf
we are soliciting opinion abstracts to encourage new perspectives and opinions on responsible language modeling, 1-2 of which will be selected to be presented at the workshop.
Please use the google form below to submit your opinion abstract ⬇️
Reposted by Valentina Pyatkin

I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
August 2, 2025 at 3:04 PM
I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
Reposted by Valentina Pyatkin

I'll be at #ACL2025🇦🇹!!
Would love to chat about all things pragmatics 🧠, redefining "helpfulness"🤔 and enabling better cross-cultural capabilities 🗺️ 🫶
Presenting our work on culturally offensive nonverbal gestures 👇
🕛Wed @ Poster Session 4
📍Hall 4/5, 11:00-12:30
Would love to chat about all things pragmatics 🧠, redefining "helpfulness"🤔 and enabling better cross-cultural capabilities 🗺️ 🫶
Presenting our work on culturally offensive nonverbal gestures 👇
🕛Wed @ Poster Session 4
📍Hall 4/5, 11:00-12:30
Did you know? Gestures used to express universal concepts—like wishing for luck—vary DRAMATICALLY across cultures?
🤞means luck in US but deeply offensive in Vietnam 🚨
📣 We introduce MC-SIGNS, a test bed to evaluate how LLMs/VLMs/T2I handle such nonverbal behavior!
📜: arxiv.org/abs/2502.17710
🤞means luck in US but deeply offensive in Vietnam 🚨
📣 We introduce MC-SIGNS, a test bed to evaluate how LLMs/VLMs/T2I handle such nonverbal behavior!
📜: arxiv.org/abs/2502.17710

July 26, 2025 at 2:46 AM
I'll be at #ACL2025🇦🇹!!
Would love to chat about all things pragmatics 🧠, redefining "helpfulness"🤔 and enabling better cross-cultural capabilities 🗺️ 🫶
Presenting our work on culturally offensive nonverbal gestures 👇
🕛Wed @ Poster Session 4
📍Hall 4/5, 11:00-12:30
Would love to chat about all things pragmatics 🧠, redefining "helpfulness"🤔 and enabling better cross-cultural capabilities 🗺️ 🫶
Presenting our work on culturally offensive nonverbal gestures 👇
🕛Wed @ Poster Session 4
📍Hall 4/5, 11:00-12:30
🔥tokenization panel!

July 18, 2025 at 10:45 PM
🔥tokenization panel!
why is vancouver sushi so good? 🤤 (vancouver food in general actually)
July 18, 2025 at 8:27 PM
why is vancouver sushi so good? 🤤 (vancouver food in general actually)
Reposted by Valentina Pyatkin
This week is #ICML in Vancouver, and a number of our researchers are participating. Here's the full list of Ai2's conference engagements—we look forward to connecting with fellow attendees. 👋

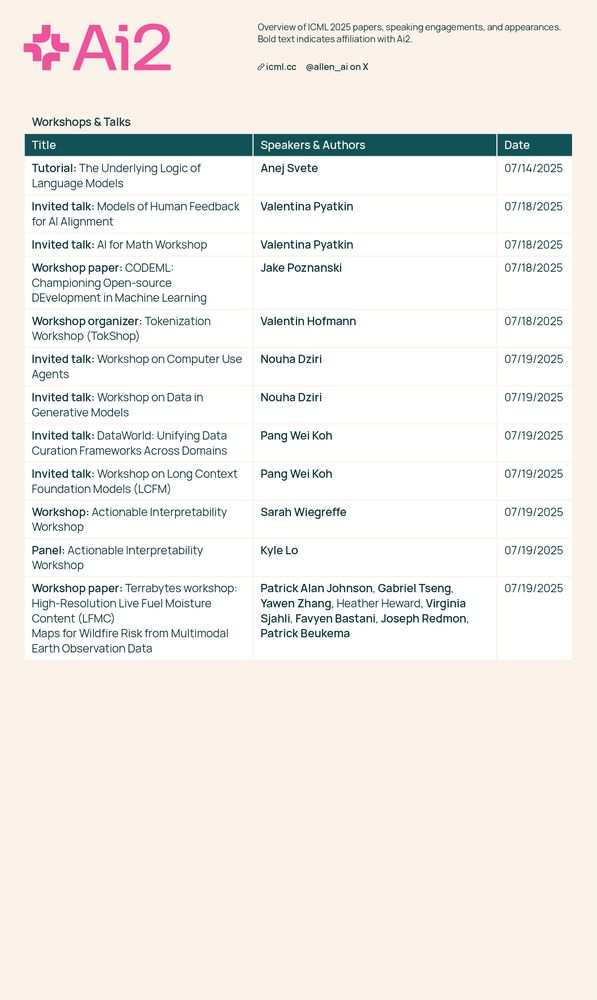
July 14, 2025 at 7:30 PM
This week is #ICML in Vancouver, and a number of our researchers are participating. Here's the full list of Ai2's conference engagements—we look forward to connecting with fellow attendees. 👋
I'll be at ICML in Vancouver next week! #ICML2025
You can find me at the following:
- giving an invited talk at the "Models of Human Feedback for AI Alignment" workshop
- giving an invited talk at the "AI for Math" workshop
I'll also present these two papers ⤵️
You can find me at the following:
- giving an invited talk at the "Models of Human Feedback for AI Alignment" workshop
- giving an invited talk at the "AI for Math" workshop
I'll also present these two papers ⤵️
July 11, 2025 at 2:09 PM
I'll be at ICML in Vancouver next week! #ICML2025
You can find me at the following:
- giving an invited talk at the "Models of Human Feedback for AI Alignment" workshop
- giving an invited talk at the "AI for Math" workshop
I'll also present these two papers ⤵️
You can find me at the following:
- giving an invited talk at the "Models of Human Feedback for AI Alignment" workshop
- giving an invited talk at the "AI for Math" workshop
I'll also present these two papers ⤵️
In Geneva🇨🇭to attend the International Open-Source LLM Builders Summit and present OLMo and Tülu!
July 6, 2025 at 5:23 PM
In Geneva🇨🇭to attend the International Open-Source LLM Builders Summit and present OLMo and Tülu!
💡Beyond math/code, instruction following with verifiable constraints is suitable to be learned with RLVR.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
July 3, 2025 at 9:06 PM
💡Beyond math/code, instruction following with verifiable constraints is suitable to be learned with RLVR.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
But the set of constraints and verifier functions is limited and most models overfit on IFEval.
We introduce IFBench to measure model generalization to unseen constraints.
Reposted by Valentina Pyatkin

plus, some fun RL experiments
July 3, 2025 at 6:14 PM
plus, some fun RL experiments
Reposted by Valentina Pyatkin
This new benchmark created by @valentinapy.bsky.social should be the new default replacing IFEval. Some of the best frontier models get <50% and it comes with separate training prompts so people don’t effectively train on test.
Wild gap from o3 > Gemini 2.5 pro of like 30 points.
Wild gap from o3 > Gemini 2.5 pro of like 30 points.
Introducing IFBench, a benchmark to measure how well AI models follow new, challenging, and diverse verifiable instructions. Top models like Gemini 2.5 Pro or Claude 4 Sonnet are only able to score up to 50%, presenting an open frontier for post-training. 🧵

July 3, 2025 at 6:14 PM
This new benchmark created by @valentinapy.bsky.social should be the new default replacing IFEval. Some of the best frontier models get <50% and it comes with separate training prompts so people don’t effectively train on test.
Wild gap from o3 > Gemini 2.5 pro of like 30 points.
Wild gap from o3 > Gemini 2.5 pro of like 30 points.
Reposted by Valentina Pyatkin
Introducing IFBench, a benchmark to measure how well AI models follow new, challenging, and diverse verifiable instructions. Top models like Gemini 2.5 Pro or Claude 4 Sonnet are only able to score up to 50%, presenting an open frontier for post-training. 🧵
July 3, 2025 at 6:01 PM
Introducing IFBench, a benchmark to measure how well AI models follow new, challenging, and diverse verifiable instructions. Top models like Gemini 2.5 Pro or Claude 4 Sonnet are only able to score up to 50%, presenting an open frontier for post-training. 🧵
Reposted by Valentina Pyatkin
Check out our take on Chain-of-Thought.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.

Excited to share our paper: "Chain-of-Thought Is Not Explainability"! We unpack a critical misconception in AI: models explaining their steps (CoT) aren't necessarily revealing their true reasoning. Spoiler: the transparency can be an illusion. (1/9) 🧵

July 1, 2025 at 5:45 PM
Check out our take on Chain-of-Thought.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
I really like this paper as a survey on the current literature on what CoT is, but more importantly on what it's not.
It also serves as a cautionary tale to the (apparently quite common) misuse of CoT as an interpretable method.
Reposted by Valentina Pyatkin

🚨Submission deadline extended to June 27th AoE!🚨
Our reviewer interest form is also open!
See below for more details👇
Our reviewer interest form is also open!
See below for more details👇
Interested in shaping the progress of responsible AI and meeting leading researchers in the field? SoLaR@COLM 2025 is looking for paper submissions and reviewers!
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research
🤖 ML track: algorithms, math, computation
📚 Socio-technical track: policy, ethics, human participant research

June 24, 2025 at 6:02 PM
🚨Submission deadline extended to June 27th AoE!🚨
Our reviewer interest form is also open!
See below for more details👇
Our reviewer interest form is also open!
See below for more details👇