



Scott Condron
@scottcondron.bsky.social
Working at wandb on Weave, helping teams ship AI applications
Maybe they could tell you what they’ve learned like “it seems you’re interested in staying up to date with recommender systems, want to add that to your feed?”
March 9, 2025 at 10:31 AM
Maybe they could tell you what they’ve learned like “it seems you’re interested in staying up to date with recommender systems, want to add that to your feed?”
Thanks Scott! Very exciting
March 9, 2025 at 9:34 AM
Thanks Scott! Very exciting
Reposted by Scott Condron

I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
web.mit.edu
November 27, 2024 at 1:36 PM
I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
People ask for an iOS app but maybe we shouldn’t as it would cause more misery on-the-go
November 23, 2024 at 10:03 AM
People ask for an iOS app but maybe we shouldn’t as it would cause more misery on-the-go
Would be happy to schedule a chat to hear more about your experience with W&B
November 23, 2024 at 9:48 AM
Would be happy to schedule a chat to hear more about your experience with W&B
hey, sorry to hear your complaints about wandb. Have you seen the big response in that issue with options? Tables is built on parquet so it’s difficult from an architectural perspective. With the recent release Weave, there may be a path forward by using the weave backend instead of parquet…
November 23, 2024 at 9:48 AM
hey, sorry to hear your complaints about wandb. Have you seen the big response in that issue with options? Tables is built on parquet so it’s difficult from an architectural perspective. With the recent release Weave, there may be a path forward by using the weave backend instead of parquet…
Agreed, fellow competitor.
It’s the biggest hurdle I see from teams trying to build GenAI features
We need tools to lower the barrier to entry with LLM judges, existing benchmarks, manual annotation as eval collection, synthetic data… anything else?
It’s the biggest hurdle I see from teams trying to build GenAI features
We need tools to lower the barrier to entry with LLM judges, existing benchmarks, manual annotation as eval collection, synthetic data… anything else?
November 23, 2024 at 8:29 AM
Agreed, fellow competitor.
It’s the biggest hurdle I see from teams trying to build GenAI features
We need tools to lower the barrier to entry with LLM judges, existing benchmarks, manual annotation as eval collection, synthetic data… anything else?
It’s the biggest hurdle I see from teams trying to build GenAI features
We need tools to lower the barrier to entry with LLM judges, existing benchmarks, manual annotation as eval collection, synthetic data… anything else?
I think these small models are not for day to day use but instead, they’re for b2c applications of LLMs, where it’s cost/latency prohibitive to use anything else
November 22, 2024 at 8:57 AM
I think these small models are not for day to day use but instead, they’re for b2c applications of LLMs, where it’s cost/latency prohibitive to use anything else
- it really works to teach an LLM about your tool, thank you long context!
Link for the curious:
github.com/wandb/weave/...
Link for the curious:
github.com/wandb/weave/...
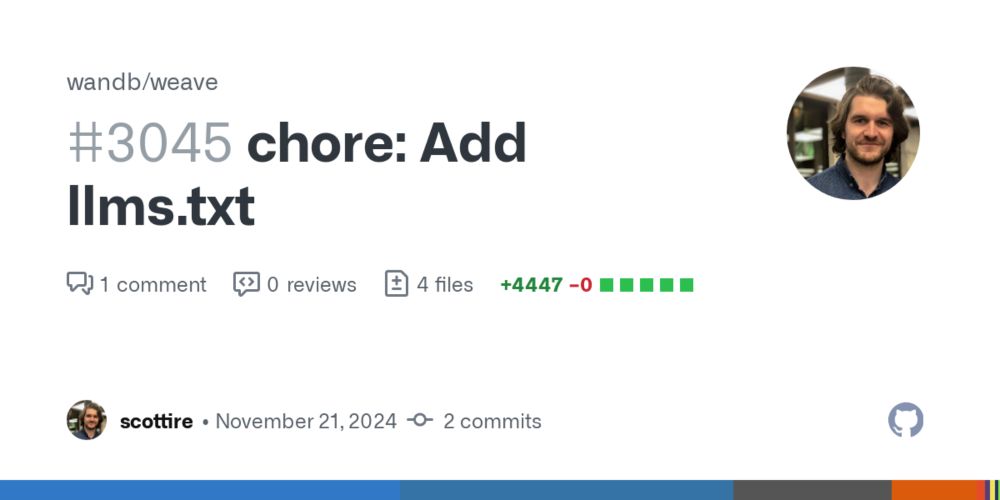
chore: Add llms.txt by scottire · Pull Request #3045 · wandb/weave
Adds a script to generate llms.txt file.
Features
Generates Docs & Optional sections
Links to Github markdown
Includes logic to remove certain files
Includes generated markdown
To generate ll...
github.com
November 21, 2024 at 7:16 PM
- it really works to teach an LLM about your tool, thank you long context!
Link for the curious:
github.com/wandb/weave/...
Link for the curious:
github.com/wandb/weave/...
- it's much better for scraping if the links included are .md files
- you need to be clear which files to include and which are optional because context blows up quickly
- automating creating your docs' llms.txt is pretty easy
- you need to be clear which files to include and which are optional because context blows up quickly
- automating creating your docs' llms.txt is pretty easy
November 21, 2024 at 7:16 PM
- it's much better for scraping if the links included are .md files
- you need to be clear which files to include and which are optional because context blows up quickly
- automating creating your docs' llms.txt is pretty easy
- you need to be clear which files to include and which are optional because context blows up quickly
- automating creating your docs' llms.txt is pretty easy
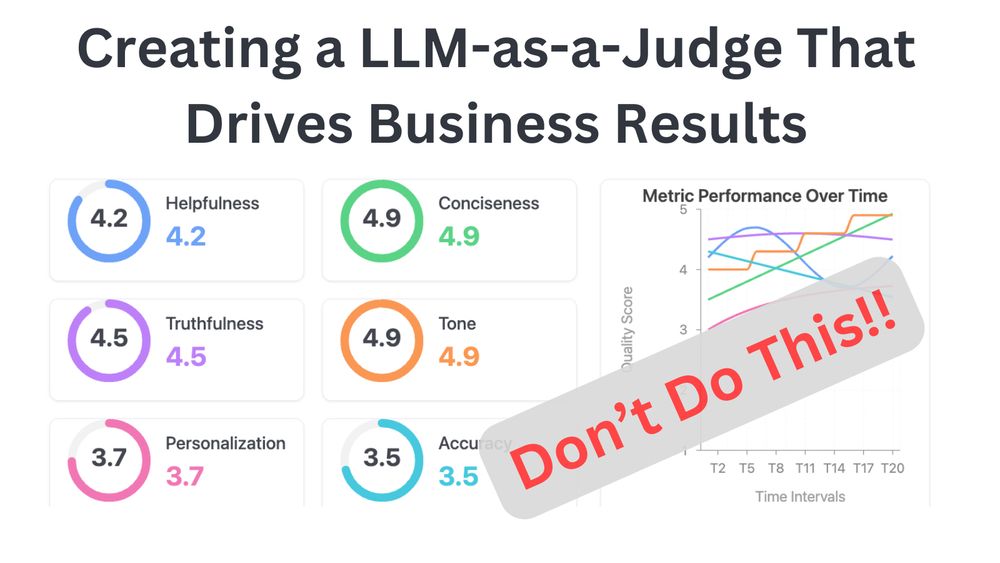
from @hamel.bsky.social’s hamel.dev/blog/posts/llm…
We're building LLM / Human "scorers" in @weightsbiases.bsky.social to have the same data model for this reason
We're building LLM / Human "scorers" in @weightsbiases.bsky.social to have the same data model for this reason
https://hamel.dev/blog/posts/llm…
November 20, 2024 at 8:30 PM
from @hamel.bsky.social’s hamel.dev/blog/posts/llm…
We're building LLM / Human "scorers" in @weightsbiases.bsky.social to have the same data model for this reason
We're building LLM / Human "scorers" in @weightsbiases.bsky.social to have the same data model for this reason

glif - MSPaint (Flux) by fab1an
glif.app
November 20, 2024 at 8:53 AM