



Scott Condron
@scottcondron.bsky.social
Working at wandb on Weave, helping teams ship AI applications
How do I get Bluesky to show me less politics and more AI/ML things? I have followed mostly people who work in AI/ML
March 9, 2025 at 11:12 AM
How do I get Bluesky to show me less politics and more AI/ML things? I have followed mostly people who work in AI/ML
Prompts within a complex system are brittle
I have seen some teams be successful by replacing prompts with smaller, more deterministic components and improved reliability with fine-tuning. Anyone else have success with this approach?
Seems to help a lot with agents
I have seen some teams be successful by replacing prompts with smaller, more deterministic components and improved reliability with fine-tuning. Anyone else have success with this approach?
Seems to help a lot with agents
November 29, 2024 at 10:16 AM
Prompts within a complex system are brittle
I have seen some teams be successful by replacing prompts with smaller, more deterministic components and improved reliability with fine-tuning. Anyone else have success with this approach?
Seems to help a lot with agents
I have seen some teams be successful by replacing prompts with smaller, more deterministic components and improved reliability with fine-tuning. Anyone else have success with this approach?
Seems to help a lot with agents
Reposted by Scott Condron

I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
web.mit.edu
November 27, 2024 at 1:36 PM
I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
If you’re taking time to enjoy your family and not building with LLMs, you’re ngmi.
America is cooked
America is cooked
November 28, 2024 at 7:01 AM
If you’re taking time to enjoy your family and not building with LLMs, you’re ngmi.
America is cooked
America is cooked
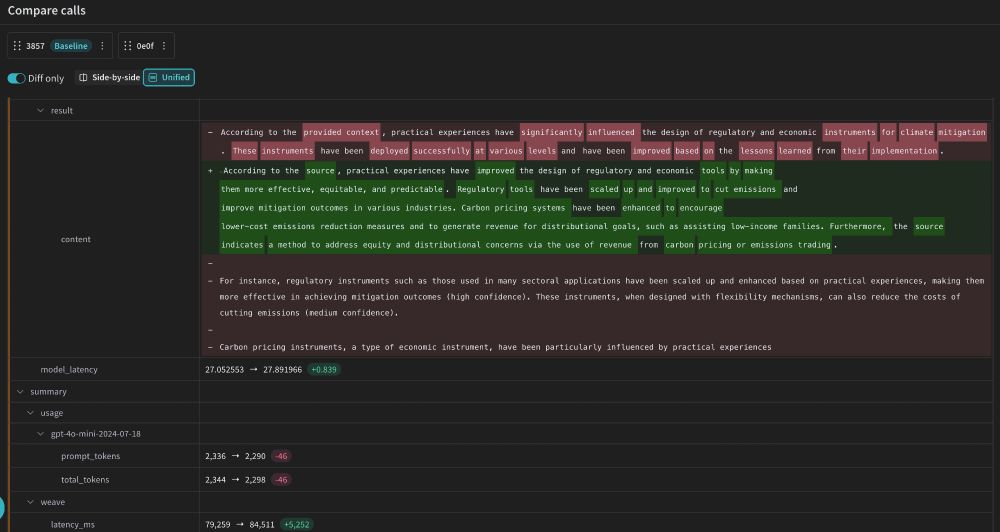
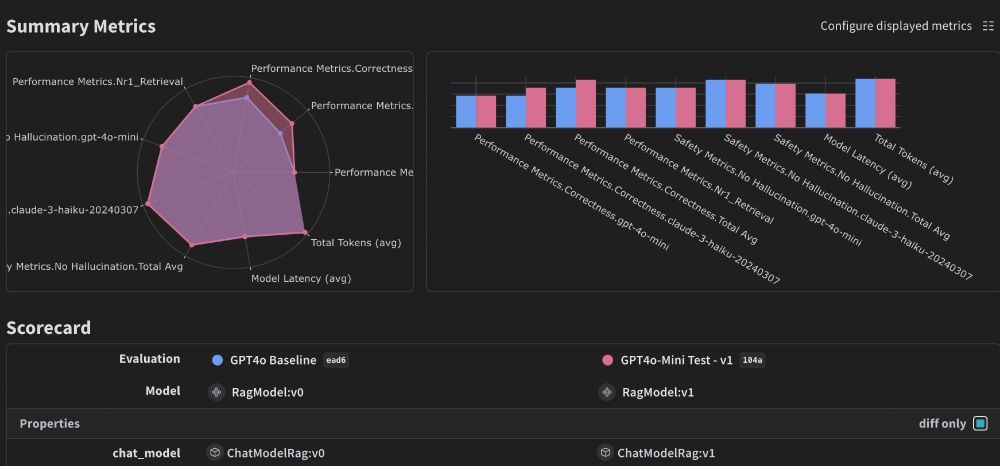
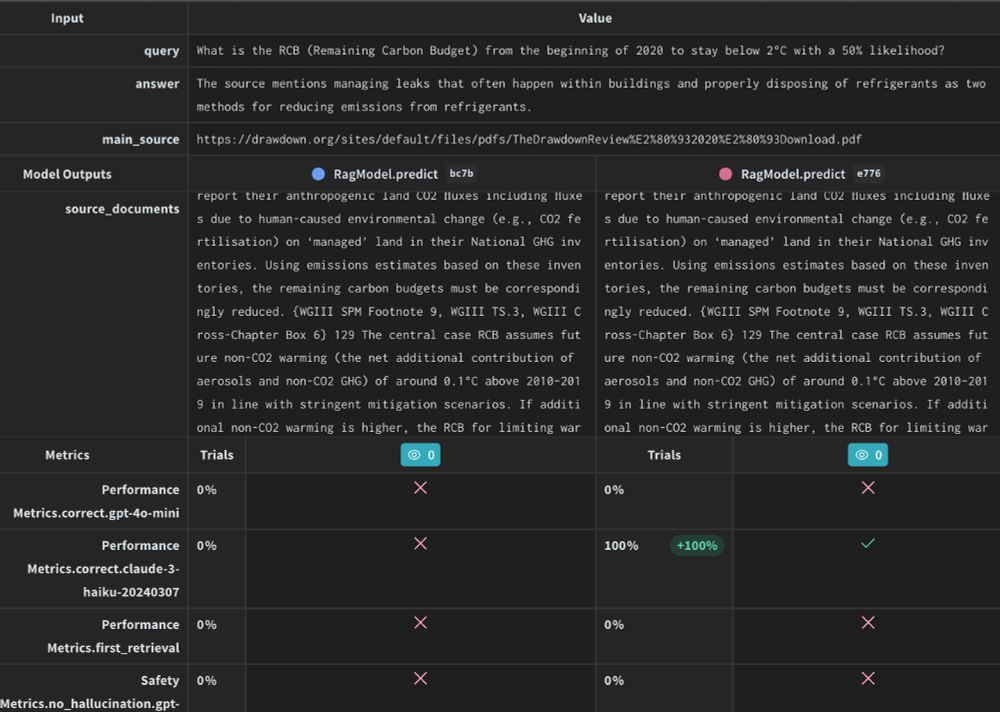
LLM app dev broke our comparison tools because tiny diffs can cause large behaviour change.
At wandb, we've spent years thinking about experiment comparison. We've added new tools for LLM app dev: code, prompts, models, configs, outputs, eval metrics, eval predictions, eval scores..
wandb.me/weave
At wandb, we've spent years thinking about experiment comparison. We've added new tools for LLM app dev: code, prompts, models, configs, outputs, eval metrics, eval predictions, eval scores..
wandb.me/weave
November 26, 2024 at 1:38 PM
LLM app dev broke our comparison tools because tiny diffs can cause large behaviour change.
At wandb, we've spent years thinking about experiment comparison. We've added new tools for LLM app dev: code, prompts, models, configs, outputs, eval metrics, eval predictions, eval scores..
wandb.me/weave
At wandb, we've spent years thinking about experiment comparison. We've added new tools for LLM app dev: code, prompts, models, configs, outputs, eval metrics, eval predictions, eval scores..
wandb.me/weave
The art of how to refer to model behaviour with tasteful non-person metaphors. Say “stochastic” you’re in one camp, say “emergent” you’re in another.
It’s a minefield out there people
It’s a minefield out there people

I've been very resistant to those in the past, but I've come round to it now
Learning to use LLMs really is a whole lot easier if you apply "person" metaphors to them
I trust people to figure out that they're not sci-fi AI entities once they really start digging in and using them
Learning to use LLMs really is a whole lot easier if you apply "person" metaphors to them
I trust people to figure out that they're not sci-fi AI entities once they really start digging in and using them
November 25, 2024 at 8:54 PM
The art of how to refer to model behaviour with tasteful non-person metaphors. Say “stochastic” you’re in one camp, say “emergent” you’re in another.
It’s a minefield out there people
It’s a minefield out there people
Reposted by Scott Condron

Being logged into wandb on your phone is a recipe for misery
November 20, 2024 at 4:09 AM
Being logged into wandb on your phone is a recipe for misery
Lessons from creating an llms.txt file
An llms.txt file is a way to tell a LLM about your website. In the .txt file, you include links to other files with info to learn more.
- the llms.txt file isn't the file you send to an LLM, you use it to generate a llms .md file
An llms.txt file is a way to tell a LLM about your website. In the .txt file, you include links to other files with info to learn more.
- the llms.txt file isn't the file you send to an LLM, you use it to generate a llms .md file
November 21, 2024 at 7:16 PM
Lessons from creating an llms.txt file
An llms.txt file is a way to tell a LLM about your website. In the .txt file, you include links to other files with info to learn more.
- the llms.txt file isn't the file you send to an LLM, you use it to generate a llms .md file
An llms.txt file is a way to tell a LLM about your website. In the .txt file, you include links to other files with info to learn more.
- the llms.txt file isn't the file you send to an LLM, you use it to generate a llms .md file
Your human and LLM judges should follow the same criteria.
Then, you can transition from manual to automated evaluation once you have inter-annotator agreement between LLM & human. You now have a faster iteration speed and the annotator can focus on finding edge cases!
Then, you can transition from manual to automated evaluation once you have inter-annotator agreement between LLM & human. You now have a faster iteration speed and the annotator can focus on finding edge cases!
November 20, 2024 at 8:30 PM
Your human and LLM judges should follow the same criteria.
Then, you can transition from manual to automated evaluation once you have inter-annotator agreement between LLM & human. You now have a faster iteration speed and the annotator can focus on finding edge cases!
Then, you can transition from manual to automated evaluation once you have inter-annotator agreement between LLM & human. You now have a faster iteration speed and the annotator can focus on finding edge cases!
Put glue on pizza

November 20, 2024 at 8:53 AM
Put glue on pizza
The most bizarre AI interview I've ever done was at wandb when as usual I asked a candidate to build an AI classifier in any language/framework of their choice..
And they nonchalantly said "I'll write it in Redstone", to which I almost let loose a chuckle until...
And they nonchalantly said "I'll write it in Redstone", to which I almost let loose a chuckle until...

November 19, 2024 at 10:16 PM
The most bizarre AI interview I've ever done was at wandb when as usual I asked a candidate to build an AI classifier in any language/framework of their choice..
And they nonchalantly said "I'll write it in Redstone", to which I almost let loose a chuckle until...
And they nonchalantly said "I'll write it in Redstone", to which I almost let loose a chuckle until...
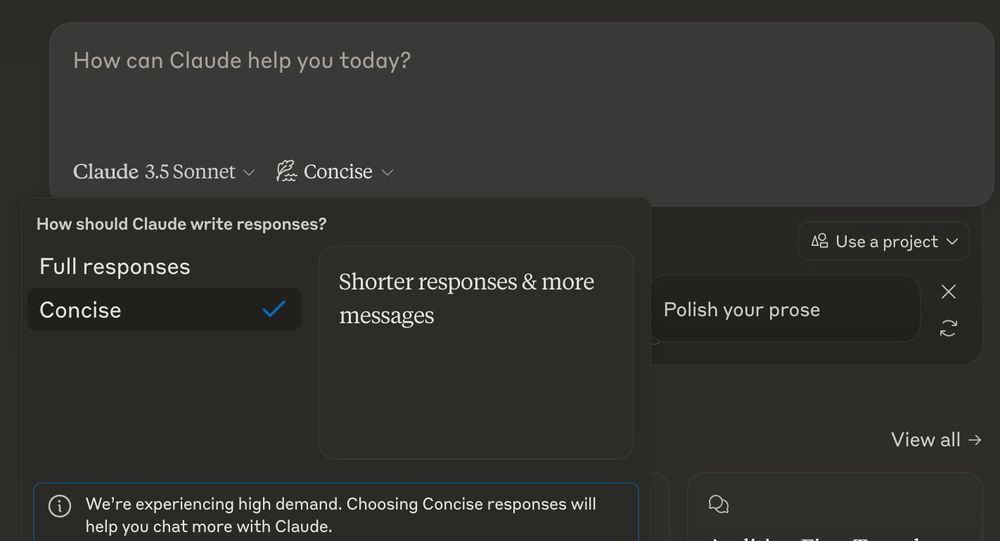
Claude defaults to concise responses when there's high demand, clever way to smooth peaks
November 19, 2024 at 8:21 PM
Claude defaults to concise responses when there's high demand, clever way to smooth peaks
Reposted by Scott Condron

We've been working on just that at @weightsbiases.bsky.social with Weave!
Weave is a lightweight llm tracing and evaluations toolkit, that focuses on letting you iterate fast and make sure that your production LLM based application is not degrading when you change prompts or models!
Weave is a lightweight llm tracing and evaluations toolkit, that focuses on letting you iterate fast and make sure that your production LLM based application is not degrading when you change prompts or models!


November 18, 2024 at 5:41 PM
We've been working on just that at @weightsbiases.bsky.social with Weave!
Weave is a lightweight llm tracing and evaluations toolkit, that focuses on letting you iterate fast and make sure that your production LLM based application is not degrading when you change prompts or models!
Weave is a lightweight llm tracing and evaluations toolkit, that focuses on letting you iterate fast and make sure that your production LLM based application is not degrading when you change prompts or models!