




Stefano Esposito
@s-esposito.bsky.social
Reposted by Stefano Esposito

🚀 New paper: ConeGS Error-Guided Densification Using Pixel Cones. We improve 3D Gaussian Splatting by placing Gaussians where they matter most: ConeGS adds primitives along pixel-view cones guided by image error, boosting quality with fewer Gaussians. baranowskibrt.github.io/conegs/

November 12, 2025 at 10:50 AM
🚀 New paper: ConeGS Error-Guided Densification Using Pixel Cones. We improve 3D Gaussian Splatting by placing Gaussians where they matter most: ConeGS adds primitives along pixel-view cones guided by image error, boosting quality with fewer Gaussians. baranowskibrt.github.io/conegs/
Reposted by Stefano Esposito

ConeGS: Error-Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives
Bartłomiej Baranowski, @s-esposito.bsky.social, @pgschossmann.bsky.social, @apchen.bsky.social, @andreasgeiger.bsky.social
arxiv.org/abs/2511.06810
Bartłomiej Baranowski, @s-esposito.bsky.social, @pgschossmann.bsky.social, @apchen.bsky.social, @andreasgeiger.bsky.social
arxiv.org/abs/2511.06810




November 11, 2025 at 3:42 PM
ConeGS: Error-Guided Densification Using Pixel Cones for Improved Reconstruction with Fewer Primitives
Bartłomiej Baranowski, @s-esposito.bsky.social, @pgschossmann.bsky.social, @apchen.bsky.social, @andreasgeiger.bsky.social
arxiv.org/abs/2511.06810
Bartłomiej Baranowski, @s-esposito.bsky.social, @pgschossmann.bsky.social, @apchen.bsky.social, @andreasgeiger.bsky.social
arxiv.org/abs/2511.06810
Reposted by Stefano Esposito

Here's a recording of my talk on how perspective works! If you're interested in learning about how picture perspective works in human vision, this is the video to watch. #visionscience
www.youtube.com/watch?v=eamc...
www.youtube.com/watch?v=eamc...

Picture Perspective and Our Eyes
YouTube video by Aaron Hertzmann
www.youtube.com
September 29, 2025 at 5:17 PM
Here's a recording of my talk on how perspective works! If you're interested in learning about how picture perspective works in human vision, this is the video to watch. #visionscience
www.youtube.com/watch?v=eamc...
www.youtube.com/watch?v=eamc...
Reposted by Stefano Esposito

𝟯𝗗-𝗟𝗔𝗧𝗧𝗘: 𝗟𝗮𝘁𝗲𝗻𝘁 𝗦𝗽𝗮𝗰𝗲 𝟯𝗗 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 𝗳𝗿𝗼𝗺 𝗧𝗲𝘅𝘁𝘂𝗮𝗹 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻𝘀
Maria Parelli, Michael Oechsle, Michael Niemeyer ... Andreas Geiger
arxiv.org/abs/2509.00269
Trending on www.scholar-inbox.com
Maria Parelli, Michael Oechsle, Michael Niemeyer ... Andreas Geiger
arxiv.org/abs/2509.00269
Trending on www.scholar-inbox.com
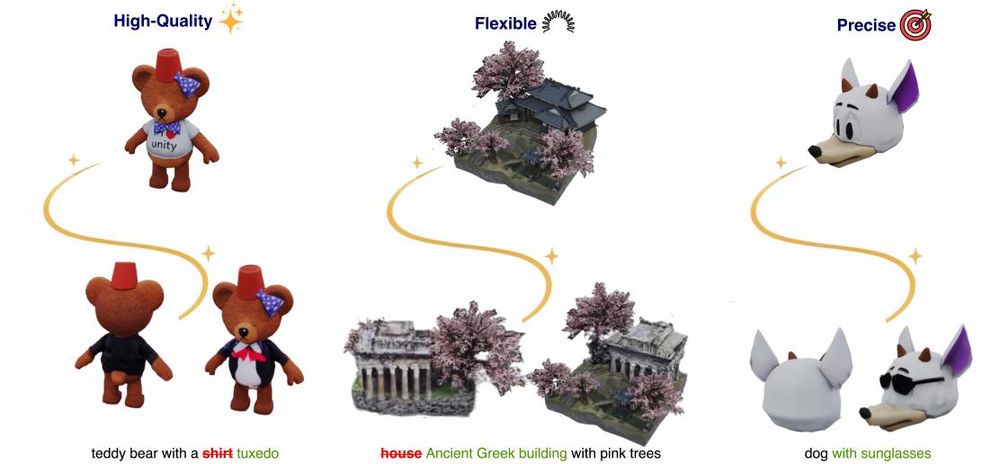

September 4, 2025 at 6:00 AM
𝟯𝗗-𝗟𝗔𝗧𝗧𝗘: 𝗟𝗮𝘁𝗲𝗻𝘁 𝗦𝗽𝗮𝗰𝗲 𝟯𝗗 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 𝗳𝗿𝗼𝗺 𝗧𝗲𝘅𝘁𝘂𝗮𝗹 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻𝘀
Maria Parelli, Michael Oechsle, Michael Niemeyer ... Andreas Geiger
arxiv.org/abs/2509.00269
Trending on www.scholar-inbox.com
Maria Parelli, Michael Oechsle, Michael Niemeyer ... Andreas Geiger
arxiv.org/abs/2509.00269
Trending on www.scholar-inbox.com
Reposted by Stefano Esposito

Reposted by Stefano Esposito

🚀 Introducing our new paper, MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models.
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
August 20, 2025 at 9:30 AM
🚀 Introducing our new paper, MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models.
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
📄 Paper: www.scholar-inbox.com/papers/He202...
arxiv.org/pdf/2508.13148
💻 Code: github.com/autonomousvi...
🌐 Project Page: cli212.github.io/MDPO/
Reposted by Stefano Esposito
Today, we moved into our new building on the CyberValley campus. Everyone is super excited. PhD students went right back to work. But wait, is there something missing? ;)




July 21, 2025 at 7:07 PM
Today, we moved into our new building on the CyberValley campus. Everyone is super excited. PhD students went right back to work. But wait, is there something missing? ;)
Reposted by Stefano Esposito
Today we had our AVG Deep Cave Expedition Day! Exploring the challenges of the (unlit, narrow, crawling-only) Hofener Höhle near Grabenstetten ..




July 18, 2025 at 3:48 PM
Today we had our AVG Deep Cave Expedition Day! Exploring the challenges of the (unlit, narrow, crawling-only) Hofener Höhle near Grabenstetten ..
Reposted by Stefano Esposito
SpatialTrackerV2: 3D Point Tracking Made Easy
Yuxi Xiao, @jianyuanwang.bsky.social, Nan Xue, @nikkar.bsky.social, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, Xiaowei Zhou
tl;dr: DAv2+VGGT->depths & poses->iterative cross-attention-based optimizer
arxiv.org/abs/2507.12462
Yuxi Xiao, @jianyuanwang.bsky.social, Nan Xue, @nikkar.bsky.social, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, Xiaowei Zhou
tl;dr: DAv2+VGGT->depths & poses->iterative cross-attention-based optimizer
arxiv.org/abs/2507.12462




July 17, 2025 at 9:43 AM
SpatialTrackerV2: 3D Point Tracking Made Easy
Yuxi Xiao, @jianyuanwang.bsky.social, Nan Xue, @nikkar.bsky.social, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, Xiaowei Zhou
tl;dr: DAv2+VGGT->depths & poses->iterative cross-attention-based optimizer
arxiv.org/abs/2507.12462
Yuxi Xiao, @jianyuanwang.bsky.social, Nan Xue, @nikkar.bsky.social, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, Xiaowei Zhou
tl;dr: DAv2+VGGT->depths & poses->iterative cross-attention-based optimizer
arxiv.org/abs/2507.12462
Reposted by Stefano Esposito
In case you find it as relaxing as we do: Here is a 2h+ video of our autonomous RL driving agent CaRL in action! @danieldauner.bsky.social @bernhard-jaeger.bsky.social @kashyap7x.bsky.social
youtube.com/watch?v=_god...
youtube.com/watch?v=_god...
CaRL: Learning Scalable Planning Policies with Simple Rewards
YouTube video by Daniel Dauner
youtube.com
July 15, 2025 at 6:17 AM
In case you find it as relaxing as we do: Here is a 2h+ video of our autonomous RL driving agent CaRL in action! @danieldauner.bsky.social @bernhard-jaeger.bsky.social @kashyap7x.bsky.social
youtube.com/watch?v=_god...
youtube.com/watch?v=_god...
Reposted by Stefano Esposito

At #ICML, you can just use scholar inbox to help you find your way through the poster sessions. It just sorts the papers according to your preferences and it really works.
www.scholar-inbox.com/conference/i... ICML 2025 Planner
www.scholar-inbox.com/conference/i... ICML 2025 Planner

July 15, 2025 at 4:41 AM
At #ICML, you can just use scholar inbox to help you find your way through the poster sessions. It just sorts the papers according to your preferences and it really works.
www.scholar-inbox.com/conference/i... ICML 2025 Planner
www.scholar-inbox.com/conference/i... ICML 2025 Planner
Reposted by Stefano Esposito

I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
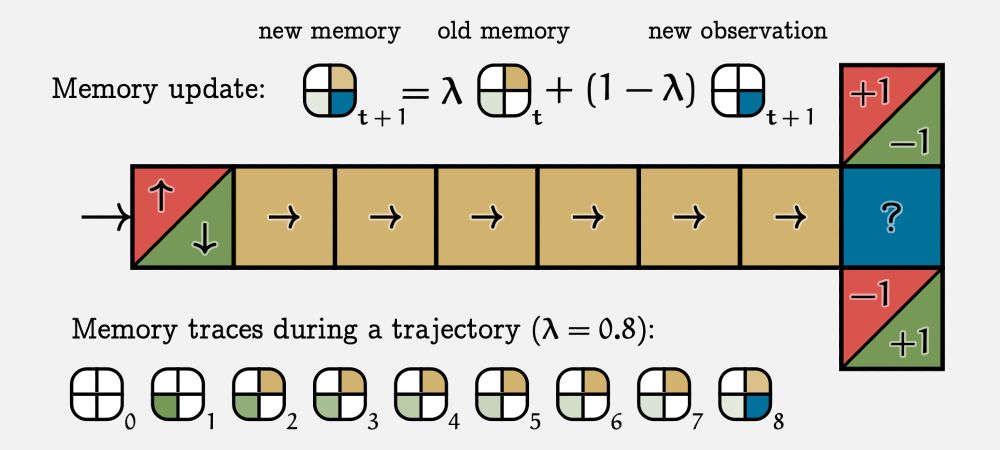
July 16, 2025 at 1:35 AM
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
Reposted by Stefano Esposito

We have released the code for our work, CaRL: Learning Scalable Planning Policies with Simple Rewards.
The repository contains the first public code base for training RL agents with the CARLA leaderboard 2.0 and nuPlan.
github.com/autonomousvi...
The repository contains the first public code base for training RL agents with the CARLA leaderboard 2.0 and nuPlan.
github.com/autonomousvi...

GitHub - autonomousvision/CaRL: [ArXiv 2025] CaRL: Learning Scalable Planning Policies with Simple Rewards
[ArXiv 2025] CaRL: Learning Scalable Planning Policies with Simple Rewards - autonomousvision/CaRL
github.com
July 15, 2025 at 4:05 PM
We have released the code for our work, CaRL: Learning Scalable Planning Policies with Simple Rewards.
The repository contains the first public code base for training RL agents with the CARLA leaderboard 2.0 and nuPlan.
github.com/autonomousvi...
The repository contains the first public code base for training RL agents with the CARLA leaderboard 2.0 and nuPlan.
github.com/autonomousvi...
Reposted by Stefano Esposito

Scaling 4D Representations
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d

July 10, 2025 at 11:52 AM
Scaling 4D Representations
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Self-supervised learning from video does scale! In our latest work, we scaled masked auto-encoding models to 22B params, boosting performance on pose estimation, tracking & more.
Paper: arxiv.org/abs/2412.15212
Code & models: github.com/google-deepmind/representations4d
Reposted by Stefano Esposito
𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝘆-𝗮𝘄𝗮𝗿𝗲 𝟰𝗗 𝗩𝗶𝗱𝗲𝗼 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝗳𝗼𝗿 𝗥𝗼𝗯𝗼𝘁 𝗠𝗮𝗻𝗶𝗽𝘂𝗹𝗮𝘁𝗶𝗼𝗻
Zeyi Liu, Shuang Li, Eric Cousineau ... Shuran Song
arxiv.org/abs/2507.01099
Trending on www.scholar-inbox.com
Zeyi Liu, Shuang Li, Eric Cousineau ... Shuran Song
arxiv.org/abs/2507.01099
Trending on www.scholar-inbox.com
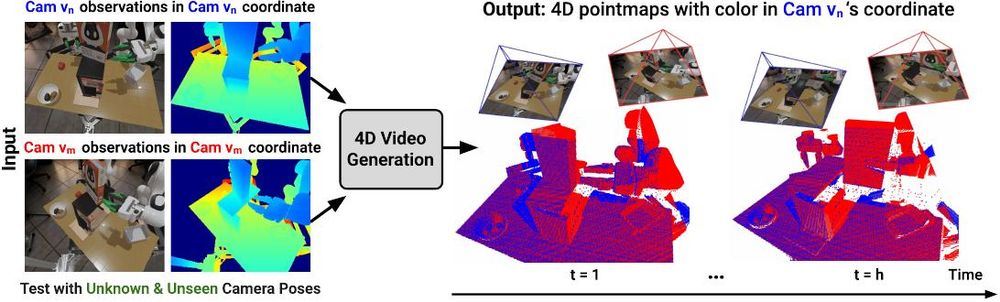
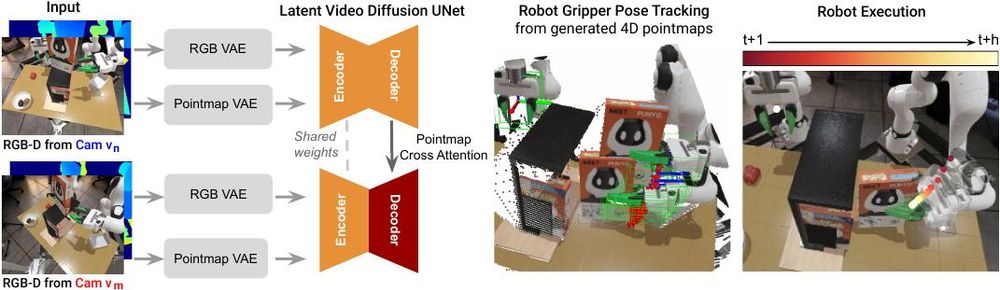
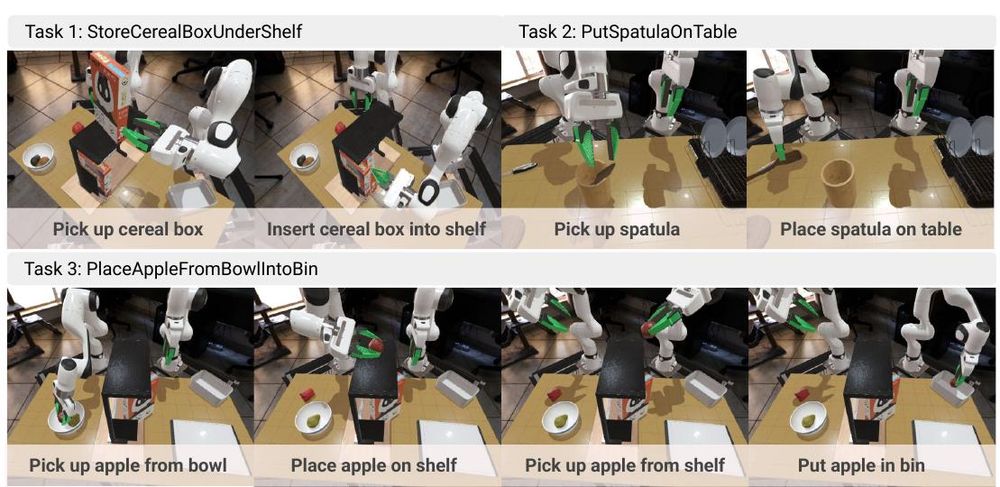
July 4, 2025 at 6:00 AM
𝗚𝗲𝗼𝗺𝗲𝘁𝗿𝘆-𝗮𝘄𝗮𝗿𝗲 𝟰𝗗 𝗩𝗶𝗱𝗲𝗼 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝗳𝗼𝗿 𝗥𝗼𝗯𝗼𝘁 𝗠𝗮𝗻𝗶𝗽𝘂𝗹𝗮𝘁𝗶𝗼𝗻
Zeyi Liu, Shuang Li, Eric Cousineau ... Shuran Song
arxiv.org/abs/2507.01099
Trending on www.scholar-inbox.com
Zeyi Liu, Shuang Li, Eric Cousineau ... Shuran Song
arxiv.org/abs/2507.01099
Trending on www.scholar-inbox.com
Reposted by Stefano Esposito
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, Jiaolong Yang
arxiv.org/abs/2507.02546
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, Jiaolong Yang
arxiv.org/abs/2507.02546




July 4, 2025 at 9:44 AM
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, Jiaolong Yang
arxiv.org/abs/2507.02546
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, Jiaolong Yang
arxiv.org/abs/2507.02546
Reposted by Stefano Esposito
I am very proud of my group! These are the nationalities of my current and past team members. Diversity is key.
🇩🇪 🇬🇷 🇮🇹 🇮🇳 🇷🇺 🇺🇦 🇨🇳 🇷🇸 🇯🇵 🇧🇪 🇺🇸 🇰🇷 🇹🇷
🇩🇪 🇬🇷 🇮🇹 🇮🇳 🇷🇺 🇺🇦 🇨🇳 🇷🇸 🇯🇵 🇧🇪 🇺🇸 🇰🇷 🇹🇷
July 3, 2025 at 10:30 AM
I am very proud of my group! These are the nationalities of my current and past team members. Diversity is key.
🇩🇪 🇬🇷 🇮🇹 🇮🇳 🇷🇺 🇺🇦 🇨🇳 🇷🇸 🇯🇵 🇧🇪 🇺🇸 🇰🇷 🇹🇷
🇩🇪 🇬🇷 🇮🇹 🇮🇳 🇷🇺 🇺🇦 🇨🇳 🇷🇸 🇯🇵 🇧🇪 🇺🇸 🇰🇷 🇹🇷
Reposted by Stefano Esposito

That’s a wrap on #CVPR2025 in Nashville! From online convos to in-person vibes, one thing’s clear: this community is STRONG 💪 Thanks for following along!
Until next time. @deblinaml.bsky.social, @jbhaurum.bsky.social, @csprofkgd.bsky.social signing off.
Until next time. @deblinaml.bsky.social, @jbhaurum.bsky.social, @csprofkgd.bsky.social signing off.

June 15, 2025 at 10:36 PM
That’s a wrap on #CVPR2025 in Nashville! From online convos to in-person vibes, one thing’s clear: this community is STRONG 💪 Thanks for following along!
Until next time. @deblinaml.bsky.social, @jbhaurum.bsky.social, @csprofkgd.bsky.social signing off.
Until next time. @deblinaml.bsky.social, @jbhaurum.bsky.social, @csprofkgd.bsky.social signing off.
Reposted by Stefano Esposito

LLM product placement and search optimization is here and it's as dystopian as you expected.

June 14, 2025 at 11:19 PM
LLM product placement and search optimization is here and it's as dystopian as you expected.
Hey #CVPR2025! Curious about this work? I'll be presenting it this morning! Poster 31, from 10:30 to 12:30 🤠
@cvprconference.bsky.social
@cvprconference.bsky.social
📢 New paper CVPR 25!
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
Can meshes capture fuzzy geometry? Volumetric Surfaces uses adaptive textured shells to model hair, fur without the splatting / volume overhead. It’s fast, looks great, and runs in real time even on budget phones.
🔗 autonomousvision.github.io/volsurfs/
📄 arxiv.org/pdf/2409.02482
June 15, 2025 at 2:24 PM
Hey #CVPR2025! Curious about this work? I'll be presenting it this morning! Poster 31, from 10:30 to 12:30 🤠
@cvprconference.bsky.social
@cvprconference.bsky.social
Reposted by Stefano Esposito

Check out the ScanNet++ workshop @CVPR on June 12 in 211 from 8:50am!
Exciting keynotes on state-of-the-art NVS & 3D understanding from Andrea Vedaldi, Cordelia Schmid, Gordon Wetzstein, Katja Schwarz, Qianqian Wang, and leading methods on the benchmark!
kaldir.vc.in.tum.de/scannetpp/cv...
Exciting keynotes on state-of-the-art NVS & 3D understanding from Andrea Vedaldi, Cordelia Schmid, Gordon Wetzstein, Katja Schwarz, Qianqian Wang, and leading methods on the benchmark!
kaldir.vc.in.tum.de/scannetpp/cv...

June 8, 2025 at 1:20 PM
Check out the ScanNet++ workshop @CVPR on June 12 in 211 from 8:50am!
Exciting keynotes on state-of-the-art NVS & 3D understanding from Andrea Vedaldi, Cordelia Schmid, Gordon Wetzstein, Katja Schwarz, Qianqian Wang, and leading methods on the benchmark!
kaldir.vc.in.tum.de/scannetpp/cv...
Exciting keynotes on state-of-the-art NVS & 3D understanding from Andrea Vedaldi, Cordelia Schmid, Gordon Wetzstein, Katja Schwarz, Qianqian Wang, and leading methods on the benchmark!
kaldir.vc.in.tum.de/scannetpp/cv...
Reposted by Stefano Esposito

Join us for the 4D Vision Workshop #CVPR on June 11 starting at 9:20am!
We'll have an incredible lineup of speakers discussing the frontier of 3D computer vision techniques for dynamic world modeling across spatial AI, robotics, astrophysics, and more.
4dvisionworkshop.github.io
We'll have an incredible lineup of speakers discussing the frontier of 3D computer vision techniques for dynamic world modeling across spatial AI, robotics, astrophysics, and more.
4dvisionworkshop.github.io

June 9, 2025 at 8:02 AM
Join us for the 4D Vision Workshop #CVPR on June 11 starting at 9:20am!
We'll have an incredible lineup of speakers discussing the frontier of 3D computer vision techniques for dynamic world modeling across spatial AI, robotics, astrophysics, and more.
4dvisionworkshop.github.io
We'll have an incredible lineup of speakers discussing the frontier of 3D computer vision techniques for dynamic world modeling across spatial AI, robotics, astrophysics, and more.
4dvisionworkshop.github.io
Reposted by Stefano Esposito

This Wednesday (1-6PM, Room 106A) at CVPR @cvprconference.bsky.social we have a great lineup of keynote speakers, posters, and spotlights on neural fields and beyond: neural-bcc.github.io
Have a question you want answered by a panel of experts in the field? Send it to us via: tinyurl.com/bdddf36f
Have a question you want answered by a panel of experts in the field? Send it to us via: tinyurl.com/bdddf36f

June 9, 2025 at 8:34 PM
This Wednesday (1-6PM, Room 106A) at CVPR @cvprconference.bsky.social we have a great lineup of keynote speakers, posters, and spotlights on neural fields and beyond: neural-bcc.github.io
Have a question you want answered by a panel of experts in the field? Send it to us via: tinyurl.com/bdddf36f
Have a question you want answered by a panel of experts in the field? Send it to us via: tinyurl.com/bdddf36f
Reposted by Stefano Esposito

Excited to present our #CVPR2025 paper DepthSplat next week!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
🏠 Introducing DepthSplat: a framework that connects Gaussian splatting with single- and multi-view depth estimation. This enables robust depth modeling and high-quality view synthesis with state-of-the-art results on ScanNet, RealEstate10K, and DL3DV.
🔗 haofeixu.github.io/depthsplat/
🔗 haofeixu.github.io/depthsplat/
June 5, 2025 at 12:09 PM
Excited to present our #CVPR2025 paper DepthSplat next week!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
DepthSplat is a feed-forward model that achieves high-quality Gaussian reconstruction and view synthesis in just 0.6 seconds.
Looking forward to great conversations at the conference!
Reposted by Stefano Esposito

🚗 Pseudo-simulation combines the efficiency of open-loop and robustness of closed-loop evaluation. It uses real data + 3D Gaussian Splatting synthetic views to assess error recovery, achieving strong correlation with closed-loop simulations while requiring 6x less compute. arxiv.org/abs/2506.04218

June 5, 2025 at 4:21 AM
🚗 Pseudo-simulation combines the efficiency of open-loop and robustness of closed-loop evaluation. It uses real data + 3D Gaussian Splatting synthetic views to assess error recovery, achieving strong correlation with closed-loop simulations while requiring 6x less compute. arxiv.org/abs/2506.04218