




Rohit P. Ojha, DrPH, FACE
@rohitpojha.bsky.social
Director & Associate Professor, JPS Health Network Center for Epidemiology & Healthcare Delivery Research | Causal inference • Prediction • Evidence synthesis
Reposted by Rohit P. Ojha, DrPH, FACE

Published: the paper 'On the uses and abuses of Regression Models: a Call for Reform of Statistical Practice and Teaching' by John Carlin and Margarita Moreno-Betancur in the latest issue of Statistics in Medicine onlinelibrary.wiley.com/doi/10.1002/... (1/8)
onlinelibrary.wiley.com
June 26, 2025 at 12:23 PM
Published: the paper 'On the uses and abuses of Regression Models: a Call for Reform of Statistical Practice and Teaching' by John Carlin and Margarita Moreno-Betancur in the latest issue of Statistics in Medicine onlinelibrary.wiley.com/doi/10.1002/... (1/8)
Hope and hype are not substitutes for evidence.
Nevertheless, healthcare AI tools are often promoted without the rigorous evaluation expected of other healthcare interventions. Understanding the benefits and harms is essential before deploying these tools at scale.
#Healthcare #AI
1/3
Nevertheless, healthcare AI tools are often promoted without the rigorous evaluation expected of other healthcare interventions. Understanding the benefits and harms is essential before deploying these tools at scale.
#Healthcare #AI
1/3
May 6, 2025 at 2:12 PM
Hope and hype are not substitutes for evidence.
Nevertheless, healthcare AI tools are often promoted without the rigorous evaluation expected of other healthcare interventions. Understanding the benefits and harms is essential before deploying these tools at scale.
#Healthcare #AI
1/3
Nevertheless, healthcare AI tools are often promoted without the rigorous evaluation expected of other healthcare interventions. Understanding the benefits and harms is essential before deploying these tools at scale.
#Healthcare #AI
1/3
Reposted by Rohit P. Ojha, DrPH, FACE

"People Profit from being ambiguous about their research goals"
Julia concludes by highlighting the need for structural change. Rigorous causal research takes time and thought. That's not possible if we're still expecting PhD students to publish 3-5 papers.
Julia concludes by highlighting the need for structural change. Rigorous causal research takes time and thought. That's not possible if we're still expecting PhD students to publish 3-5 papers.

April 10, 2025 at 3:21 PM
"People Profit from being ambiguous about their research goals"
Julia concludes by highlighting the need for structural change. Rigorous causal research takes time and thought. That's not possible if we're still expecting PhD students to publish 3-5 papers.
Julia concludes by highlighting the need for structural change. Rigorous causal research takes time and thought. That's not possible if we're still expecting PhD students to publish 3-5 papers.
Reposted by Rohit P. Ojha, DrPH, FACE

You know Pearl's causal ladder, but Julia introduced a different type of ladder : how can we get cutting edge causal inference methods into applications? #EuroCIM2025 so important!

April 10, 2025 at 3:06 PM
You know Pearl's causal ladder, but Julia introduced a different type of ladder : how can we get cutting edge causal inference methods into applications? #EuroCIM2025 so important!
Reposted by Rohit P. Ojha, DrPH, FACE
This 'dataset first' approach leads some scientists to conduct weak research because 'this is the best we can do in our data'.
If a dataset is inappropriate for a particular question, the best you can do is NOT use it.
It shouldn't be our job, as scientists, to be showcasing datasets.
If a dataset is inappropriate for a particular question, the best you can do is NOT use it.
It shouldn't be our job, as scientists, to be showcasing datasets.
March 31, 2025 at 12:18 PM
This 'dataset first' approach leads some scientists to conduct weak research because 'this is the best we can do in our data'.
If a dataset is inappropriate for a particular question, the best you can do is NOT use it.
It shouldn't be our job, as scientists, to be showcasing datasets.
If a dataset is inappropriate for a particular question, the best you can do is NOT use it.
It shouldn't be our job, as scientists, to be showcasing datasets.
Reposted by Rohit P. Ojha, DrPH, FACE

NEW PAPER in the @bmj.com "PROBAST+AI: an updated quality, risk of bias, and applicability assessment tool for prediction models using regression or #artificialintelligence methods"
www.bmj.com/content/388/...
#StatsSky #MLSky #AI #MethodologyMatters
www.bmj.com/content/388/...
#StatsSky #MLSky #AI #MethodologyMatters

March 24, 2025 at 11:53 AM
NEW PAPER in the @bmj.com "PROBAST+AI: an updated quality, risk of bias, and applicability assessment tool for prediction models using regression or #artificialintelligence methods"
www.bmj.com/content/388/...
#StatsSky #MLSky #AI #MethodologyMatters
www.bmj.com/content/388/...
#StatsSky #MLSky #AI #MethodologyMatters
Reposted by Rohit P. Ojha, DrPH, FACE

NEW: LibGen contains millions of pirated books and research papers, built over nearly two decades. From court documents, we know that Meta torrented a version of it to build its AI. Today, @theatlantic.com presents an analysis of the data set by @alexreisner.bsky.social. Search through it yourself:

The Unbelievable Scale of AI’s Pirated-Books Problem
Meta pirated millions of books to train its AI. Search through them here.
www.theatlantic.com
March 20, 2025 at 11:38 AM
NEW: LibGen contains millions of pirated books and research papers, built over nearly two decades. From court documents, we know that Meta torrented a version of it to build its AI. Today, @theatlantic.com presents an analysis of the data set by @alexreisner.bsky.social. Search through it yourself:
To organizations considering this option from OpenAI: Why not hire a human PhD-level researcher instead?
To PhD-level researchers: Here is our fair market value according to OpenAI.
#EpiSky #StatsSky #AcademicSky
To PhD-level researchers: Here is our fair market value according to OpenAI.
#EpiSky #StatsSky #AcademicSky

March 5, 2025 at 6:05 PM
To organizations considering this option from OpenAI: Why not hire a human PhD-level researcher instead?
To PhD-level researchers: Here is our fair market value according to OpenAI.
#EpiSky #StatsSky #AcademicSky
To PhD-level researchers: Here is our fair market value according to OpenAI.
#EpiSky #StatsSky #AcademicSky
Reposted by Rohit P. Ojha, DrPH, FACE

1/ When using observational data for #causalinference, emulating a target trial helps solve some problems... but not all problems.
In a new paper, we explain why and when the #TargetTrial framework is helpful.
www.acpjournals.org/doi/10.7326/...
Joint work with my colleagues @causalab.bsky.social
In a new paper, we explain why and when the #TargetTrial framework is helpful.
www.acpjournals.org/doi/10.7326/...
Joint work with my colleagues @causalab.bsky.social

February 18, 2025 at 1:08 PM
1/ When using observational data for #causalinference, emulating a target trial helps solve some problems... but not all problems.
In a new paper, we explain why and when the #TargetTrial framework is helpful.
www.acpjournals.org/doi/10.7326/...
Joint work with my colleagues @causalab.bsky.social
In a new paper, we explain why and when the #TargetTrial framework is helpful.
www.acpjournals.org/doi/10.7326/...
Joint work with my colleagues @causalab.bsky.social
Reposted by Rohit P. Ojha, DrPH, FACE
1/
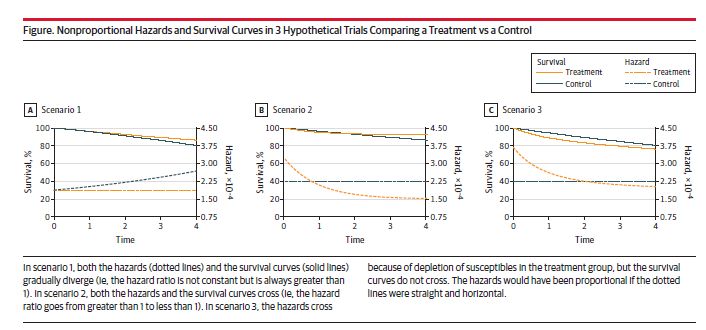
If you were taught to test for proportional hazards, talk to your teacher.
The proportional hazards assumption is implausible in most #randomized and #observational studies because the hazard ratios aren't expected to be constant during the follow-up. So "testing" is futile.
But there is more 👇
If you were taught to test for proportional hazards, talk to your teacher.
The proportional hazards assumption is implausible in most #randomized and #observational studies because the hazard ratios aren't expected to be constant during the follow-up. So "testing" is futile.
But there is more 👇
February 3, 2025 at 2:51 PM
1/
If you were taught to test for proportional hazards, talk to your teacher.
The proportional hazards assumption is implausible in most #randomized and #observational studies because the hazard ratios aren't expected to be constant during the follow-up. So "testing" is futile.
But there is more 👇
If you were taught to test for proportional hazards, talk to your teacher.
The proportional hazards assumption is implausible in most #randomized and #observational studies because the hazard ratios aren't expected to be constant during the follow-up. So "testing" is futile.
But there is more 👇
Reposted by Rohit P. Ojha, DrPH, FACE

NEW PAPER
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....

January 27, 2025 at 8:01 AM
NEW PAPER
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Our systematic review of EHR-based prediction models to identify patients who may benefit from HIV PrEP:
• 7 models identified
• 𝗔𝗹𝗹 𝗺𝗼𝗱𝗲𝗹𝘀 𝗵𝗮𝗱 𝗵𝗶𝗴𝗵 𝗿𝗶𝘀𝗸 𝗼𝗳 𝗯𝗶𝗮𝘀
• Most reports were missing critical information
Pre-print available here:
www.medrxiv.org/content/10.1...
#EpiSky
• 7 models identified
• 𝗔𝗹𝗹 𝗺𝗼𝗱𝗲𝗹𝘀 𝗵𝗮𝗱 𝗵𝗶𝗴𝗵 𝗿𝗶𝘀𝗸 𝗼𝗳 𝗯𝗶𝗮𝘀
• Most reports were missing critical information
Pre-print available here:
www.medrxiv.org/content/10.1...
#EpiSky

Electronic Health Record-Based Prediction Models to Inform Decisions about HIV Pre-exposure Prophylaxis: A Systematic Review
Background Several clinical prediction models have been developed using electronic health records data to help inform decisions about HIV pre-exposure prophylaxis (PrEP) prescribing, but the character...
www.medrxiv.org
January 25, 2025 at 4:46 PM
Our systematic review of EHR-based prediction models to identify patients who may benefit from HIV PrEP:
• 7 models identified
• 𝗔𝗹𝗹 𝗺𝗼𝗱𝗲𝗹𝘀 𝗵𝗮𝗱 𝗵𝗶𝗴𝗵 𝗿𝗶𝘀𝗸 𝗼𝗳 𝗯𝗶𝗮𝘀
• Most reports were missing critical information
Pre-print available here:
www.medrxiv.org/content/10.1...
#EpiSky
• 7 models identified
• 𝗔𝗹𝗹 𝗺𝗼𝗱𝗲𝗹𝘀 𝗵𝗮𝗱 𝗵𝗶𝗴𝗵 𝗿𝗶𝘀𝗸 𝗼𝗳 𝗯𝗶𝗮𝘀
• Most reports were missing critical information
Pre-print available here:
www.medrxiv.org/content/10.1...
#EpiSky
Reposted by Rohit P. Ojha, DrPH, FACE

January 20, 2025 at 7:27 AM
What effect is being estimated? Clarifying this question can help decision-makers better use the evidence. Recent developments in defining estimands (i.e., the effect of interest) can help.
Here’s a nice summary to help think about estimands:
academic.oup.com/aje/article/...
#EpiSky #CausalSky
Here’s a nice summary to help think about estimands:
academic.oup.com/aje/article/...
#EpiSky #CausalSky

Eliminating Ambiguous Treatment Effects Using Estimands
Abstract. Most reported treatment effects in medical research studies are ambiguously defined, which can lead to misinterpretation of study results. This i
academic.oup.com
January 2, 2025 at 3:18 PM
What effect is being estimated? Clarifying this question can help decision-makers better use the evidence. Recent developments in defining estimands (i.e., the effect of interest) can help.
Here’s a nice summary to help think about estimands:
academic.oup.com/aje/article/...
#EpiSky #CausalSky
Here’s a nice summary to help think about estimands:
academic.oup.com/aje/article/...
#EpiSky #CausalSky
LLMs may be good for certain tasks, but encoding causal knowledge is not one of them.

New working paper out today with @epiellie.bsky.social called "Do LLMs Act as Repositories of Causal Knowledge?"
Can LLMs (ie ChatGPT) build for us the causal models we need to identify an effect? There are reasons to expect they could. But can they? Well, not really, no.
arxiv.org/html/2412.10...
Can LLMs (ie ChatGPT) build for us the causal models we need to identify an effect? There are reasons to expect they could. But can they? Well, not really, no.
arxiv.org/html/2412.10...
Do LLMs Act as Repositories of Causal Knowledge?
arxiv.org
December 18, 2024 at 2:24 AM
LLMs may be good for certain tasks, but encoding causal knowledge is not one of them.
Many measures used in evaluating AI prediction models do not measure the intended parameter. AUC, calibration plot, and decision curve analysis are recommended for evaluation.
NEW PREPRINT
A detailed overview of 32 popular predictive performance metrics for prediction models
arxiv.org/abs/2412.10288
A detailed overview of 32 popular predictive performance metrics for prediction models
arxiv.org/abs/2412.10288

December 16, 2024 at 2:31 PM
Many measures used in evaluating AI prediction models do not measure the intended parameter. AUC, calibration plot, and decision curve analysis are recommended for evaluation.
Outdated: Describing an exposure-outcome study as a “retrospective cohort study” just because the data were already collected.
Updated: Describing a study based on timing of exposure and outcome measurement. More informative about timing of events and potential biases.
Updated: Describing a study based on timing of exposure and outcome measurement. More informative about timing of events and potential biases.

December 7, 2024 at 3:21 PM
Outdated: Describing an exposure-outcome study as a “retrospective cohort study” just because the data were already collected.
Updated: Describing a study based on timing of exposure and outcome measurement. More informative about timing of events and potential biases.
Updated: Describing a study based on timing of exposure and outcome measurement. More informative about timing of events and potential biases.
Reposted by Rohit P. Ojha, DrPH, FACE
Characterising #machinelearning studies in healthcare, the full set
Weak design/methods tinyurl.com/yc4easr9
Poor reporting tinyurl.com/55ed3j9k
High risk of bias tinyurl.com/yk6m9sx5
Full of Spin tinyurl.com/yckubrnp
Not open science tinyurl.com/437bfz8f
#StatsSky #MLSky #mustdobetter 😬
Weak design/methods tinyurl.com/yc4easr9
Poor reporting tinyurl.com/55ed3j9k
High risk of bias tinyurl.com/yk6m9sx5
Full of Spin tinyurl.com/yckubrnp
Not open science tinyurl.com/437bfz8f
#StatsSky #MLSky #mustdobetter 😬

November 13, 2024 at 10:28 PM
Characterising #machinelearning studies in healthcare, the full set
Weak design/methods tinyurl.com/yc4easr9
Poor reporting tinyurl.com/55ed3j9k
High risk of bias tinyurl.com/yk6m9sx5
Full of Spin tinyurl.com/yckubrnp
Not open science tinyurl.com/437bfz8f
#StatsSky #MLSky #mustdobetter 😬
Weak design/methods tinyurl.com/yc4easr9
Poor reporting tinyurl.com/55ed3j9k
High risk of bias tinyurl.com/yk6m9sx5
Full of Spin tinyurl.com/yckubrnp
Not open science tinyurl.com/437bfz8f
#StatsSky #MLSky #mustdobetter 😬
Reposted by Rohit P. Ojha, DrPH, FACE

In April I predicted LLMs were reaching diminishing returns. 𝗔𝗹𝗹 𝘀𝗶𝗴𝗻𝘀 𝗻𝗼𝘄 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝘁𝗵𝗮𝘁. 6 related predictions below for 2024 also were correct.
That leaves 1 open: 𝗱𝗶𝗺𝗶𝗻𝗶𝘀𝗵𝗶𝗻𝗴 𝗿𝗲𝘁𝘂𝗿𝗻𝘀 𝗹𝗲𝗮𝗱 𝘁𝗼 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲 𝗼𝗳 𝗚𝗲𝗻𝗔𝗜 𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻𝘀.
Hasn’t happened yet but could—as the implications of slowdown set in.
That leaves 1 open: 𝗱𝗶𝗺𝗶𝗻𝗶𝘀𝗵𝗶𝗻𝗴 𝗿𝗲𝘁𝘂𝗿𝗻𝘀 𝗹𝗲𝗮𝗱 𝘁𝗼 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲 𝗼𝗳 𝗚𝗲𝗻𝗔𝗜 𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻𝘀.
Hasn’t happened yet but could—as the implications of slowdown set in.

November 12, 2024 at 4:16 AM
In April I predicted LLMs were reaching diminishing returns. 𝗔𝗹𝗹 𝘀𝗶𝗴𝗻𝘀 𝗻𝗼𝘄 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝘁𝗵𝗮𝘁. 6 related predictions below for 2024 also were correct.
That leaves 1 open: 𝗱𝗶𝗺𝗶𝗻𝗶𝘀𝗵𝗶𝗻𝗴 𝗿𝗲𝘁𝘂𝗿𝗻𝘀 𝗹𝗲𝗮𝗱 𝘁𝗼 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲 𝗼𝗳 𝗚𝗲𝗻𝗔𝗜 𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻𝘀.
Hasn’t happened yet but could—as the implications of slowdown set in.
That leaves 1 open: 𝗱𝗶𝗺𝗶𝗻𝗶𝘀𝗵𝗶𝗻𝗴 𝗿𝗲𝘁𝘂𝗿𝗻𝘀 𝗹𝗲𝗮𝗱 𝘁𝗼 𝗰𝗼𝗹𝗹𝗮𝗽𝘀𝗲 𝗼𝗳 𝗚𝗲𝗻𝗔𝗜 𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻𝘀.
Hasn’t happened yet but could—as the implications of slowdown set in.
Reposted by Rohit P. Ojha, DrPH, FACE

We've put together an #Epidemiology / #EpiSky starter pack with some of our members & friends! Please share!
TESTIMONIALS
'The original data scientists' - @miguelhernan.bsky.social
'The new rock stars' - @nytimes.com
'A science of high importance' - @natureportfolio.bsky.social
go.bsky.app/K6DXCGi
TESTIMONIALS
'The original data scientists' - @miguelhernan.bsky.social
'The new rock stars' - @nytimes.com
'A science of high importance' - @natureportfolio.bsky.social
go.bsky.app/K6DXCGi
November 12, 2024 at 5:06 PM
We've put together an #Epidemiology / #EpiSky starter pack with some of our members & friends! Please share!
TESTIMONIALS
'The original data scientists' - @miguelhernan.bsky.social
'The new rock stars' - @nytimes.com
'A science of high importance' - @natureportfolio.bsky.social
go.bsky.app/K6DXCGi
TESTIMONIALS
'The original data scientists' - @miguelhernan.bsky.social
'The new rock stars' - @nytimes.com
'A science of high importance' - @natureportfolio.bsky.social
go.bsky.app/K6DXCGi
Reposted by Rohit P. Ojha, DrPH, FACE
In clinical research, you will often receive feedback on study design, stats, and/or data analysis from an editor or reviewer that is simply wrong. Here is a list of common "statistical myths" and references you can use to push back.
discourse.datamethods.org/t/reference-...
discourse.datamethods.org/t/reference-...

Reference Collection to push back against "Common Statistical Myths"
Note: This topic is a wiki, meaning that this main body of the topic can be edited by others. Use the Reply button only to post questions or comments about material contained in the body, or to sugge...
discourse.datamethods.org
November 12, 2024 at 6:19 AM
In clinical research, you will often receive feedback on study design, stats, and/or data analysis from an editor or reviewer that is simply wrong. Here is a list of common "statistical myths" and references you can use to push back.
discourse.datamethods.org/t/reference-...
discourse.datamethods.org/t/reference-...
Reposted by Rohit P. Ojha, DrPH, FACE
NEW PAPER in the BMJ (with richarddriley.bsky.social) - 1st in a 3 part series on the ‘Evaluation of clinical prediction models’. Part 1 is ‘from development to external validation’.
—> tinyurl.com/n8fy5xvj
—> tinyurl.com/n8fy5xvj

January 8, 2024 at 12:31 PM
NEW PAPER in the BMJ (with richarddriley.bsky.social) - 1st in a 3 part series on the ‘Evaluation of clinical prediction models’. Part 1 is ‘from development to external validation’.
—> tinyurl.com/n8fy5xvj
—> tinyurl.com/n8fy5xvj