




Pablo Samuel Castro
@pcastr.bsky.social
Señor swesearcher @ Google DeepMind, adjunct prof at Université de Montréal and Mila. Musician. From 🇪🇨 living in 🇨🇦.
https://psc-g.github.io/
https://psc-g.github.io/
Read the full paper here:
arxiv.org/abs/2510.16175
(I'll make a blog post soon, my webpage is quite out of date...)
18/X
arxiv.org/abs/2510.16175
(I'll make a blog post soon, my webpage is quite out of date...)
18/X

The Formalism-Implementation Gap in Reinforcement Learning Research
The last decade has seen an upswing in interest and adoption of reinforcement learning (RL) techniques, in large part due to its demonstrated capabilities at performing certain tasks at "super-human l...
arxiv.org
October 28, 2025 at 1:56 PM
Read the full paper here:
arxiv.org/abs/2510.16175
(I'll make a blog post soon, my webpage is quite out of date...)
18/X
arxiv.org/abs/2510.16175
(I'll make a blog post soon, my webpage is quite out of date...)
18/X
In summary, we should approach benchmarks like the ALE for "insight-oriented exploratory research" (Herrmann et al., 2024) and scientific testing (Jordan et al., 2024).
Advancing RL science in this manner could lead to the next big breakthrough...
17/X
Advancing RL science in this manner could lead to the next big breakthrough...
17/X
October 28, 2025 at 1:56 PM
In summary, we should approach benchmarks like the ALE for "insight-oriented exploratory research" (Herrmann et al., 2024) and scientific testing (Jordan et al., 2024).
Advancing RL science in this manner could lead to the next big breakthrough...
17/X
Advancing RL science in this manner could lead to the next big breakthrough...
17/X
Indeed, over-indexing on a single flavor of research, whether it be LLMs or reinforcement learning from human feedback (RLHF), has an opportunity cost in terms of potential, and unanticipated, breakthroughs.
16/X
16/X
October 28, 2025 at 1:56 PM
Indeed, over-indexing on a single flavor of research, whether it be LLMs or reinforcement learning from human feedback (RLHF), has an opportunity cost in terms of potential, and unanticipated, breakthroughs.
16/X
16/X
In an era of LLM-obsession, RL research on video games might seem antiquated or irrelevant. I often see this in reviews: "the ALE is solved", "...not interesting", etc.
I refute that success of LLMs rests on decades of academic research not premised on this application.
15/X
I refute that success of LLMs rests on decades of academic research not premised on this application.
15/X
October 28, 2025 at 1:56 PM
In an era of LLM-obsession, RL research on video games might seem antiquated or irrelevant. I often see this in reviews: "the ALE is solved", "...not interesting", etc.
I refute that success of LLMs rests on decades of academic research not premised on this application.
15/X
I refute that success of LLMs rests on decades of academic research not premised on this application.
15/X
What makes a good benchmark?
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X

October 28, 2025 at 1:56 PM
What makes a good benchmark?
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
Aggregate results?
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X


October 28, 2025 at 1:56 PM
Aggregate results?
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
Train/Eval env sets?
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X

October 28, 2025 at 1:56 PM
Train/Eval env sets?
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
Experiment length?
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X


October 28, 2025 at 1:56 PM
Experiment length?
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
Discount factor?
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X

October 28, 2025 at 1:56 PM
Discount factor?
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
Let's move to measuring progress & evaluating methods. Lots of great literature on this already, but there a few points I make in the paper which I think are worth highlighting.
We'll use the ALE as an illustrative example.
tl;dr: be more explicit about evaluation process!
9/X
We'll use the ALE as an illustrative example.
tl;dr: be more explicit about evaluation process!
9/X
October 28, 2025 at 1:56 PM
Let's move to measuring progress & evaluating methods. Lots of great literature on this already, but there a few points I make in the paper which I think are worth highlighting.
We'll use the ALE as an illustrative example.
tl;dr: be more explicit about evaluation process!
9/X
We'll use the ALE as an illustrative example.
tl;dr: be more explicit about evaluation process!
9/X
Environment dynamics?
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X

October 28, 2025 at 1:56 PM
Environment dynamics?
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
Reward function?
Since reward magnitudes vary a lot across games, Mnih et al. (2015) clipped rewards at [-1, 1] to be able to have global hparams. This can result in aliased rewards, which increases the partial observability of the system!
7/X
Since reward magnitudes vary a lot across games, Mnih et al. (2015) clipped rewards at [-1, 1] to be able to have global hparams. This can result in aliased rewards, which increases the partial observability of the system!
7/X
October 28, 2025 at 1:56 PM
Reward function?
Since reward magnitudes vary a lot across games, Mnih et al. (2015) clipped rewards at [-1, 1] to be able to have global hparams. This can result in aliased rewards, which increases the partial observability of the system!
7/X
Since reward magnitudes vary a lot across games, Mnih et al. (2015) clipped rewards at [-1, 1] to be able to have global hparams. This can result in aliased rewards, which increases the partial observability of the system!
7/X
Initial state distribution?
Since Atari games are deterministic, Mnih et al. (2015) added a series of no-op actions for non-determinancy. This is more interesting, but does move away from the original Atari games, thus part of the formalism-implementation gap.
6/X
Since Atari games are deterministic, Mnih et al. (2015) added a series of no-op actions for non-determinancy. This is more interesting, but does move away from the original Atari games, thus part of the formalism-implementation gap.
6/X
October 28, 2025 at 1:56 PM
Initial state distribution?
Since Atari games are deterministic, Mnih et al. (2015) added a series of no-op actions for non-determinancy. This is more interesting, but does move away from the original Atari games, thus part of the formalism-implementation gap.
6/X
Since Atari games are deterministic, Mnih et al. (2015) added a series of no-op actions for non-determinancy. This is more interesting, but does move away from the original Atari games, thus part of the formalism-implementation gap.
6/X
What about actions?
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
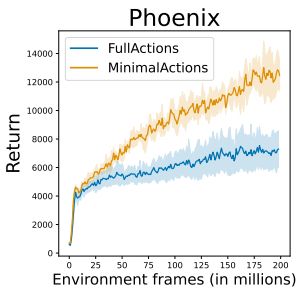
October 28, 2025 at 1:56 PM
What about actions?
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
What's the MDP state space? Atari frames?
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X

October 28, 2025 at 1:56 PM
What's the MDP state space? Atari frames?
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Let's take the ALE and try to be explicit about this mapping.
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X

October 28, 2025 at 1:56 PM
Let's take the ALE and try to be explicit about this mapping.
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Most RL papers include "This is an MDP..." formalisms, maybe prove a theorem or two, and then evaluate on some benchmark like the ALE.
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X


October 28, 2025 at 1:56 PM
Most RL papers include "This is an MDP..." formalisms, maybe prove a theorem or two, and then evaluate on some benchmark like the ALE.
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
This work was led by @johanobandoc.bsky.social and @waltermayor.bsky.social , with @lavoiems.bsky.social , Scott Fujimoto and Aaron Courville.
Read the paper at arxiv.org/abs/2510.13704
11/X
Read the paper at arxiv.org/abs/2510.13704
11/X
Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require la...
arxiv.org
October 20, 2025 at 2:07 PM
This work was led by @johanobandoc.bsky.social and @waltermayor.bsky.social , with @lavoiems.bsky.social , Scott Fujimoto and Aaron Courville.
Read the paper at arxiv.org/abs/2510.13704
11/X
Read the paper at arxiv.org/abs/2510.13704
11/X
The effectiveness of SEMs demonstrate that RL training w/ sparse & structured representations can yield good performance. We're excited to explore value-based, multi-objective, & scaled-up architectures.
Try integrating SEMs and let us know what you find!
10/X
Try integrating SEMs and let us know what you find!
10/X
October 20, 2025 at 2:07 PM
The effectiveness of SEMs demonstrate that RL training w/ sparse & structured representations can yield good performance. We're excited to explore value-based, multi-objective, & scaled-up architectures.
Try integrating SEMs and let us know what you find!
10/X
Try integrating SEMs and let us know what you find!
10/X
The gains don’t stop there!
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X

October 20, 2025 at 2:07 PM
The gains don’t stop there!
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
Is SEM only effective with TD3-style agents and/or on HumanoidBench?
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X

October 20, 2025 at 2:07 PM
Is SEM only effective with TD3-style agents and/or on HumanoidBench?
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X