




Pablo Samuel Castro
@pcastr.bsky.social
Señor swesearcher @ Google DeepMind, adjunct prof at Université de Montréal and Mila. Musician. From 🇪🇨 living in 🇨🇦.
https://psc-g.github.io/
https://psc-g.github.io/
What makes a good benchmark?
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X

October 28, 2025 at 1:56 PM
What makes a good benchmark?
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
I argue they should be:
🔵 well-understood
🔵 diverse & without experimenter-bias
🔵 naturally extendable
Under this lens, the ALE is still a useful benchmark for RL research, *when used properly* (i.e. to advance science, rather than "winning").
14/X
Aggregate results?
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X


October 28, 2025 at 1:56 PM
Aggregate results?
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
When reporting aggregate performance (like IQM), the choice of games subset can have a huge impact on algo comparisons (see figure below)!
We're missing the trees for the forest!🌳
🛑Stop focusing on aggregate results, & opt for per-game analyses!🛑
13/X
Train/Eval env sets?
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X

October 28, 2025 at 1:56 PM
Train/Eval env sets?
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
When ALE was introduced, Bellemare et al. recommended using 5 games for hparam tuning, & a separate set of games for eval.
This practice is no longer common, and people often use the same set of games for train/eval.
If possible, make them disjoint!
12/X
Experiment length?
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X


October 28, 2025 at 1:56 PM
Experiment length?
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
While 200M env frames was the standard set by Mnih et al, now there's a wide variety of lengths used (100k, 500k, 10M, 40M, etc.). In arxiv.org/abs/2406.17523 we showed exp length can have a huge impact on conclusions drawn (see first image).
11/X
Discount factor?
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X

October 28, 2025 at 1:56 PM
Discount factor?
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
ɣ is central to training RL agents, but on the ALE we report undiscounted returns:
👉🏾We're evaluating algo's using a different objective than what they were trained for!👈🏾
To avoid ambiguity, we should report {ɣ_train} and ɣ_eval.
10/X
Environment dynamics?
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X

October 28, 2025 at 1:56 PM
Environment dynamics?
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
Given that we're dealing with a POMDP, state transitions are between Atari RAM states, & observations are affected by all the software wrappers.
Design decisions like whether end-of-life means end-of-episode affects transition dynamics & performance!
8/X
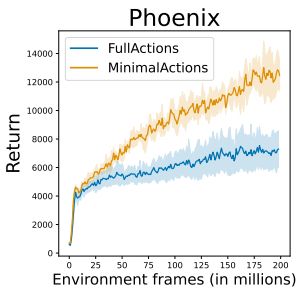
What about actions?
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
October 28, 2025 at 1:56 PM
What about actions?
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
In the ALE you can use a "minimal set" or the full set, & you see both being used in the literature.
This choice matters a ton, but you don't always see it stated explicitly!
5/X
What's the MDP state space? Atari frames?
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X

October 28, 2025 at 1:56 PM
What's the MDP state space? Atari frames?
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Nope, single Atari frames are not Markovian => for Markovian policies, design choices like frame skipping/stacking & max-pooling were taken.
*This means we're dealing with a POMDP!*
And these choices matter a ton (see image below)!
4/X
Let's take the ALE and try to be explicit about this mapping.
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X

October 28, 2025 at 1:56 PM
Let's take the ALE and try to be explicit about this mapping.
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Stella is the emulator of the Atari 2600, but we use the ALE as a wrapper around it, which comes with its own design decisions.
But typically we interact with something like Gymnasium/CleanRL on top of that.
3/X
Most RL papers include "This is an MDP..." formalisms, maybe prove a theorem or two, and then evaluate on some benchmark like the ALE.
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X


October 28, 2025 at 1:56 PM
Most RL papers include "This is an MDP..." formalisms, maybe prove a theorem or two, and then evaluate on some benchmark like the ALE.
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
However, we almost never *explicitly* map our MDP formalism to the envs we evaluate on! This creates a *formalism-implementation gap*!
2/X
🚨The Formalism-Implementation Gap in RL research🚨
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X

October 28, 2025 at 1:56 PM
🚨The Formalism-Implementation Gap in RL research🚨
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
The gains don’t stop there!
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X

October 20, 2025 at 2:07 PM
The gains don’t stop there!
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
We evaluated Flow Q-Learning in offline-to-online to online training as well as FastTD3 on multitask settings, and observe gains throughout.
9/X
Is SEM only effective with TD3-style agents and/or on HumanoidBench?
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X

October 20, 2025 at 2:07 PM
Is SEM only effective with TD3-style agents and/or on HumanoidBench?
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X
No!
We evaluate on FastTD3-SimBaV2 and FastSAC on HumanoidBench, FastTD3 on Booster T1, as well as PPO on Atari-10 and IsaacGym and observe gains in all these settings.
8/X
Are our results specific to the design choices behind FastTD3?
No!
We ablate FastTD3 components and vary some of the training configurations and find that the addition of SEM results in improvements under all these settings, suggesting its benefits are general.
7/X
No!
We ablate FastTD3 components and vary some of the training configurations and find that the addition of SEM results in improvements under all these settings, suggesting its benefits are general.
7/X

October 20, 2025 at 2:07 PM
Are our results specific to the design choices behind FastTD3?
No!
We ablate FastTD3 components and vary some of the training configurations and find that the addition of SEM results in improvements under all these settings, suggesting its benefits are general.
7/X
No!
We ablate FastTD3 components and vary some of the training configurations and find that the addition of SEM results in improvements under all these settings, suggesting its benefits are general.
7/X
We find SEM to be the most effective when compared against alternative approaches for structuring representations. We also evaluated the impact of the choices of V and L, finding that higher V with lower L seems to yield the best results.
6/X
6/X

October 20, 2025 at 2:07 PM
We find SEM to be the most effective when compared against alternative approaches for structuring representations. We also evaluated the impact of the choices of V and L, finding that higher V with lower L seems to yield the best results.
6/X
6/X
Why do SEMs improve performance?
Our analyses show they increase effective rank of actor features while bounding their norms, have reduced losses, more consistency across critics, & sparser representations, ultimately resulting in improved performance and sample efficiency.
5/X
Our analyses show they increase effective rank of actor features while bounding their norms, have reduced losses, more consistency across critics, & sparser representations, ultimately resulting in improved performance and sample efficiency.
5/X


October 20, 2025 at 2:07 PM
Why do SEMs improve performance?
Our analyses show they increase effective rank of actor features while bounding their norms, have reduced losses, more consistency across critics, & sparser representations, ultimately resulting in improved performance and sample efficiency.
5/X
Our analyses show they increase effective rank of actor features while bounding their norms, have reduced losses, more consistency across critics, & sparser representations, ultimately resulting in improved performance and sample efficiency.
5/X
We use FastTD3 (arxiv.org/abs/2505.22642), a recent baseline for continuous control which is performant and fast, to evaluate the benefits of SEM. As seen in the second figure, SEMs yield improvements throughout.
4/X
4/X


October 20, 2025 at 2:07 PM
We use FastTD3 (arxiv.org/abs/2505.22642), a recent baseline for continuous control which is performant and fast, to evaluate the benefits of SEM. As seen in the second figure, SEMs yield improvements throughout.
4/X
4/X
We first show that non-stationarity amplifies representation collapse by evaluating on a CIFAR-10 experiment where we create non-stationarity by randomly shuffling labels every 20 epochs. Using SEMs helps avoid collapse, reduces neuron dormancy, and results in lower loss.
3/X
3/X

October 20, 2025 at 2:07 PM
We first show that non-stationarity amplifies representation collapse by evaluating on a CIFAR-10 experiment where we create non-stationarity by randomly shuffling labels every 20 epochs. Using SEMs helps avoid collapse, reduces neuron dormancy, and results in lower loss.
3/X
3/X
We take the view that discrete & sparse representations are stabler, more robust to noise, and more interpretable. SEMs are differentiable modules which partition latent representations into L simplices of size V.
2/X
2/X
October 20, 2025 at 2:07 PM
We take the view that discrete & sparse representations are stabler, more robust to noise, and more interpretable. SEMs are differentiable modules which partition latent representations into L simplices of size V.
2/X
2/X
🔊Simplicial Embeddings (SEMs) Improve Sample Efficiency in Actor-Critic Agents🔊
In our recent preprint we demonstrate that the use of well-structured representations (SEMs) can dramatically improve sample efficiency in RL agents.
1/X
In our recent preprint we demonstrate that the use of well-structured representations (SEMs) can dramatically improve sample efficiency in RL agents.
1/X

October 20, 2025 at 2:07 PM
🔊Simplicial Embeddings (SEMs) Improve Sample Efficiency in Actor-Critic Agents🔊
In our recent preprint we demonstrate that the use of well-structured representations (SEMs) can dramatically improve sample efficiency in RL agents.
1/X
In our recent preprint we demonstrate that the use of well-structured representations (SEMs) can dramatically improve sample efficiency in RL agents.
1/X
Caught my 11yo reading this, I'm so proud.

September 11, 2025 at 1:45 AM
Caught my 11yo reading this, I'm so proud.
Software engineering isn't dead, it just smells funny.

August 25, 2025 at 12:55 AM
Software engineering isn't dead, it just smells funny.
It was too hard to pick only four pictures, so here are a few more:




August 11, 2025 at 2:05 PM
It was too hard to pick only four pictures, so here are a few more:
Yesterday I did a 28.4k trail run and 1300m climb with some good friends (& colleagues). It was absolutely incredible! This was my first trail run, but now I think I'm hooked!
#trailrunpostconference
#trailrunpostconference




August 11, 2025 at 2:05 PM
Yesterday I did a 28.4k trail run and 1300m climb with some good friends (& colleagues). It was absolutely incredible! This was my first trail run, but now I think I'm hooked!
#trailrunpostconference
#trailrunpostconference
Once again, I leave @rl-conference.bsky.social convinced that it's the best conference out there for RL researchers, such a great week!
It was also so great getting the opportunity to see so many of my students shine while presenting and discussing their research!
It was also so great getting the opportunity to see so many of my students shine while presenting and discussing their research!




August 9, 2025 at 1:23 PM
Once again, I leave @rl-conference.bsky.social convinced that it's the best conference out there for RL researchers, such a great week!
It was also so great getting the opportunity to see so many of my students shine while presenting and discussing their research!
It was also so great getting the opportunity to see so many of my students shine while presenting and discussing their research!