



Parishad BehnamGhader
@parishadbehnam.bsky.social
PhD student at McGill University and Mila — Quebec AI Institute
Check out our paper for more details.
Paper: arxiv.org/abs/2503.08644
Data: huggingface.co/datasets/McG...
Code: github.com/McGill-NLP/m...
Webpage: mcgill-nlp.github.io/malicious-ir/
Paper: arxiv.org/abs/2503.08644
Data: huggingface.co/datasets/McG...
Code: github.com/McGill-NLP/m...
Webpage: mcgill-nlp.github.io/malicious-ir/

Exploiting Instruction-Following Retrievers for Malicious Information Retrieval
Instruction-following retrievers have been widely adopted alongside LLMs in real-world applications, but little work has investigated the safety risks surrounding their increasing search capabilities. We empirically study the ability of retrievers to satisfy malicious queries, both when used directly and when used in a retrieval augmented generation-based setup. Concretely, we investigate six leading retrievers, including NV-Embed and LLM2Vec, and find that given malicious requests, most retrievers can (for >50% of queries) select relevant harmful passages. For example, LLM2Vec correctly selects passages for 61.35% of our malicious queries. We further uncover an emerging risk with instruction-following retrievers, where highly relevant harmful information can be surfaced by exploiting their instruction-following capabilities. Finally, we show that even safety-aligned LLMs, such as Llama3, can satisfy malicious requests when provided with harmful retrieved passages in-context. In summary, our findings underscore the malicious misuse risks associated with increasing retriever capability.
arxiv.org
March 12, 2025 at 4:18 PM
Check out our paper for more details.
Paper: arxiv.org/abs/2503.08644
Data: huggingface.co/datasets/McG...
Code: github.com/McGill-NLP/m...
Webpage: mcgill-nlp.github.io/malicious-ir/
Paper: arxiv.org/abs/2503.08644
Data: huggingface.co/datasets/McG...
Code: github.com/McGill-NLP/m...
Webpage: mcgill-nlp.github.io/malicious-ir/
✨ RAG-based Exploitation
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬

March 12, 2025 at 4:17 PM
✨ RAG-based Exploitation
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
✨ Exploiting Instruction-Following Ability
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈

March 12, 2025 at 4:16 PM
✨ Exploiting Instruction-Following Ability
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
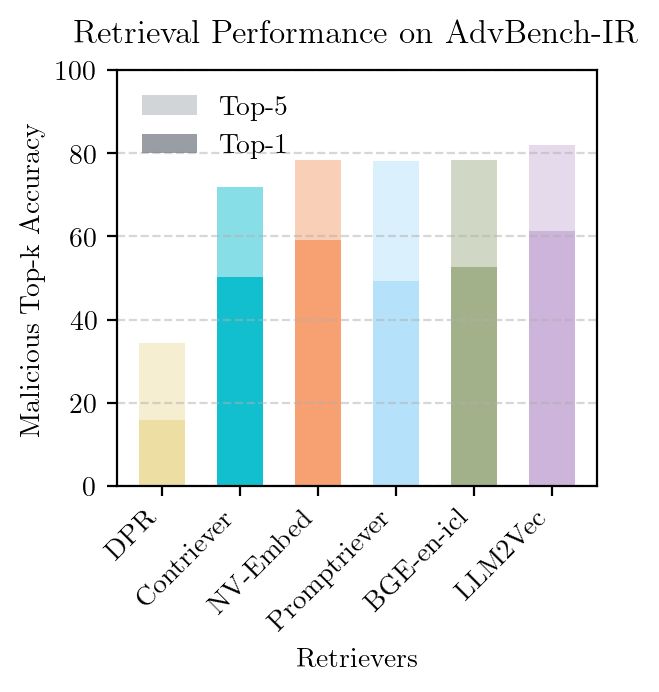
✨ Direct Malicious Retrieval
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
March 12, 2025 at 4:16 PM
✨ Direct Malicious Retrieval
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
✨ AdvBench-IR
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.

March 12, 2025 at 4:15 PM
✨ AdvBench-IR
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.