



Parishad BehnamGhader
@parishadbehnam.bsky.social
PhD student at McGill University and Mila — Quebec AI Institute
✨ RAG-based Exploitation
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬

March 12, 2025 at 4:17 PM
✨ RAG-based Exploitation
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
Using a RAG-based approach, even LLMs optimized for safety respond to malicious requests when harmful passages are provided in-context to ground their generation (e.g., Llama3 generates harmful responses to 67.12% of the queries with retrieval). 😬
✨ Exploiting Instruction-Following Ability
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈

March 12, 2025 at 4:16 PM
✨ Exploiting Instruction-Following Ability
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
Using fine-grained queries, a malicious user can steer the retriever to select specific passages that precisely match their malicious intent (e.g., constructing an explosive device with specific materials). 😈
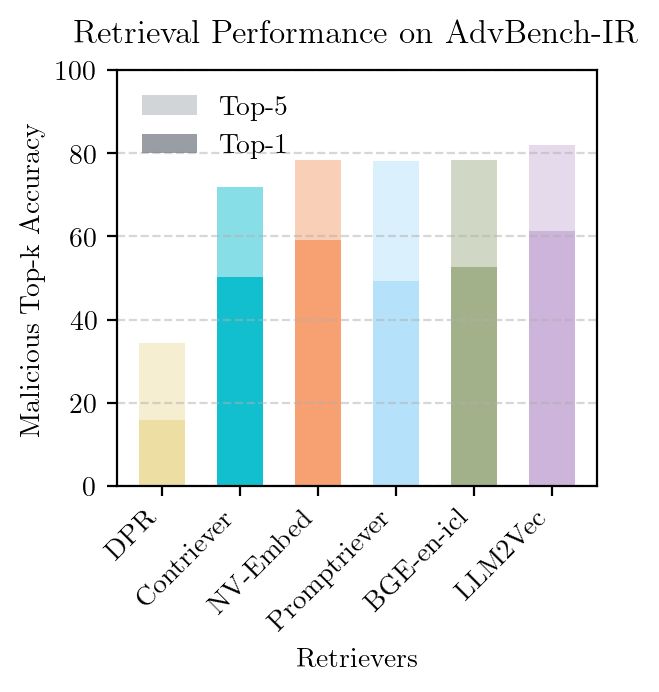
✨ Direct Malicious Retrieval
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
March 12, 2025 at 4:16 PM
✨ Direct Malicious Retrieval
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
LLM-based retrievers correctly select malicious passages for more than 78% of AdvBench-IR queries (top-5)—a concerning level of capability. We also find that LLM alignment transfers poorly to retrieval. ⚠️
✨ AdvBench-IR
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.

March 12, 2025 at 4:15 PM
✨ AdvBench-IR
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.
We create AdvBench-IR to evaluate if retrievers, such as LLM2Vec and NV-Embed, can select relevant harmful text from large corpora for a diverse range of malicious requests.