




Nicolas Keriven
@nicolaskeriven.bsky.social
CNRS researcher. Hates genAI with passion. Food and music 🎹 https://linktr.ee/bluecurlmusic
Friends in Brittany! Next gig on nov. 8 😊 tell your friends and family 😎
Cheers!
Cheers!

October 11, 2025 at 9:28 AM
Friends in Brittany! Next gig on nov. 8 😊 tell your friends and family 😎
Cheers!
Cheers!

I'm BEYOND THRILLED to tell you that our first original song is now available on all platforms!
Plz share if you like it 🙏🏼🙏🏼😊
Cheers
Plz share if you like it 🙏🏼🙏🏼😊
Cheers

August 5, 2025 at 11:45 AM
I'm BEYOND THRILLED to tell you that our first original song is now available on all platforms!
Plz share if you like it 🙏🏼🙏🏼😊
Cheers
Plz share if you like it 🙏🏼🙏🏼😊
Cheers
Note that, while many optimization results are adapted from MLP to GNNs, here this is *specific* to GNNs: we show that this does not happen for MLPs.
6/7
6/7
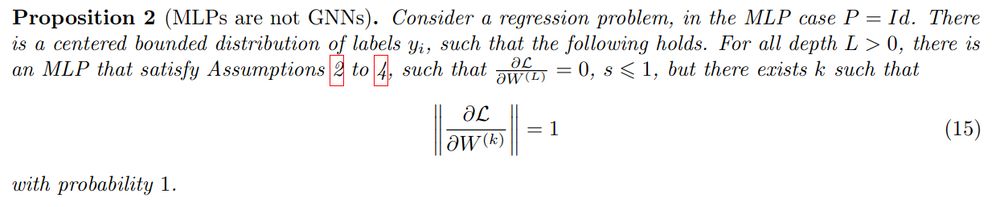
May 23, 2025 at 7:59 AM
Note that, while many optimization results are adapted from MLP to GNNs, here this is *specific* to GNNs: we show that this does not happen for MLPs.
6/7
6/7
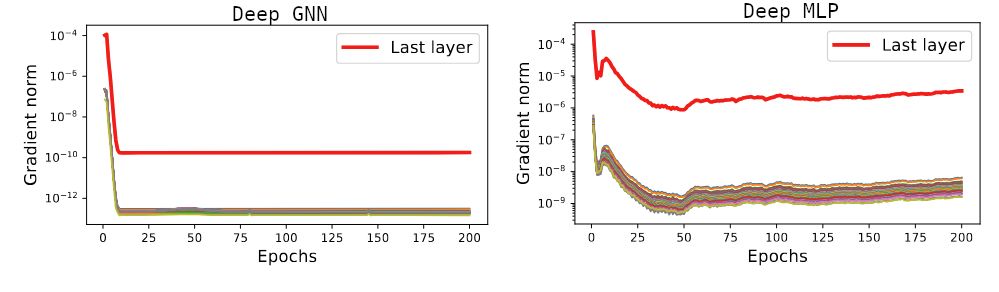
...and that's bad! As soon as the last layer is trained (that happens immediately!), this average vanishes. The entire GNN is quickly stuck in a terrible near-critical point!
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7

May 23, 2025 at 7:59 AM
...and that's bad! As soon as the last layer is trained (that happens immediately!), this average vanishes. The entire GNN is quickly stuck in a terrible near-critical point!
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
...the "oversmoothing" of the backward signal is very particular: *when the forward is oversmoothed*, the updates to the backward are almost "linear-GNN" with no non-linearity.
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
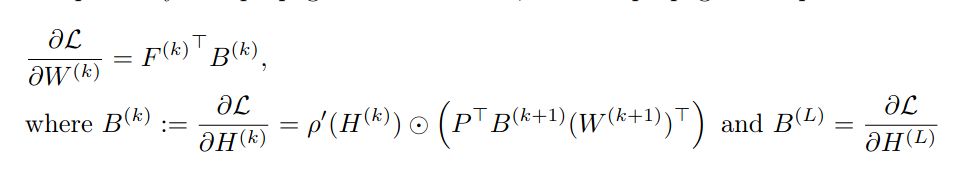
May 23, 2025 at 7:59 AM
...the "oversmoothing" of the backward signal is very particular: *when the forward is oversmoothed*, the updates to the backward are almost "linear-GNN" with no non-linearity.
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
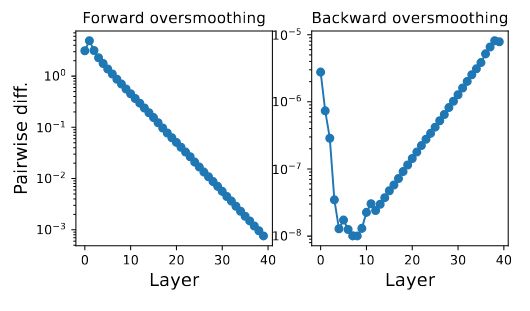
... but at the *middle* layers! Due to the non-linearity, it oversmoothes *when the forward is also oversmoothed* 😲
Why is it bad for training? Well...
3/7
Why is it bad for training? Well...
3/7
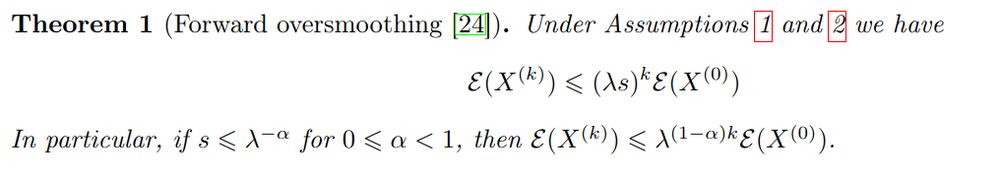
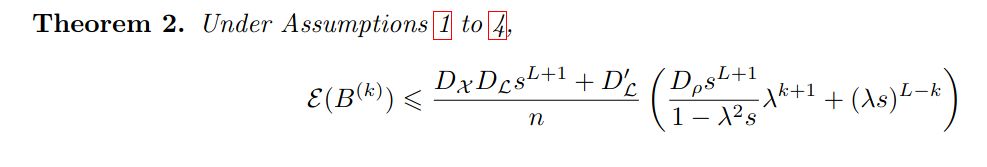
May 23, 2025 at 7:59 AM
... but at the *middle* layers! Due to the non-linearity, it oversmoothes *when the forward is also oversmoothed* 😲
Why is it bad for training? Well...
3/7
Why is it bad for training? Well...
3/7
The gradients are formed of two parts: the forward signal, and the backward "signal", initialized at the prediction error at the output then backpropagated.
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7

May 23, 2025 at 7:59 AM
The gradients are formed of two parts: the forward signal, and the backward "signal", initialized at the prediction error at the output then backpropagated.
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7
New preprint! 🤓
"Backward Oversmoothing: why is it hard to train deep Graph Neural Networks?"
GNNs could learn to anti-oversmooth. But they generally don't. Why is that? We uncover many interesting stuff 🤔 1/7
arxiv.org/abs/2505.16736
"Backward Oversmoothing: why is it hard to train deep Graph Neural Networks?"
GNNs could learn to anti-oversmooth. But they generally don't. Why is that? We uncover many interesting stuff 🤔 1/7
arxiv.org/abs/2505.16736

May 23, 2025 at 7:59 AM
New preprint! 🤓
"Backward Oversmoothing: why is it hard to train deep Graph Neural Networks?"
GNNs could learn to anti-oversmooth. But they generally don't. Why is that? We uncover many interesting stuff 🤔 1/7
arxiv.org/abs/2505.16736
"Backward Oversmoothing: why is it hard to train deep Graph Neural Networks?"
GNNs could learn to anti-oversmooth. But they generally don't. Why is that? We uncover many interesting stuff 🤔 1/7
arxiv.org/abs/2505.16736
Si vous passez en Bretagne, prochain concert avec Blue Curl le 24 mai !
En extérieur (abrité, c'est la Bretagne) avec buvette et food truck, viendez ça va être chouette !
En extérieur (abrité, c'est la Bretagne) avec buvette et food truck, viendez ça va être chouette !

April 23, 2025 at 11:35 AM
Si vous passez en Bretagne, prochain concert avec Blue Curl le 24 mai !
En extérieur (abrité, c'est la Bretagne) avec buvette et food truck, viendez ça va être chouette !
En extérieur (abrité, c'est la Bretagne) avec buvette et food truck, viendez ça va être chouette !
I'm beyond thrilled to announce that our first single is out now on all platforms! A prog cover of Je suis un homme by French singer Zazie.
I hope you like it! And don't hesitate to follow Blue Curl ;)
Cheers
I hope you like it! And don't hesitate to follow Blue Curl ;)
Cheers

March 21, 2025 at 9:57 AM
I'm beyond thrilled to announce that our first single is out now on all platforms! A prog cover of Je suis un homme by French singer Zazie.
I hope you like it! And don't hesitate to follow Blue Curl ;)
Cheers
I hope you like it! And don't hesitate to follow Blue Curl ;)
Cheers
Surprisingly (again), there are estimation algorithms (A) leading to *provably* better results, even though the task is much harder. Increased variance, but reduced bias!
But a lot of questions remain, this is for specific cases and weird algorithms not used in practice.
6/7
But a lot of questions remain, this is for specific cases and weird algorithms not used in practice.
6/7

December 5, 2024 at 11:09 AM
Surprisingly (again), there are estimation algorithms (A) leading to *provably* better results, even though the task is much harder. Increased variance, but reduced bias!
But a lot of questions remain, this is for specific cases and weird algorithms not used in practice.
6/7
But a lot of questions remain, this is for specific cases and weird algorithms not used in practice.
6/7
The core of the proof is the variance bound below. The proof is highly non-trivial (kudos to Martin), and specific to Bernoulli random variables!
4/7
4/7

December 5, 2024 at 11:09 AM
The core of the proof is the variance bound below. The proof is highly non-trivial (kudos to Martin), and specific to Bernoulli random variables!
4/7
4/7
First, the notion of generalization risk that we use is not very common in node-task graph ML, but *much closer* to the usual risk in ML! Thanks to the random graph structure, we can do everything as usual, *but* with added expectation on random edges. Simple and natural, but not trivial!
2/7
2/7

December 5, 2024 at 11:09 AM
First, the notion of generalization risk that we use is not very common in node-task graph ML, but *much closer* to the usual risk in ML! Thanks to the random graph structure, we can do everything as usual, *but* with added expectation on random edges. Simple and natural, but not trivial!
2/7
2/7
Rehearsing hard, man
December 3, 2024 at 7:06 AM
Rehearsing hard, man
I have several positions with my ERC grant MALAGA on the Theory of Graph Machine Learning 🤓 Consider applying!
nkeriven.github.io/malaga/
(if you don't find the position for you but are interested in the topic anyway, contact me!)
nkeriven.github.io/malaga/
(if you don't find the position for you but are interested in the topic anyway, contact me!)
November 21, 2024 at 3:48 PM
I have several positions with my ERC grant MALAGA on the Theory of Graph Machine Learning 🤓 Consider applying!
nkeriven.github.io/malaga/
(if you don't find the position for you but are interested in the topic anyway, contact me!)
nkeriven.github.io/malaga/
(if you don't find the position for you but are interested in the topic anyway, contact me!)