




neurosock
@neurosock.bsky.social
#BrainChips monthly recap. I make #neuro papers easy to understand. To make #Neuralink possible. Neuro PhD. AI🤖ML👾Data Sci 📊 Monkeys🐵Future🚀Cyberpunk⚡🦾🌌
Overactive D2 receptors caused the thalamic circuit to fail, mimicking schizophrenic symptoms (Fig 7).
Restoring activity in the mediodorsal thalamus rescued the behavior, validating the circuit mechanism.
Restoring activity in the mediodorsal thalamus rescued the behavior, validating the circuit mechanism.

November 13, 2025 at 11:58 AM
Overactive D2 receptors caused the thalamic circuit to fail, mimicking schizophrenic symptoms (Fig 7).
Restoring activity in the mediodorsal thalamus rescued the behavior, validating the circuit mechanism.
Restoring activity in the mediodorsal thalamus rescued the behavior, validating the circuit mechanism.
They found that inhibitory interneurons gate learning based on the thalamus's confidence level (Fig 4).
Uncertainty suppresses plasticity to prevent errors, while certainty releases the brakes to encode new rules.
Uncertainty suppresses plasticity to prevent errors, while certainty releases the brakes to encode new rules.

November 13, 2025 at 11:58 AM
They found that inhibitory interneurons gate learning based on the thalamus's confidence level (Fig 4).
Uncertainty suppresses plasticity to prevent errors, while certainty releases the brakes to encode new rules.
Uncertainty suppresses plasticity to prevent errors, while certainty releases the brakes to encode new rules.
The biological model consistently outperformed standard "ideal" algorithms like Thompson Sampling (Fig 3a-c).
Biological heuristics like dynamic sparsity modulation allowed for faster adaptation than rigid mathematical formulas.
Biological heuristics like dynamic sparsity modulation allowed for faster adaptation than rigid mathematical formulas.

November 13, 2025 at 11:58 AM
The biological model consistently outperformed standard "ideal" algorithms like Thompson Sampling (Fig 3a-c).
Biological heuristics like dynamic sparsity modulation allowed for faster adaptation than rigid mathematical formulas.
Biological heuristics like dynamic sparsity modulation allowed for faster adaptation than rigid mathematical formulas.
They demonstrated that the PFC-MD circuit learns a generative model to infer hidden contexts (Fig 4c).
This circuit maintained a low-dimensional representation of likelihood that tracked the changing environment.
This circuit maintained a low-dimensional representation of likelihood that tracked the changing environment.

November 13, 2025 at 11:58 AM
They demonstrated that the PFC-MD circuit learns a generative model to infer hidden contexts (Fig 4c).
This circuit maintained a low-dimensional representation of likelihood that tracked the changing environment.
This circuit maintained a low-dimensional representation of likelihood that tracked the changing environment.
This is how we learned that from their results:
They showed the basal ganglia encodes uncertainty as a probability distribution used for exploration (Fig 2f).
Synapses representing different value quantiles allowed the model to balance risk and reward efficiently.
They showed the basal ganglia encodes uncertainty as a probability distribution used for exploration (Fig 2f).
Synapses representing different value quantiles allowed the model to balance risk and reward efficiently.

November 13, 2025 at 11:58 AM
This is how we learned that from their results:
They showed the basal ganglia encodes uncertainty as a probability distribution used for exploration (Fig 2f).
Synapses representing different value quantiles allowed the model to balance risk and reward efficiently.
They showed the basal ganglia encodes uncertainty as a probability distribution used for exploration (Fig 2f).
Synapses representing different value quantiles allowed the model to balance risk and reward efficiently.
Here's what could be happening in schizophrenia:
Hyperactive D2 receptors in BG unbalance activity in Thalamus, making the "Belief keeper" unstable.
This results in a unstable attractor, sensitive to noise and that cannot hold onto evidence.
Hyperactive D2 receptors in BG unbalance activity in Thalamus, making the "Belief keeper" unstable.
This results in a unstable attractor, sensitive to noise and that cannot hold onto evidence.

November 13, 2025 at 11:58 AM
Here's what could be happening in schizophrenia:
Hyperactive D2 receptors in BG unbalance activity in Thalamus, making the "Belief keeper" unstable.
This results in a unstable attractor, sensitive to noise and that cannot hold onto evidence.
Hyperactive D2 receptors in BG unbalance activity in Thalamus, making the "Belief keeper" unstable.
This results in a unstable attractor, sensitive to noise and that cannot hold onto evidence.
The Detective acts as a master switch, engaging the specific Gambler circuit that matches the current context.
This hierarchy allows the mouse to instantly swap strategies without unlearning everything when the world changes.
E.g. PFC has evidence of a wrong choice.
This hierarchy allows the mouse to instantly swap strategies without unlearning everything when the world changes.
E.g. PFC has evidence of a wrong choice.

November 13, 2025 at 11:58 AM
The Detective acts as a master switch, engaging the specific Gambler circuit that matches the current context.
This hierarchy allows the mouse to instantly swap strategies without unlearning everything when the world changes.
E.g. PFC has evidence of a wrong choice.
This hierarchy allows the mouse to instantly swap strategies without unlearning everything when the world changes.
E.g. PFC has evidence of a wrong choice.
A "Detective" circuit in the PFC tracks clues to infer the current context or "hidden state".
PFC helped by the mediodorsal (MD) thalamus "belief keeper" who uses attractor dynamics to hold a stable belief until enough evidence pushes it to a new conclusion.
PFC helped by the mediodorsal (MD) thalamus "belief keeper" who uses attractor dynamics to hold a stable belief until enough evidence pushes it to a new conclusion.

November 13, 2025 at 11:58 AM
A "Detective" circuit in the PFC tracks clues to infer the current context or "hidden state".
PFC helped by the mediodorsal (MD) thalamus "belief keeper" who uses attractor dynamics to hold a stable belief until enough evidence pushes it to a new conclusion.
PFC helped by the mediodorsal (MD) thalamus "belief keeper" who uses attractor dynamics to hold a stable belief until enough evidence pushes it to a new conclusion.
A "Gambler" circuit is formed by:
The basal ganglia "notebook": stores payout probabilities as full distributions, not just averages.
Premotor cortex: samples from these notes to explore options when the outcome is uncertain.
Motor cortex: compares values and takes action.
The basal ganglia "notebook": stores payout probabilities as full distributions, not just averages.
Premotor cortex: samples from these notes to explore options when the outcome is uncertain.
Motor cortex: compares values and takes action.

November 13, 2025 at 11:58 AM
A "Gambler" circuit is formed by:
The basal ganglia "notebook": stores payout probabilities as full distributions, not just averages.
Premotor cortex: samples from these notes to explore options when the outcome is uncertain.
Motor cortex: compares values and takes action.
The basal ganglia "notebook": stores payout probabilities as full distributions, not just averages.
Premotor cortex: samples from these notes to explore options when the outcome is uncertain.
Motor cortex: compares values and takes action.
The mouse faces two puzzles:
which arm pays out right now?, and
have the hidden rules changed?
which arm pays out right now?, and
have the hidden rules changed?

November 13, 2025 at 11:58 AM
The mouse faces two puzzles:
which arm pays out right now?, and
have the hidden rules changed?
which arm pays out right now?, and
have the hidden rules changed?
Decisions under uncertainty are a coordinated action of PFC, pre/motor, BG, and thalamus.
This model tries to explain decision impairments by hyperactive D2 receptors
We can clarify the paper by building a mouse with schizophrenia.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
This model tries to explain decision impairments by hyperactive D2 receptors
We can clarify the paper by building a mouse with schizophrenia.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI

November 13, 2025 at 11:58 AM
Decisions under uncertainty are a coordinated action of PFC, pre/motor, BG, and thalamus.
This model tries to explain decision impairments by hyperactive D2 receptors
We can clarify the paper by building a mouse with schizophrenia.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
This model tries to explain decision impairments by hyperactive D2 receptors
We can clarify the paper by building a mouse with schizophrenia.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
DA is an adaptive signal that switches its function in real-time.
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).

October 30, 2025 at 11:36 AM
DA is an adaptive signal that switches its function in real-time.
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Upon reward delivery, it stops predicting force and starts predicting the *rate of licking* (Fig 9h, 9j).
Optogenetically stimulating DA neurons in place of reward was *not sufficient* for learning.
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).

October 30, 2025 at 11:36 AM
Optogenetically stimulating DA neurons in place of reward was *not sufficient* for learning.
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Inhibiting DA neurons during the task *did not impair* learning (Fig 10b, 10i).
Changes in DA firing due to reward magnitude, probability, and omission were all explained by parallel changes in the *force* the mice exerted (Figs 4, 5).

October 30, 2025 at 11:36 AM
Changes in DA firing due to reward magnitude, probability, and omission were all explained by parallel changes in the *force* the mice exerted (Figs 4, 5).
This force-tuning was independent of reward, appearing during spontaneous movements.
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).

October 30, 2025 at 11:36 AM
This force-tuning was independent of reward, appearing during spontaneous movements.
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
It even held true during an aversive air puff, proving it's not about "reward" (Fig 3e, 3h).
This is how we learned that from their results:
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).

October 30, 2025 at 11:36 AM
This is how we learned that from their results:
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
They identified two distinct DA neuron types: "Forward" and "Backward" populations.
These cells fire to drive movement in a specific direction (Fig 1e, 1h, 1k).
How does reward probability change the DA signal?
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.

October 30, 2025 at 11:36 AM
How does reward probability change the DA signal?
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
RPE view: DA activity scales with reward probability, encoding the *strength* of the prediction.
New view: Probability changes the animal's *effort*, and the DA signal simply tracks that performance.
Why does a bigger reward cause a bigger DA spike?
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.

October 30, 2025 at 11:36 AM
Why does a bigger reward cause a bigger DA spike?
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
RPE view: A larger reward causes a larger DA spike because it's a bigger "positive error."
New view: A larger reward makes the mouse push *harder*, and the DA spike just tracks that *vigor*.
Why does DA firing "dip" when a reward is omitted?
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.

October 30, 2025 at 11:36 AM
Why does DA firing "dip" when a reward is omitted?
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
RPE view: The famous "dip" in DA when a reward is omitted is a negative prediction error.
New view: The dip simply reflects the animal *abruptly stopping* its forward movement.
In RPE, the DA signal shifts from reward to cue 🔔 over time.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.

October 30, 2025 at 11:36 AM
In RPE, the DA signal shifts from reward to cue 🔔 over time.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Why does the DA signal "move" to the cue?
RPE view: This helps an animal learn what things are important.
New view: the signal shifts because the animal's *action* (pushing forward) shifts to the cue.
Let's unpack this:
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.

October 30, 2025 at 11:36 AM
Let's unpack this:
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
The classical RPE model says DA neurons encode the *difference* between expected and actual rewards.
A surprise spikes DA activity, while disappointment causes a dip.
This helps a mouse 🐭 learn what to pay attention to.
Dopamine ≠ reward but turns out, also not the learning molecule we thought.
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI

October 30, 2025 at 11:36 AM
Dopamine ≠ reward but turns out, also not the learning molecule we thought.
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
If DA RPE is the emperor, this work SCREAMS it was running naked all the time.
This paper got quite some attention recently. Let's simplify it a bit.
A🧵with my toy model and notes:
#neuroskyence #compneuro #NeuroAI
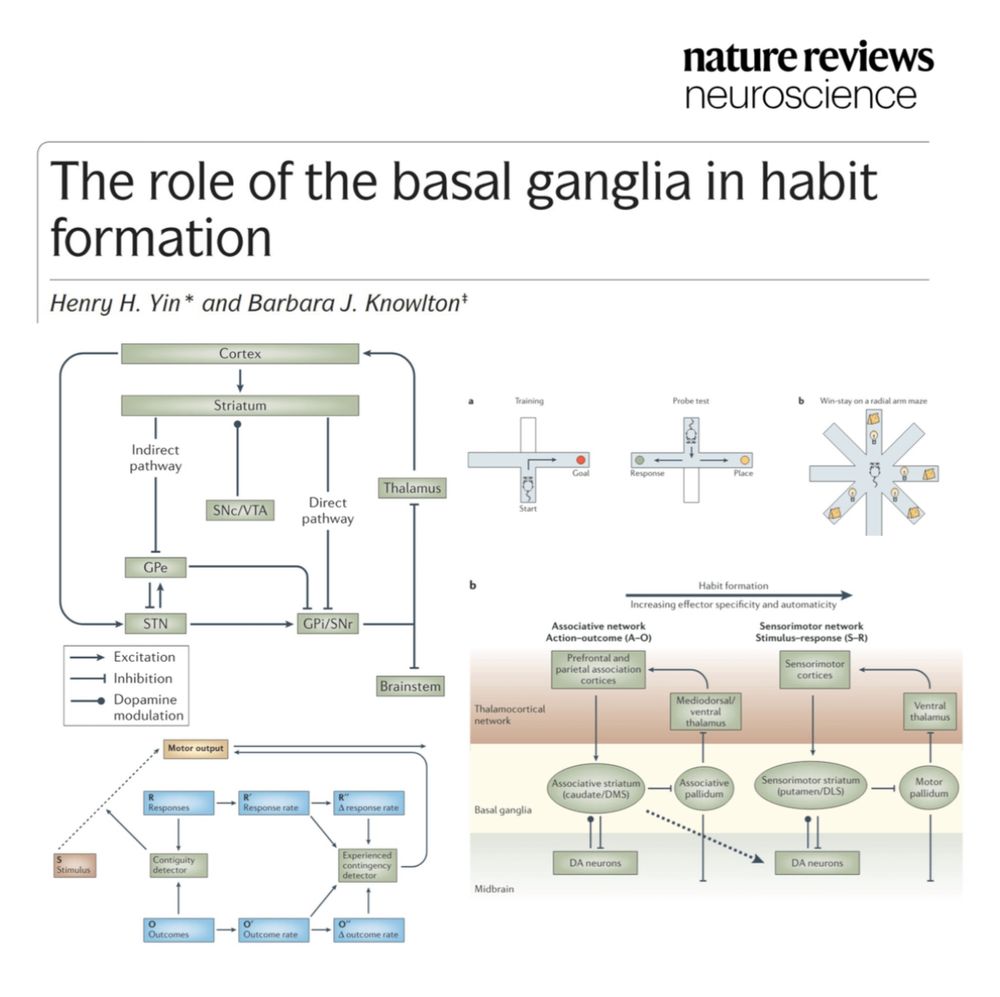
New habits move from the Prefrontal Cortex (conscious effort) to the Basal Ganglia (habit loop). A trick is to automate the first 30 seconds of a habit, minimizing the PFC's required 'energy' for initiation until the Basal Ganglia takes over. #LifeHacks #SelfImprovement #Brain
October 25, 2025 at 3:32 PM
New habits move from the Prefrontal Cortex (conscious effort) to the Basal Ganglia (habit loop). A trick is to automate the first 30 seconds of a habit, minimizing the PFC's required 'energy' for initiation until the Basal Ganglia takes over. #LifeHacks #SelfImprovement #Brain
This work unifies planning with sequence working memory.
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).

October 22, 2025 at 9:16 PM
This work unifies planning with sequence working memory.
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
The same neural architecture used to *remember* a sequence can be used to *infer* a plan (Fig 2B).
For new mazes, the RNNs adapted by learning *transitions* instead of fixed locations (Fig 6C).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).

October 22, 2025 at 9:16 PM
For new mazes, the RNNs adapted by learning *transitions* instead of fixed locations (Fig 6C).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).
Sensory input about a wall specifically inhibited the neural representation for that impossible transition (Fig 6H).