



Mert Özer
@mert-o.bsky.social
Reposted by Mert Özer

Credits to Takuma Nishimura and Martin Oeggerli (Micronaut) | Find more on: www.micronaut.ch
Micronaut: The fine art of microscopy by science photographer Martin Oeggerli | The fine art of microscopy by science photographer Martin Oeggerli
www.micronaut.ch
November 29, 2024 at 2:46 PM
Credits to Takuma Nishimura and Martin Oeggerli (Micronaut) | Find more on: www.micronaut.ch
Reposted by Mert Özer

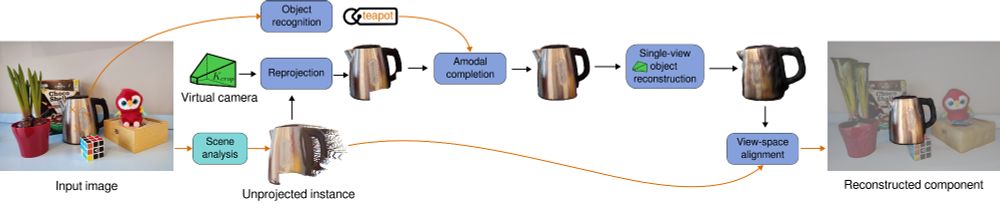
We handle occlusions by employing amodal completion for each instance. The completed instance is then reconstructed using existing models that perform well for single objects. However, we first address the object crop domain shift (e.g., focal length) through reprojection. (4/5)
November 19, 2024 at 9:52 PM
We handle occlusions by employing amodal completion for each instance. The completed instance is then reconstructed using existing models that perform well for single objects. However, we first address the object crop domain shift (e.g., focal length) through reprojection. (4/5)
Reposted by Mert Özer
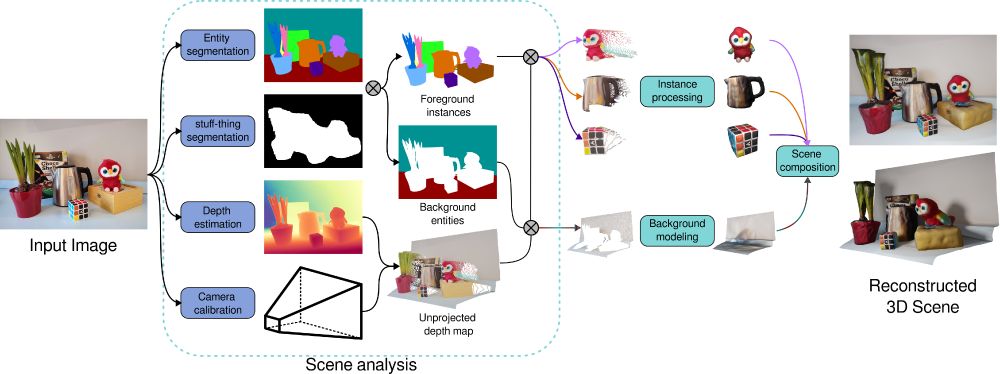
First, we parse the image of the scene by identifying the composing entities and estimating the depth and camera parameters. Each instance is then processed individually. The unprojected depth serves as a layout reference for composing the scene in 3D space. (3/5)
November 19, 2024 at 9:52 PM
First, we parse the image of the scene by identifying the composing entities and estimating the depth and camera parameters. Each instance is then processed individually. The unprojected depth serves as a layout reference for composing the scene in 3D space. (3/5)
Reposted by Mert Özer
Most single-image scene-level reconstruction methods require 3D supervised end-to-end training and suffer from poor generalization capabilities. We propose a modular approach where each component performs well by focusing on specific tasks that are easier to supervise. (2/5)
November 19, 2024 at 9:52 PM
Most single-image scene-level reconstruction methods require 3D supervised end-to-end training and suffer from poor generalization capabilities. We propose a modular approach where each component performs well by focusing on specific tasks that are easier to supervise. (2/5)
Reposted by Mert Özer

(3/3) As for colorization, we use color images manually colorized by artist Martin Oeggerli, we project colors onto 3D space with estimated depths and take the colors to create supervision, and also use feature loss employed by Ref-NPR to estimate invisible areas of input colors.
November 13, 2024 at 10:35 PM
(3/3) As for colorization, we use color images manually colorized by artist Martin Oeggerli, we project colors onto 3D space with estimated depths and take the colors to create supervision, and also use feature loss employed by Ref-NPR to estimate invisible areas of input colors.
Reposted by Mert Özer
(2/3) Our work utilizes Scanning Electron Microscopy (SEM) images of pollen. Two stages: grayscale novel view synthesis and colorization. The grayscale scene is represented by 2DGS, where poses are estimated using perspective projection with exceptionally long focal lengths.
November 13, 2024 at 10:35 PM
(2/3) Our work utilizes Scanning Electron Microscopy (SEM) images of pollen. Two stages: grayscale novel view synthesis and colorization. The grayscale scene is represented by 2DGS, where poses are estimated using perspective projection with exceptionally long focal lengths.
Kudos to @mert-o.bsky.social, Maximilian Weiherer,
@mhundhausen.bsky.social , @visionbernie.bsky.social!
7/7
@mhundhausen.bsky.social , @visionbernie.bsky.social!
7/7
November 12, 2024 at 8:04 PM
Kudos to @mert-o.bsky.social, Maximilian Weiherer,
@mhundhausen.bsky.social , @visionbernie.bsky.social!
7/7
@mhundhausen.bsky.social , @visionbernie.bsky.social!
7/7
The idea to perform this research originated from X, where we saw that one of our colleagues had a thermal camera and we started to capture images of an initial dataset.
x.com/M_Hundhausen...
6/7
x.com/M_Hundhausen...
6/7
November 12, 2024 at 8:02 PM
The idea to perform this research originated from X, where we saw that one of our colleagues had a thermal camera and we started to capture images of an initial dataset.
x.com/M_Hundhausen...
6/7
x.com/M_Hundhausen...
6/7
Since there is a lack of publicly available datasets containing multi-view, near-perfectly aligned RGB and thermal images, we share our collected dataset, called ThermalMix, here: zenodo.org/records/1106...
ThermalMix includes six common objects and a total of about 360 images.
5/7
ThermalMix includes six common objects and a total of about 360 images.
5/7

November 12, 2024 at 8:02 PM
Since there is a lack of publicly available datasets containing multi-view, near-perfectly aligned RGB and thermal images, we share our collected dataset, called ThermalMix, here: zenodo.org/records/1106...
ThermalMix includes six common objects and a total of about 360 images.
5/7
ThermalMix includes six common objects and a total of about 360 images.
5/7
A core challenge in building multi-sensory NeRFs is cross-modality calibration. We apply offline camera calibration prior to data capturing, leading to near-perfect alignments between images from different sensors. For thermal images, we chose a perforated aluminum plate.
4/7
4/7

November 12, 2024 at 8:02 PM
A core challenge in building multi-sensory NeRFs is cross-modality calibration. We apply offline camera calibration prior to data capturing, leading to near-perfect alignments between images from different sensors. For thermal images, we chose a perforated aluminum plate.
4/7
4/7
(3) Adding a second branch to the color network to predict RGB-X values. (4) Adding an extra *network* to predict thermal/IR/depth values. For the latter, we restrict back-prop through the density network, preventing geometry from being influenced by the second modality.
3/7
3/7
November 12, 2024 at 8:02 PM
(3) Adding a second branch to the color network to predict RGB-X values. (4) Adding an extra *network* to predict thermal/IR/depth values. For the latter, we restrict back-prop through the density network, preventing geometry from being influenced by the second modality.
3/7
3/7
We systematically compare four different strategies to learn multi-modal NeRFs from RGB + thermal, RGB + IR, and RGB + depth data: (1) Train from scratch on both modalities, leveraging camera poses computed from RGB images. (2) Pre-train on RGB, fine-tune on second modality.
2/7
2/7

November 12, 2024 at 8:02 PM
We systematically compare four different strategies to learn multi-modal NeRFs from RGB + thermal, RGB + IR, and RGB + depth data: (1) Train from scratch on both modalities, leveraging camera poses computed from RGB images. (2) Pre-train on RGB, fine-tune on second modality.
2/7
2/7