



Mattan S. Ben-Shachar
@mattansb.msbstats.info
Statistics lecturer | Freelance statistical consultant & research analyst | #rstats dev @easystats.github.io
home.msbstats.info
(He/Him)
home.msbstats.info
(He/Him)
How often have you seen BFs used to compare non-nested models in the wild? 😒
November 19, 2025 at 10:21 PM
How often have you seen BFs used to compare non-nested models in the wild? 😒
It's very good - I show it in my first ML lesson, just to give students a hint that big data and fancy algorithms aren't a reason to turn off our brains 🧠
November 19, 2025 at 5:03 PM
It's very good - I show it in my first ML lesson, just to give students a hint that big data and fancy algorithms aren't a reason to turn off our brains 🧠
MORE DATA + MORA ALGORITHM = MORE MONEY

November 19, 2025 at 4:53 PM
MORE DATA + MORA ALGORITHM = MORE MONEY
This is why grading on a curve / ranking never made sense to me (we don't have any of that here) - because what if everyone sucked??
Also - grade (and degree!) inflation is crazy.
Also - grade (and degree!) inflation is crazy.
November 19, 2025 at 2:48 PM
This is why grading on a curve / ranking never made sense to me (we don't have any of that here) - because what if everyone sucked??
Also - grade (and degree!) inflation is crazy.
Also - grade (and degree!) inflation is crazy.
Cool!
I like spike-and-slab priors (or weighed posteriors) for the same reason! There's something really satisfying about forcing a model comparison problem into an estimation problem (I think people tend to go the other way)
I like spike-and-slab priors (or weighed posteriors) for the same reason! There's something really satisfying about forcing a model comparison problem into an estimation problem (I think people tend to go the other way)
November 19, 2025 at 6:57 AM
Cool!
I like spike-and-slab priors (or weighed posteriors) for the same reason! There's something really satisfying about forcing a model comparison problem into an estimation problem (I think people tend to go the other way)
I like spike-and-slab priors (or weighed posteriors) for the same reason! There's something really satisfying about forcing a model comparison problem into an estimation problem (I think people tend to go the other way)
Reposted by Mattan S. Ben-Shachar

No! Clearly the world consists of infinitely many small likelihoods and a massive prior simplex over them!

Skub
The Perry Bible Fellowship
share.google
November 19, 2025 at 6:51 AM
No! Clearly the world consists of infinitely many small likelihoods and a massive prior simplex over them!
I guess I just like thinking that there's an infinitely dimensioned likelihood function that we usually only take very thin slices from by setting *almost* all parameters to 0 😄
November 19, 2025 at 6:48 AM
I guess I just like thinking that there's an infinitely dimensioned likelihood function that we usually only take very thin slices from by setting *almost* all parameters to 0 😄
November 19, 2025 at 6:27 AM
which fits nicely both with posterior estimation, mixture model, and Bayes factors.
November 19, 2025 at 6:26 AM
which fits nicely both with posterior estimation, mixture model, and Bayes factors.
I would consider those weights to be part of the prior.
If we write the joint probability as:
p(data | parameters, model) p(parameters | model) p(model)
I would say the first term is the likelihood and both the second and third terms are the prior,
If we write the joint probability as:
p(data | parameters, model) p(parameters | model) p(model)
I would say the first term is the likelihood and both the second and third terms are the prior,
November 19, 2025 at 6:26 AM
I would consider those weights to be part of the prior.
If we write the joint probability as:
p(data | parameters, model) p(parameters | model) p(model)
I would say the first term is the likelihood and both the second and third terms are the prior,
If we write the joint probability as:
p(data | parameters, model) p(parameters | model) p(model)
I would say the first term is the likelihood and both the second and third terms are the prior,
Sure, but then any difference would thus be in the prior, no?
November 19, 2025 at 5:06 AM
Sure, but then any difference would thus be in the prior, no?
Bayes factors test **only priors**, not posteriors. So BF can (and often does) prefer one (prior) model over another while both priors have little consequences for the posterior (posteriors are similar).
November 19, 2025 at 4:29 AM
Bayes factors test **only priors**, not posteriors. So BF can (and often does) prefer one (prior) model over another while both priors have little consequences for the posterior (posteriors are similar).
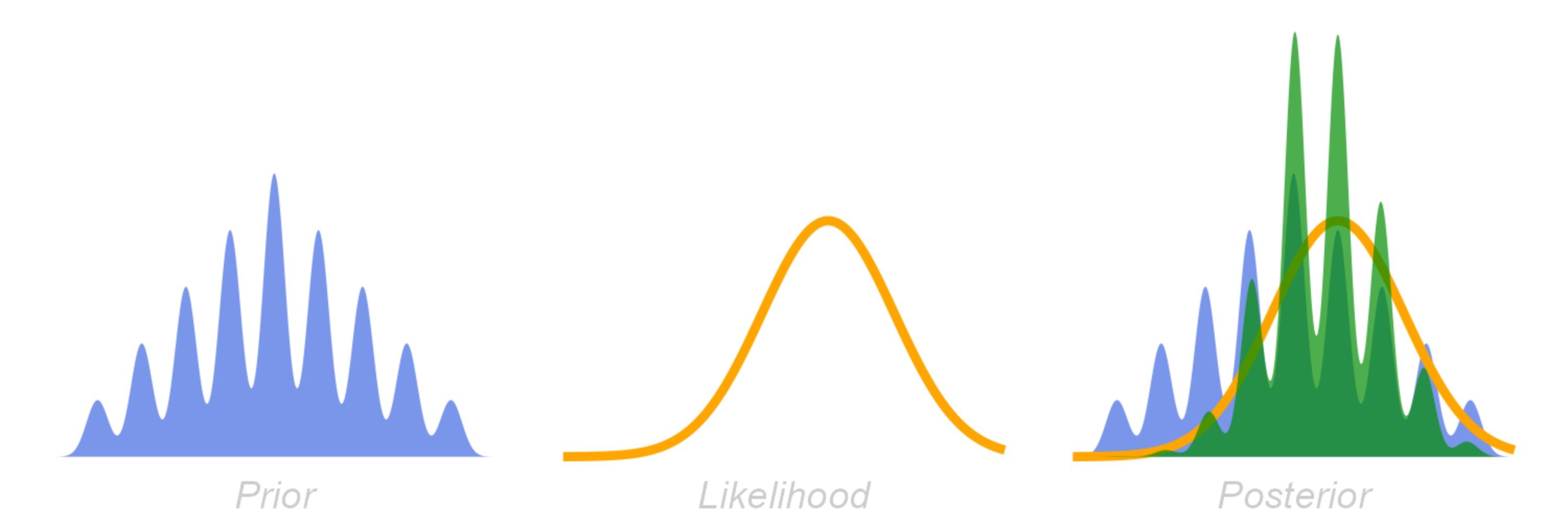
Seems not inconsequential IMO. It's weird though, because it's pulling very strongly in opposite directions - seems to result in a strange platykurtic shape? Compare to a flat prior (3rd image)



November 18, 2025 at 9:58 PM
Seems not inconsequential IMO. It's weird though, because it's pulling very strongly in opposite directions - seems to result in a strange platykurtic shape? Compare to a flat prior (3rd image)
Ah right you did! 🔥
November 18, 2025 at 6:53 PM
Ah right you did! 🔥
Reposted by Mattan S. Ben-Shachar

I had to check what I recommend in my book. And Poison priors (right) are also cursed. I'm working on something new with Gelman and Vehtari, so will make a note to review our examples for some consistency in these contexts.


November 18, 2025 at 3:07 PM
I had to check what I recommend in my book. And Poison priors (right) are also cursed. I'm working on something new with Gelman and Vehtari, so will make a note to review our examples for some consistency in these contexts.

logit priors.R
GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
November 18, 2025 at 6:38 PM
Yes but... The prior in the intercept in both brms and rstanarm is actually *not* for the intercept but for the intercept with all predictors mean-centered... (An unfortunate choice to have named it "prior intercept")
discourse.mc-stan.org/t/understand...
discourse.mc-stan.org/t/understand...

Understanding intercept prior in brms
Hi Everyone, The documentation of brms “prior” function says something about the intercept that sounds important, but I need help in understanding that. "the intercept has its own parameter class na...
discourse.mc-stan.org
November 18, 2025 at 6:28 PM
Yes but... The prior in the intercept in both brms and rstanarm is actually *not* for the intercept but for the intercept with all predictors mean-centered... (An unfortunate choice to have named it "prior intercept")
discourse.mc-stan.org/t/understand...
discourse.mc-stan.org/t/understand...
Looks interesting - I love Cohen's paper, so I'll definitely give this a read!
I'm not against all uses of NHST, but if it's between using it how it's being used and not using it at all, I'd prefer the latter 🤷♂️
I'm not against all uses of NHST, but if it's between using it how it's being used and not using it at all, I'd prefer the latter 🤷♂️
November 18, 2025 at 6:20 PM
Looks interesting - I love Cohen's paper, so I'll definitely give this a read!
I'm not against all uses of NHST, but if it's between using it how it's being used and not using it at all, I'd prefer the latter 🤷♂️
I'm not against all uses of NHST, but if it's between using it how it's being used and not using it at all, I'd prefer the latter 🤷♂️
Yeah, I am not a fan of the autoscale option - I think I'd prefer flat priors 🤷♂️
November 18, 2025 at 2:28 PM
Yeah, I am not a fan of the autoscale option - I think I'd prefer flat priors 🤷♂️
If B is BF, I'd have a hard time defending that - setting up a BF test is hard, and shouldn't be done as lightly as p values are requested.
November 18, 2025 at 2:26 PM
If B is BF, I'd have a hard time defending that - setting up a BF test is hard, and shouldn't be done as lightly as p values are requested.
Stupid logit, always ruining everything...
November 18, 2025 at 2:17 PM
Stupid logit, always ruining everything...
This might be part of a wider conversation about "how can I do better stats when my advisor/collaborators/reviewers only know bad stats?"
November 18, 2025 at 2:16 PM
This might be part of a wider conversation about "how can I do better stats when my advisor/collaborators/reviewers only know bad stats?"