




Dr. Jonathan Mall
@jonathanmall.bsky.social
LLMs, AI, Psychology and Speaking - Seeking to infuse technology with empathy. That's why I founded www.neuroflash.com. An AI platform driving brand-aligned marketing, and helping people connect and understand each other's perspectives.
I made an interactive conversation analysis of the (world changing?) #Trump #Zelenskyy #Vance conversation. (Transcript from @apnews.com)
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀

March 3, 2025 at 7:16 AM
I made an interactive conversation analysis of the (world changing?) #Trump #Zelenskyy #Vance conversation. (Transcript from @apnews.com)
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
The words we choose reveal more than we think. Language isn't just communication — it's a reflection of power, strategy, and worldview.

March 2, 2025 at 11:19 AM
The words we choose reveal more than we think. Language isn't just communication — it's a reflection of power, strategy, and worldview.
- Vance emphasized American interests and positioned himself as defending diplomacy.

March 2, 2025 at 11:19 AM
- Vance emphasized American interests and positioned himself as defending diplomacy.
- Zelensky focused on historical context ("2014," "occupied") and used "we" to suggest collective identity "We are staying in our country, staying strong."

March 2, 2025 at 11:19 AM
- Zelensky focused on historical context ("2014," "occupied") and used "we" to suggest collective identity "We are staying in our country, staying strong."
- Trump dominated the conversation (48.1% of total words) and used "you" 28 times, creating a confrontational tone "You don't have the cards. You're buried there."
- Trump's language was heavy on negation and control ("don't," "not," "no").
- Trump's language was heavy on negation and control ("don't," "not," "no").

March 2, 2025 at 11:19 AM
- Trump dominated the conversation (48.1% of total words) and used "you" 28 times, creating a confrontational tone "You don't have the cards. You're buried there."
- Trump's language was heavy on negation and control ("don't," "not," "no").
- Trump's language was heavy on negation and control ("don't," "not," "no").
I analyzed the Trump-Zelensky-Vance Transcript from @apnews.com, to see what stands behind their words - speaking volumes about power dynamics. 📊
Key Insights in thread
Key Insights in thread


March 2, 2025 at 11:19 AM
I analyzed the Trump-Zelensky-Vance Transcript from @apnews.com, to see what stands behind their words - speaking volumes about power dynamics. 📊
Key Insights in thread
Key Insights in thread
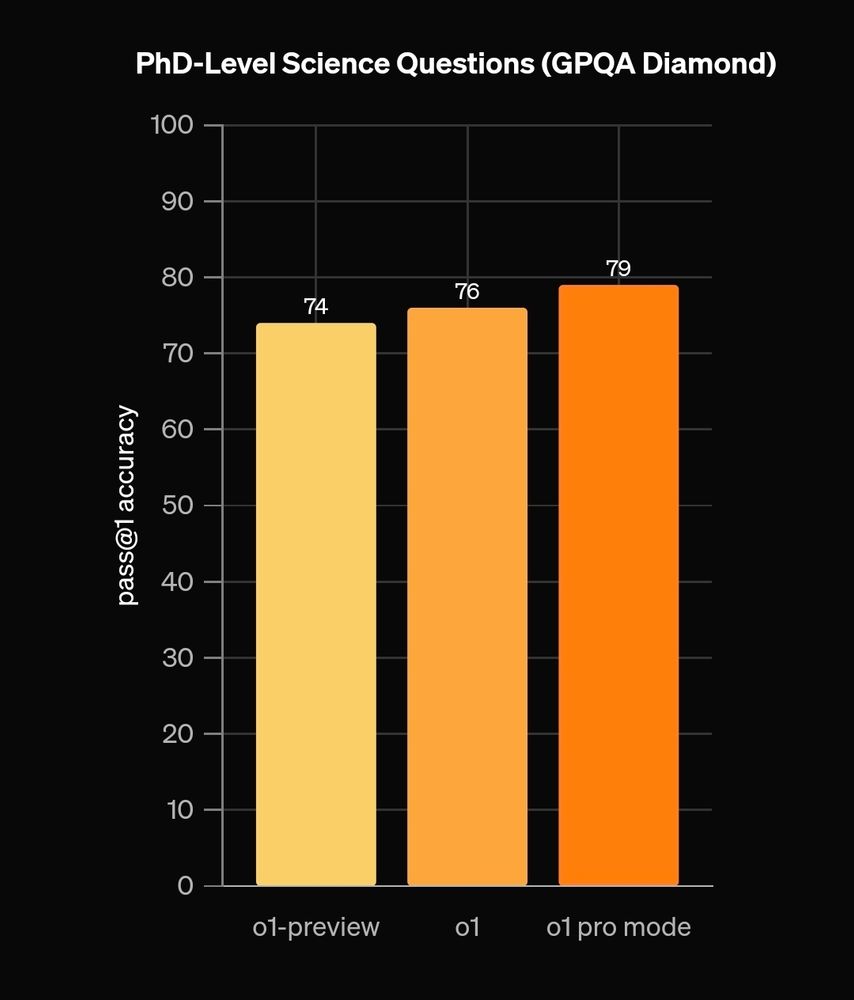
OpenAIs o1-pro model is only marginally better than the o1 model. But 10x the price ($20 to $200) to get access, not sure that's worth the qual increase.
Alternatively, do your own agentic or chain of thought prompting. Or go full professional with #dspy or #adalflow for auto prompt optimization.
Alternatively, do your own agentic or chain of thought prompting. Or go full professional with #dspy or #adalflow for auto prompt optimization.
December 6, 2024 at 9:43 AM
When predicting human sentiment responses for (german) words, Qwen 2.5 Coder 32B is doing worse than gpt4oMini.
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?

December 2, 2024 at 10:26 AM
When predicting human sentiment responses for (german) words, Qwen 2.5 Coder 32B is doing worse than gpt4oMini.
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
Using Perplexity instead of prompting to predict the more likely outcome of neuroscience experiments. Beating human experts by roughly 20% - wow.
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...

November 30, 2024 at 9:17 AM
Using Perplexity instead of prompting to predict the more likely outcome of neuroscience experiments. Beating human experts by roughly 20% - wow.
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Menlo Ventures shows that enterprise usage of anthropic has doubled in the last year.
Could it be because it's often better than openai? - for coding it's my go to model.
Could it be because it's often better than openai? - for coding it's my go to model.

November 30, 2024 at 8:40 AM
Menlo Ventures shows that enterprise usage of anthropic has doubled in the last year.
Could it be because it's often better than openai? - for coding it's my go to model.
Could it be because it's often better than openai? - for coding it's my go to model.
A year ago, Claude 2.1 had a 200K token context window with 27% accuracy on needle-in-haystack tests. Now, Alibaba's Qwen2.5-Turbo claims a 1M token window with 100% recall on similar tests.
@alanthompson.net
@alanthompson.net

November 30, 2024 at 8:33 AM
A year ago, Claude 2.1 had a 200K token context window with 27% accuracy on needle-in-haystack tests. Now, Alibaba's Qwen2.5-Turbo claims a 1M token window with 100% recall on similar tests.
@alanthompson.net
@alanthompson.net
Performant and actually open LLM was just released. (with training data and recipes etc.) will be testing OLMO soon. allenai.org/olmo

November 30, 2024 at 7:50 AM
Performant and actually open LLM was just released. (with training data and recipes etc.) will be testing OLMO soon. allenai.org/olmo
🚀 Just ran a simulation on 1,000 word ratings using human data + our improved LLM prompt for simulating responses. Results? We explain almost 80% of the variance! This approach could revolutionize how we model human emotions—customized for specific groups. 🔥 #AI #EmotionModeling

November 28, 2024 at 12:08 PM
🚀 Just ran a simulation on 1,000 word ratings using human data + our improved LLM prompt for simulating responses. Results? We explain almost 80% of the variance! This approach could revolutionize how we model human emotions—customized for specific groups. 🔥 #AI #EmotionModeling