




Dr. Jonathan Mall
@jonathanmall.bsky.social
LLMs, AI, Psychology and Speaking - Seeking to infuse technology with empathy. That's why I founded www.neuroflash.com. An AI platform driving brand-aligned marketing, and helping people connect and understand each other's perspectives.
I made an interactive conversation analysis of the (world changing?) #Trump #Zelenskyy #Vance conversation. (Transcript from @apnews.com)
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀

March 3, 2025 at 7:16 AM
I made an interactive conversation analysis of the (world changing?) #Trump #Zelenskyy #Vance conversation. (Transcript from @apnews.com)
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
claude.site/artifacts/f8...
Try it yourself — What stands out to you? 👀
I analyzed the Trump-Zelensky-Vance Transcript from @apnews.com, to see what stands behind their words - speaking volumes about power dynamics. 📊
Key Insights in thread
Key Insights in thread


March 2, 2025 at 11:19 AM
I analyzed the Trump-Zelensky-Vance Transcript from @apnews.com, to see what stands behind their words - speaking volumes about power dynamics. 📊
Key Insights in thread
Key Insights in thread
Reposted by Dr. Jonathan Mall

What is better than an LLM as a Judge? Right, an Agent as a Judge! Meta created an Agent-as-a-Judge to evaluate code agents to enable intermediate feedback alongside DevAI a new benchmark of 55 realistic development tasks.
Paper: huggingface.co/papers/2410....
Paper: huggingface.co/papers/2410....

Paper page - Agent-as-a-Judge: Evaluate Agents with Agents
Join the discussion on this paper page
huggingface.co
December 10, 2024 at 9:53 AM
What is better than an LLM as a Judge? Right, an Agent as a Judge! Meta created an Agent-as-a-Judge to evaluate code agents to enable intermediate feedback alongside DevAI a new benchmark of 55 realistic development tasks.
Paper: huggingface.co/papers/2410....
Paper: huggingface.co/papers/2410....
Reposted by Dr. Jonathan Mall

There is ZERO connection between vaccines and autism!
NONE!
NONE!

December 10, 2024 at 3:00 AM
There is ZERO connection between vaccines and autism!
NONE!
NONE!
Reposted by Dr. Jonathan Mall

Why is the government not capable wiping the floor with Nigel Farage every single day like this? Alastair Campbell effortlessly destroys him over his Brexit legacy which by almost every economic and financial measure has been disastrous for the country
December 6, 2024 at 6:41 AM
Why is the government not capable wiping the floor with Nigel Farage every single day like this? Alastair Campbell effortlessly destroys him over his Brexit legacy which by almost every economic and financial measure has been disastrous for the country
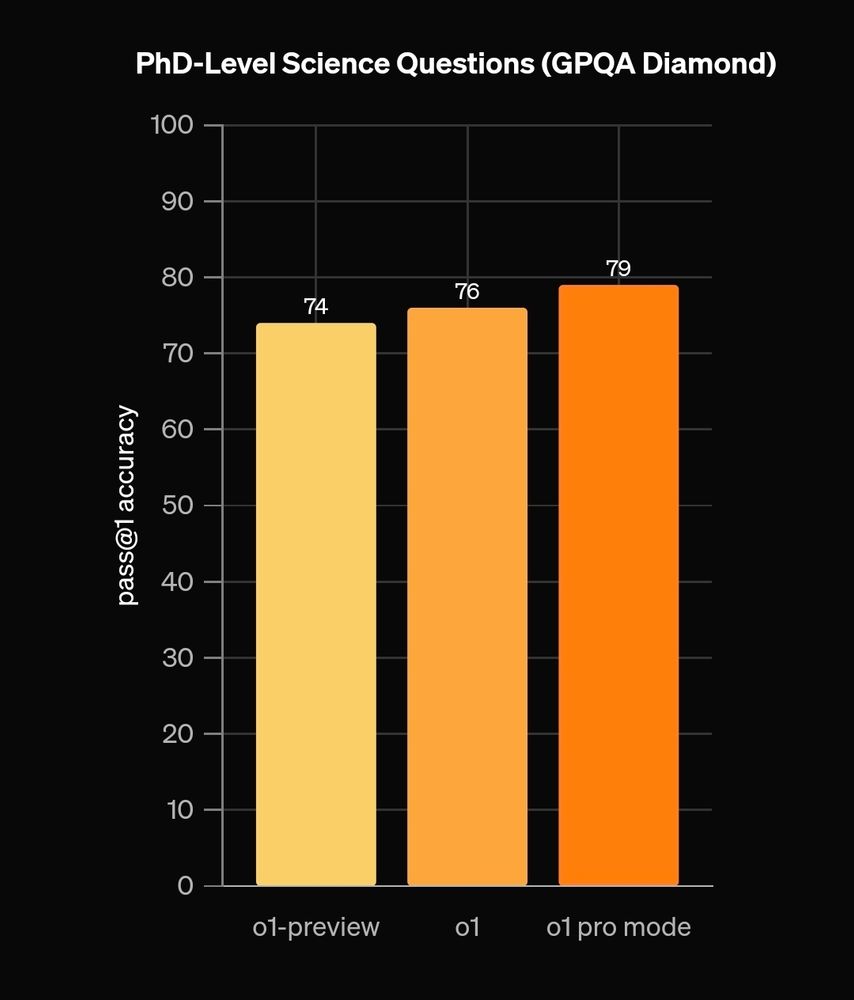
OpenAIs o1-pro model is only marginally better than the o1 model. But 10x the price ($20 to $200) to get access, not sure that's worth the qual increase.
Alternatively, do your own agentic or chain of thought prompting. Or go full professional with #dspy or #adalflow for auto prompt optimization.
Alternatively, do your own agentic or chain of thought prompting. Or go full professional with #dspy or #adalflow for auto prompt optimization.
December 6, 2024 at 9:43 AM
When predicting human sentiment responses for (german) words, Qwen 2.5 Coder 32B is doing worse than gpt4oMini.
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?

December 2, 2024 at 10:26 AM
When predicting human sentiment responses for (german) words, Qwen 2.5 Coder 32B is doing worse than gpt4oMini.
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
R squared is
0.845 for GPT4oMini
0.714 for Qwen2.4 Coder 32B
Many more comparisons to follow :)
Do you know a good LLM for European Languages?
Using Perplexity instead of prompting to predict the more likely outcome of neuroscience experiments. Beating human experts by roughly 20% - wow.
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...

November 30, 2024 at 9:17 AM
Using Perplexity instead of prompting to predict the more likely outcome of neuroscience experiments. Beating human experts by roughly 20% - wow.
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Could help to make research more efficient Imho. Especially since they've older models to achieve this!
www.nature.com/articles/s41...
Menlo Ventures shows that enterprise usage of anthropic has doubled in the last year.
Could it be because it's often better than openai? - for coding it's my go to model.
Could it be because it's often better than openai? - for coding it's my go to model.

November 30, 2024 at 8:40 AM
Menlo Ventures shows that enterprise usage of anthropic has doubled in the last year.
Could it be because it's often better than openai? - for coding it's my go to model.
Could it be because it's often better than openai? - for coding it's my go to model.
A year ago, Claude 2.1 had a 200K token context window with 27% accuracy on needle-in-haystack tests. Now, Alibaba's Qwen2.5-Turbo claims a 1M token window with 100% recall on similar tests.
@alanthompson.net
@alanthompson.net

November 30, 2024 at 8:33 AM
A year ago, Claude 2.1 had a 200K token context window with 27% accuracy on needle-in-haystack tests. Now, Alibaba's Qwen2.5-Turbo claims a 1M token window with 100% recall on similar tests.
@alanthompson.net
@alanthompson.net
SIFT introduces test-time learning by selecting highly relevant and non-redundant data for fine-tuning. Some call it Q-star 2.0. It optimizes information gain, reducing prediction uncertainty while using minimal compute - neat.
paper: arxiv.org/abs/2305.18466
Video: www.youtube.com/watch?v=vei7...
paper: arxiv.org/abs/2305.18466
Video: www.youtube.com/watch?v=vei7...

Test-Time Training on Nearest Neighbors for Large Language Models
Many recent efforts augment language models with retrieval, by adding retrieved data to the input context. For this approach to succeed, the retrieved data must be added at both training and test time...
arxiv.org
November 30, 2024 at 7:53 AM
SIFT introduces test-time learning by selecting highly relevant and non-redundant data for fine-tuning. Some call it Q-star 2.0. It optimizes information gain, reducing prediction uncertainty while using minimal compute - neat.
paper: arxiv.org/abs/2305.18466
Video: www.youtube.com/watch?v=vei7...
paper: arxiv.org/abs/2305.18466
Video: www.youtube.com/watch?v=vei7...
Performant and actually open LLM was just released. (with training data and recipes etc.) will be testing OLMO soon. allenai.org/olmo

November 30, 2024 at 7:50 AM
Performant and actually open LLM was just released. (with training data and recipes etc.) will be testing OLMO soon. allenai.org/olmo
Are instruct models becoming "too obedient"? When I prompt them with brand guidelines, and leave certain phrasen in, the llm will try to put those into virtually every content :D
Prompt engineering can mitigate, but its certainly different from the DaVinci days (gpt3)...old school completion.
Prompt engineering can mitigate, but its certainly different from the DaVinci days (gpt3)...old school completion.
November 30, 2024 at 7:16 AM
Are instruct models becoming "too obedient"? When I prompt them with brand guidelines, and leave certain phrasen in, the llm will try to put those into virtually every content :D
Prompt engineering can mitigate, but its certainly different from the DaVinci days (gpt3)...old school completion.
Prompt engineering can mitigate, but its certainly different from the DaVinci days (gpt3)...old school completion.
Reposted by Dr. Jonathan Mall

Happy Thanksgiving, everyone!
While you are drinking wine and drowning in turkey, I would encourage folks to think about:
What if Bluesky really is our shot at breaking the web2/socmedia stranglehold on collective sensemaking...
What kinds of trillionaire and sovereign attacks are coming?
While you are drinking wine and drowning in turkey, I would encourage folks to think about:
What if Bluesky really is our shot at breaking the web2/socmedia stranglehold on collective sensemaking...
What kinds of trillionaire and sovereign attacks are coming?
November 28, 2024 at 2:36 PM
Happy Thanksgiving, everyone!
While you are drinking wine and drowning in turkey, I would encourage folks to think about:
What if Bluesky really is our shot at breaking the web2/socmedia stranglehold on collective sensemaking...
What kinds of trillionaire and sovereign attacks are coming?
While you are drinking wine and drowning in turkey, I would encourage folks to think about:
What if Bluesky really is our shot at breaking the web2/socmedia stranglehold on collective sensemaking...
What kinds of trillionaire and sovereign attacks are coming?
🚀 Just ran a simulation on 1,000 word ratings using human data + our improved LLM prompt for simulating responses. Results? We explain almost 80% of the variance! This approach could revolutionize how we model human emotions—customized for specific groups. 🔥 #AI #EmotionModeling

November 28, 2024 at 12:08 PM
🚀 Just ran a simulation on 1,000 word ratings using human data + our improved LLM prompt for simulating responses. Results? We explain almost 80% of the variance! This approach could revolutionize how we model human emotions—customized for specific groups. 🔥 #AI #EmotionModeling