



Tanishq Mathew Abraham
@iscienceluvr.bsky.social
PhD at 19 |
Founder and CEO at @MedARC_AI |
Research Director at @StabilityAI |
@kaggle Notebooks GM |
Biomed. engineer @ 14 |
TEDx talk➡https://bit.ly/3tpAuan
Founder and CEO at @MedARC_AI |
Research Director at @StabilityAI |
@kaggle Notebooks GM |
Biomed. engineer @ 14 |
TEDx talk➡https://bit.ly/3tpAuan
Has anyone successfully done RL post-training of GPT-oss with meaningful performance gains?
What libraries even support it? I guess technically TRL/axolotl, maybe Unsloth... but there are no good examples of doing it...
What libraries even support it? I guess technically TRL/axolotl, maybe Unsloth... but there are no good examples of doing it...
September 4, 2025 at 10:48 PM
Has anyone successfully done RL post-training of GPT-oss with meaningful performance gains?
What libraries even support it? I guess technically TRL/axolotl, maybe Unsloth... but there are no good examples of doing it...
What libraries even support it? I guess technically TRL/axolotl, maybe Unsloth... but there are no good examples of doing it...
I have EXCITING news:
I've started a company!
Introducing Sophont
We’re building open multimodal foundation models for the future of healthcare. We need a DeepSeek for medical AI, and @sophontai.bsky.social will be that company!
Check out our website & blog post for more info (link below)
I've started a company!
Introducing Sophont
We’re building open multimodal foundation models for the future of healthcare. We need a DeepSeek for medical AI, and @sophontai.bsky.social will be that company!
Check out our website & blog post for more info (link below)

April 1, 2025 at 8:49 PM
I have EXCITING news:
I've started a company!
Introducing Sophont
We’re building open multimodal foundation models for the future of healthcare. We need a DeepSeek for medical AI, and @sophontai.bsky.social will be that company!
Check out our website & blog post for more info (link below)
I've started a company!
Introducing Sophont
We’re building open multimodal foundation models for the future of healthcare. We need a DeepSeek for medical AI, and @sophontai.bsky.social will be that company!
Check out our website & blog post for more info (link below)
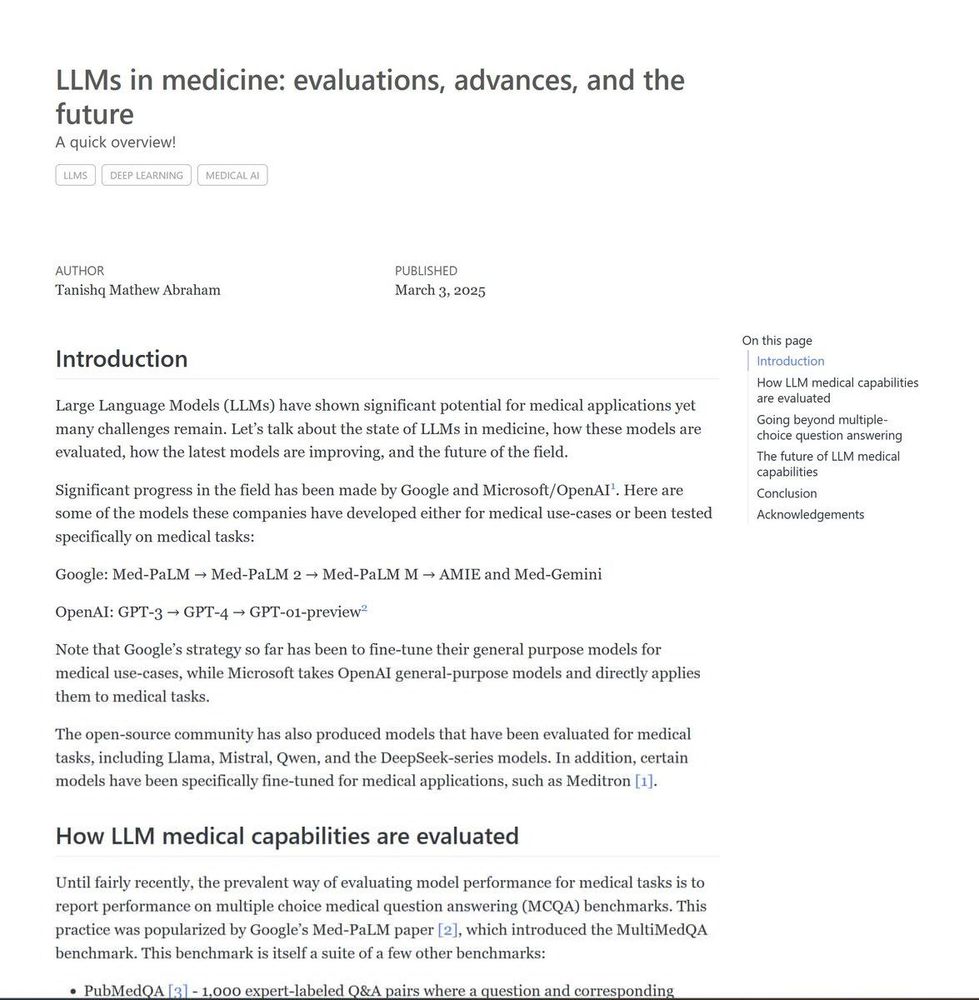
NEW BLOG POST: LLMs in medicine: evaluations, advances, and the future
www.tanishq.ai/blog/posts/l...
A short blog post discussing how LLMs are evaluated for medical capabilities and what's the future for LLMs in medicine (spoiler: it's reasoning!)
www.tanishq.ai/blog/posts/l...
A short blog post discussing how LLMs are evaluated for medical capabilities and what's the future for LLMs in medicine (spoiler: it's reasoning!)
March 17, 2025 at 8:08 AM
NEW BLOG POST: LLMs in medicine: evaluations, advances, and the future
www.tanishq.ai/blog/posts/l...
A short blog post discussing how LLMs are evaluated for medical capabilities and what's the future for LLMs in medicine (spoiler: it's reasoning!)
www.tanishq.ai/blog/posts/l...
A short blog post discussing how LLMs are evaluated for medical capabilities and what's the future for LLMs in medicine (spoiler: it's reasoning!)
I restarted my blog a few weeks ago. The 1st post was:
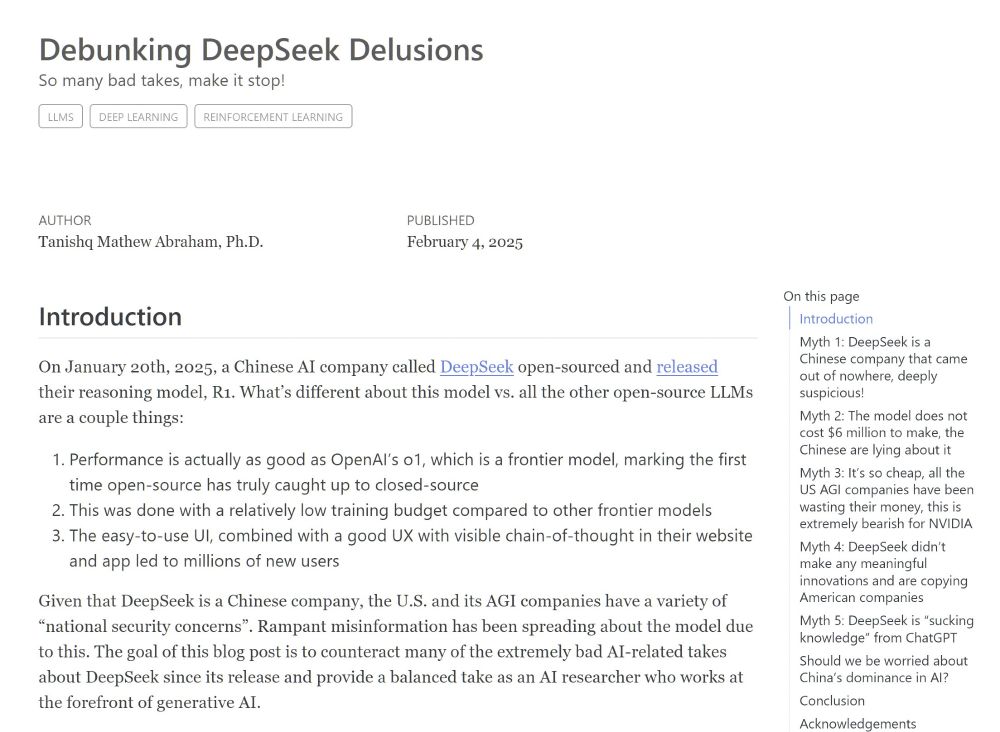
Debunking DeepSeek Delusions
I discussed 5 main myths that I saw spreading online back during the DeepSeek hype.
It may be a little less relevant now, but hopefully still interesting to folks.
Check it out → www.tanishq.ai/blog/posts/d...
Debunking DeepSeek Delusions
I discussed 5 main myths that I saw spreading online back during the DeepSeek hype.
It may be a little less relevant now, but hopefully still interesting to folks.
Check it out → www.tanishq.ai/blog/posts/d...
February 19, 2025 at 9:22 AM
I restarted my blog a few weeks ago. The 1st post was:
Debunking DeepSeek Delusions
I discussed 5 main myths that I saw spreading online back during the DeepSeek hype.
It may be a little less relevant now, but hopefully still interesting to folks.
Check it out → www.tanishq.ai/blog/posts/d...
Debunking DeepSeek Delusions
I discussed 5 main myths that I saw spreading online back during the DeepSeek hype.
It may be a little less relevant now, but hopefully still interesting to folks.
Check it out → www.tanishq.ai/blog/posts/d...
Are folks still here? 😅
February 19, 2025 at 8:39 AM
Are folks still here? 😅
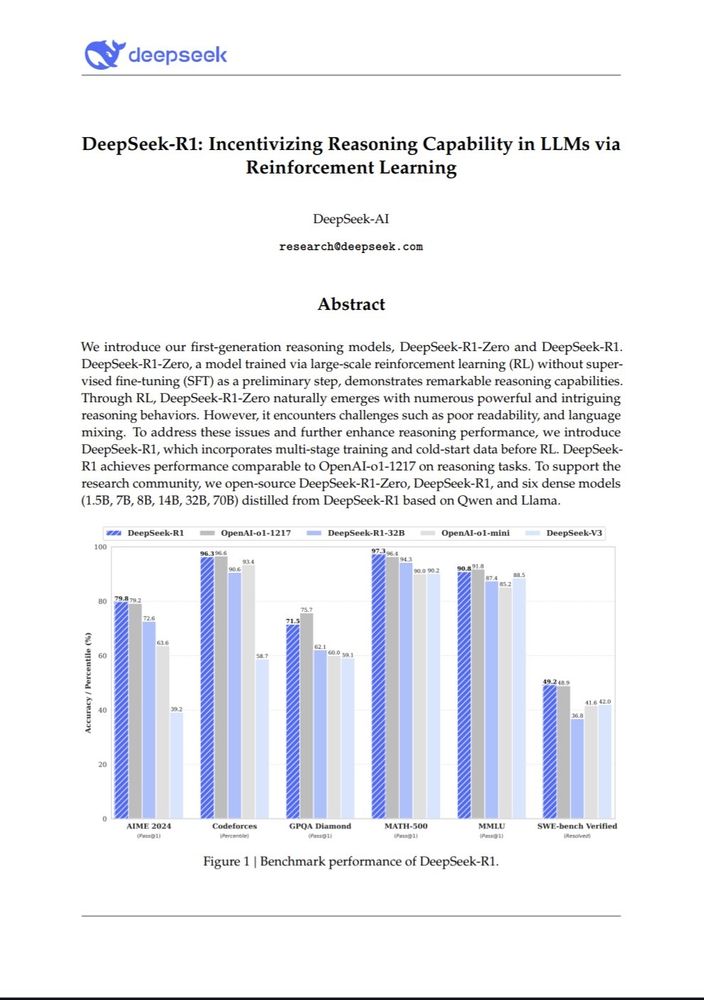
Okay so this is so far the most important paper in AI of the year
January 20, 2025 at 4:14 PM
Okay so this is so far the most important paper in AI of the year
Anthropic, please add a higher tier plan for unlimited messages 😭🙏

January 11, 2025 at 6:16 AM
Anthropic, please add a higher tier plan for unlimited messages 😭🙏
Decentralized Diffusion Models
UC Berkeley and Luma AI introduce Decentralized Diffusion Models, a way to train diffusion models on decentralized compute with no communication between nodes.
abs: arxiv.org/abs/2501.05450
project page: decentralizeddiffusion.github.io
UC Berkeley and Luma AI introduce Decentralized Diffusion Models, a way to train diffusion models on decentralized compute with no communication between nodes.
abs: arxiv.org/abs/2501.05450
project page: decentralizeddiffusion.github.io

January 10, 2025 at 10:15 AM
Decentralized Diffusion Models
UC Berkeley and Luma AI introduce Decentralized Diffusion Models, a way to train diffusion models on decentralized compute with no communication between nodes.
abs: arxiv.org/abs/2501.05450
project page: decentralizeddiffusion.github.io
UC Berkeley and Luma AI introduce Decentralized Diffusion Models, a way to train diffusion models on decentralized compute with no communication between nodes.
abs: arxiv.org/abs/2501.05450
project page: decentralizeddiffusion.github.io
The GAN is dead; long live the GAN! A Modern Baseline GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN

January 10, 2025 at 10:15 AM
The GAN is dead; long live the GAN! A Modern Baseline GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
This is a very interesting paper, exploring making GANs simpler and more performant.
abs: arxiv.org/abs/2501.05441
code: github.com/brownvc/R3GAN
Happy birthday to my incredible and awesome Mamma! 🥳🎉🎂
To many more years of health and happiness.
Tiara (my sister) and I love you very much ❤️❤️❤️
To many more years of health and happiness.
Tiara (my sister) and I love you very much ❤️❤️❤️



January 10, 2025 at 3:18 AM
Happy birthday to my incredible and awesome Mamma! 🥳🎉🎂
To many more years of health and happiness.
Tiara (my sister) and I love you very much ❤️❤️❤️
To many more years of health and happiness.
Tiara (my sister) and I love you very much ❤️❤️❤️
Happy 19th birthday to my amazing sister Tiara Abraham! 🥳🎉 🎂
Proud of you graduating with your Master's degree at 18 and starting your doctorate in music degree this past year!
Excited to see what this final teen year holds for you!
Proud of you graduating with your Master's degree at 18 and starting your doctorate in music degree this past year!
Excited to see what this final teen year holds for you!




December 28, 2024 at 4:02 AM
Happy 19th birthday to my amazing sister Tiara Abraham! 🥳🎉 🎂
Proud of you graduating with your Master's degree at 18 and starting your doctorate in music degree this past year!
Excited to see what this final teen year holds for you!
Proud of you graduating with your Master's degree at 18 and starting your doctorate in music degree this past year!
Excited to see what this final teen year holds for you!
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264

December 10, 2024 at 8:35 AM
Inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥
arxiv: arxiv.org/abs/2412.06264
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329

Normalizing Flows are Capable Generative Models
Normalizing Flows (NFs) are likelihood-based models for continuous inputs.
They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relati...
arxiv.org
December 10, 2024 at 8:06 AM
Normalizing Flows are Capable Generative Models
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Apple introduces TarFlow, a new Transformer-based variant of Masked Autoregressive Flows.
SOTA on likelihood estimation for images, quality and diversity comparable to diffusion models.
arxiv.org/abs/2412.06329
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
"We introduce a simple strategy that makes refusal behavior controllable at test-time without retraining: the refusal token."
arxiv.org/abs/2412.06748
"We introduce a simple strategy that makes refusal behavior controllable at test-time without retraining: the refusal token."
arxiv.org/abs/2412.06748

December 10, 2024 at 8:04 AM
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
"We introduce a simple strategy that makes refusal behavior controllable at test-time without retraining: the refusal token."
arxiv.org/abs/2412.06748
"We introduce a simple strategy that makes refusal behavior controllable at test-time without retraining: the refusal token."
arxiv.org/abs/2412.06748
Can foundation models actively gather information in interactive environments to test hypotheses?
"Our experiments with Gemini 1.5 reveal significant exploratory capabilities"
arxiv.org/abs/2412.06438
"Our experiments with Gemini 1.5 reveal significant exploratory capabilities"
arxiv.org/abs/2412.06438

December 10, 2024 at 8:03 AM
Can foundation models actively gather information in interactive environments to test hypotheses?
"Our experiments with Gemini 1.5 reveal significant exploratory capabilities"
arxiv.org/abs/2412.06438
"Our experiments with Gemini 1.5 reveal significant exploratory capabilities"
arxiv.org/abs/2412.06438
Training Large Language Models to Reason in a Continuous Latent Space
Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
arxiv.org/abs/2412.06769
Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
arxiv.org/abs/2412.06769

December 10, 2024 at 8:02 AM
Training Large Language Models to Reason in a Continuous Latent Space
Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
arxiv.org/abs/2412.06769
Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
arxiv.org/abs/2412.06769
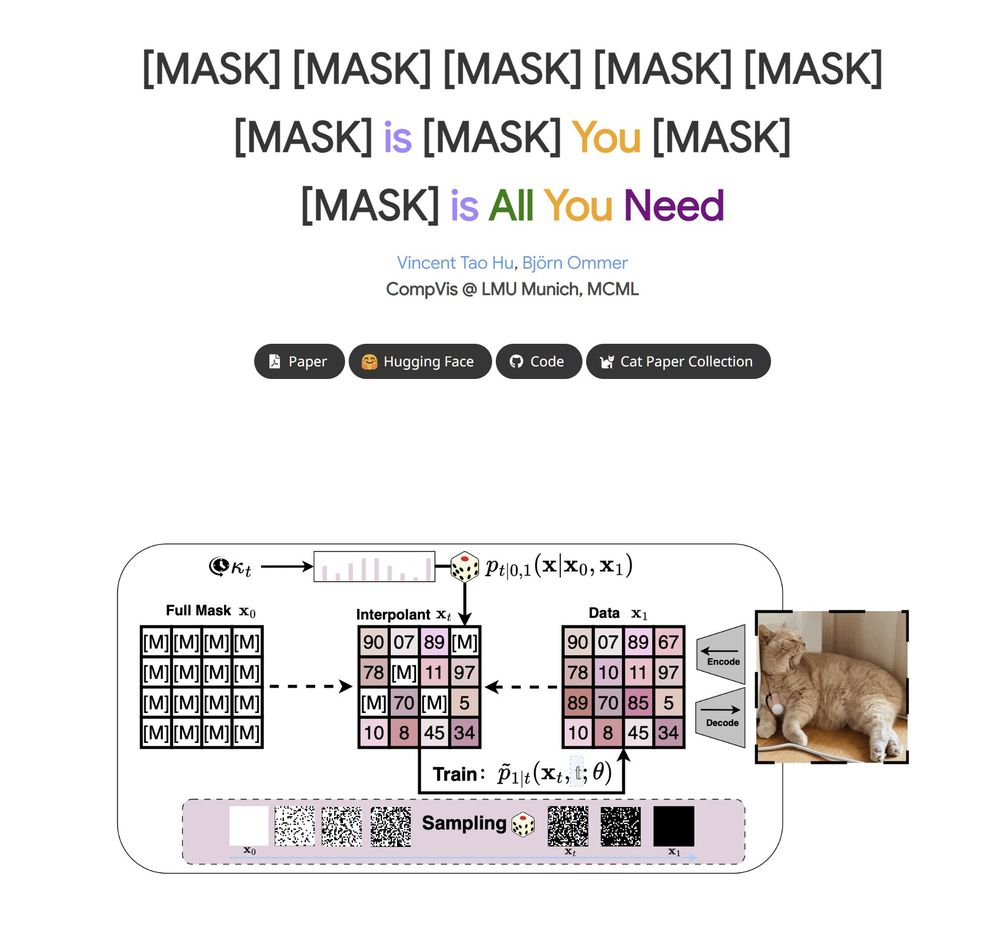
[MASK] is All You Need
New paper from CompVis group, introduces a new method called Discrete Interpolants that builds on top of discrete flow matching. Achieves SOTA performance on MS-COCO, competitive results on ImageNet 256.
arxiv.org/abs/2412.06787
New paper from CompVis group, introduces a new method called Discrete Interpolants that builds on top of discrete flow matching. Achieves SOTA performance on MS-COCO, competitive results on ImageNet 256.
arxiv.org/abs/2412.06787
December 10, 2024 at 8:01 AM
[MASK] is All You Need
New paper from CompVis group, introduces a new method called Discrete Interpolants that builds on top of discrete flow matching. Achieves SOTA performance on MS-COCO, competitive results on ImageNet 256.
arxiv.org/abs/2412.06787
New paper from CompVis group, introduces a new method called Discrete Interpolants that builds on top of discrete flow matching. Achieves SOTA performance on MS-COCO, competitive results on ImageNet 256.
arxiv.org/abs/2412.06787
A new tutorial on RL by Kevin Patrick Murphy, a Research Scientist at Google DeepMind who also wrote several comprehensive, well-regarded textbooks on ML/DL.
This ought to be a good read 👀
arxiv.org/abs/2412.05265
This ought to be a good read 👀
arxiv.org/abs/2412.05265

December 9, 2024 at 11:21 AM
A new tutorial on RL by Kevin Patrick Murphy, a Research Scientist at Google DeepMind who also wrote several comprehensive, well-regarded textbooks on ML/DL.
This ought to be a good read 👀
arxiv.org/abs/2412.05265
This ought to be a good read 👀
arxiv.org/abs/2412.05265
Birth and Death of a Rose
abs: arxiv.org/abs/2412.05278
Generating temporal object intrinsics - temporally evolving sequences of object geometry, reflectance, and texture, such as blooming of a rose - from pre-trained 2D foundation models.
abs: arxiv.org/abs/2412.05278
Generating temporal object intrinsics - temporally evolving sequences of object geometry, reflectance, and texture, such as blooming of a rose - from pre-trained 2D foundation models.
December 9, 2024 at 4:59 AM
Birth and Death of a Rose
abs: arxiv.org/abs/2412.05278
Generating temporal object intrinsics - temporally evolving sequences of object geometry, reflectance, and texture, such as blooming of a rose - from pre-trained 2D foundation models.
abs: arxiv.org/abs/2412.05278
Generating temporal object intrinsics - temporally evolving sequences of object geometry, reflectance, and texture, such as blooming of a rose - from pre-trained 2D foundation models.
Frontier Models are Capable of In-context Scheming
abs: arxiv.org/abs/2412.04984
"Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities"
abs: arxiv.org/abs/2412.04984
"Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities"

December 9, 2024 at 4:59 AM
Frontier Models are Capable of In-context Scheming
abs: arxiv.org/abs/2412.04984
"Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities"
abs: arxiv.org/abs/2412.04984
"Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities"
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
abs: arxiv.org/abs/2412.04626
project page: bigdocs.github.io
BigDocs-7.5M is a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks.
abs: arxiv.org/abs/2412.04626
project page: bigdocs.github.io
BigDocs-7.5M is a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks.

December 9, 2024 at 4:58 AM
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
abs: arxiv.org/abs/2412.04626
project page: bigdocs.github.io
BigDocs-7.5M is a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks.
abs: arxiv.org/abs/2412.04626
project page: bigdocs.github.io
BigDocs-7.5M is a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
abs: arxiv.org/abs/2412.05271
model: huggingface.co/OpenGVLab/In...
Introduces new InternVL-2.5 model, the first open-source MLLMs to surpass 70% on the MMMU benchmark
abs: arxiv.org/abs/2412.05271
model: huggingface.co/OpenGVLab/In...
Introduces new InternVL-2.5 model, the first open-source MLLMs to surpass 70% on the MMMU benchmark

December 9, 2024 at 4:57 AM
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
abs: arxiv.org/abs/2412.05271
model: huggingface.co/OpenGVLab/In...
Introduces new InternVL-2.5 model, the first open-source MLLMs to surpass 70% on the MMMU benchmark
abs: arxiv.org/abs/2412.05271
model: huggingface.co/OpenGVLab/In...
Introduces new InternVL-2.5 model, the first open-source MLLMs to surpass 70% on the MMMU benchmark
NVILA: Efficient Frontier Visual Language Models
abs: arxiv.org/abs/2412.04468
NVIDIA introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy.
abs: arxiv.org/abs/2412.04468
NVIDIA introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy.

December 6, 2024 at 1:36 PM
NVILA: Efficient Frontier Visual Language Models
abs: arxiv.org/abs/2412.04468
NVIDIA introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy.
abs: arxiv.org/abs/2412.04468
NVIDIA introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy.
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
abs: arxiv.org/abs/2412.04431
New visual autoregression framework that performs bitwise token prediction w/ an infinite-vocabulary tokenizer & classifier, a new record for autoregressive text-to-image models.
abs: arxiv.org/abs/2412.04431
New visual autoregression framework that performs bitwise token prediction w/ an infinite-vocabulary tokenizer & classifier, a new record for autoregressive text-to-image models.

December 6, 2024 at 1:35 PM
Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis
abs: arxiv.org/abs/2412.04431
New visual autoregression framework that performs bitwise token prediction w/ an infinite-vocabulary tokenizer & classifier, a new record for autoregressive text-to-image models.
abs: arxiv.org/abs/2412.04431
New visual autoregression framework that performs bitwise token prediction w/ an infinite-vocabulary tokenizer & classifier, a new record for autoregressive text-to-image models.
Reposted by Tanishq Mathew Abraham

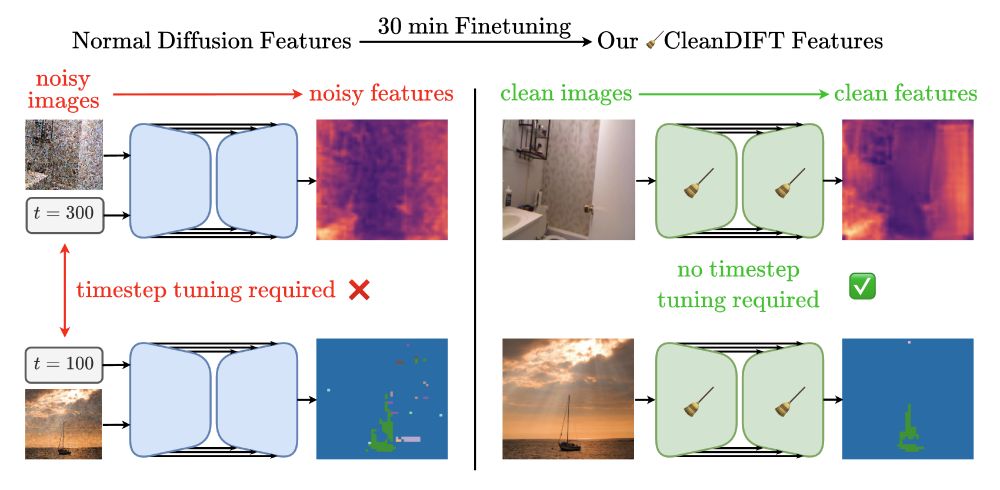
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
December 4, 2024 at 11:31 PM
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇