



Hyperplane
@hyperplane.bsky.social
Your weekly read. From POC to Production, at scale.
🫵 Follow our substack: https://thehyperplane.substack.com/
👀 Our Ebook: https://hyperplane.gumroad.com/l/fine-tuning-stt-on-edge
🫵 Follow our substack: https://thehyperplane.substack.com/
👀 Our Ebook: https://hyperplane.gumroad.com/l/fine-tuning-stt-on-edge
Updated link: hyperplane.gumroad.com/l/fine-tunin...

Fine-Tuning STT Models for Edge Devices
This eBook explores the challenges of speech-to-text (STT) models failing to recognize children's voices and provides a practical solution. We cover data preparation, model fine-tuning, and optimizati...
hyperplane.gumroad.com
May 6, 2025 at 3:00 PM
Updated link: hyperplane.gumroad.com/l/fine-tunin...
Launching tomorrow for all subscribers:
open.substack.com/pub/mlvangua...
open.substack.com/pub/mlvangua...

$0.00. No Gimmicks. The first real STT guide for kids’ voices on edge devices.
Everyone else sells vague theory for $49. We’re giving away real engineering, code and code for free.
open.substack.com
March 27, 2025 at 2:08 PM
Launching tomorrow for all subscribers:
open.substack.com/pub/mlvangua...
open.substack.com/pub/mlvangua...
Still better than no boat at all!
In all realness, code generation is a great assistant for an already great programmer 🤷
In all realness, code generation is a great assistant for an already great programmer 🤷
March 26, 2025 at 2:08 PM
Still better than no boat at all!
In all realness, code generation is a great assistant for an already great programmer 🤷
In all realness, code generation is a great assistant for an already great programmer 🤷
We show more in the upcoming eBook, free for all subscribers: mlvanguards.substack.com

ML Vanguards | Substack
Escaping PoC purgatory: Your Weekly Guide to production paradise. Click to read ML Vanguards, a Substack publication.
mlvanguards.substack.com
March 26, 2025 at 10:55 AM
We show more in the upcoming eBook, free for all subscribers: mlvanguards.substack.com
- Normalize & clean transcripts (remove garbage text, repeated words, weird artifacts)
- Filter out the junk
- Split (70/15/15) & push to @hf.co for easy access during training
2/2
- Filter out the junk
- Split (70/15/15) & push to @hf.co for easy access during training
2/2
March 26, 2025 at 10:55 AM
- Normalize & clean transcripts (remove garbage text, repeated words, weird artifacts)
- Filter out the junk
- Split (70/15/15) & push to @hf.co for easy access during training
2/2
- Filter out the junk
- Split (70/15/15) & push to @hf.co for easy access during training
2/2
It's kinda free for all newsletter subscribers: mlvanguards.substack.com
ML Vanguards | Substack
Escaping PoC purgatory: Your Weekly Guide to production paradise. Click to read ML Vanguards, a Substack publication.
mlvanguards.substack.com
March 24, 2025 at 8:43 PM
It's kinda free for all newsletter subscribers: mlvanguards.substack.com
Read more here: mlvanguards.substack.com/p/data-is-bo...
Data is boring
But broken search results are worse
mlvanguards.substack.com
March 24, 2025 at 12:18 PM
Read more here: mlvanguards.substack.com/p/data-is-bo...
6. Vector Database
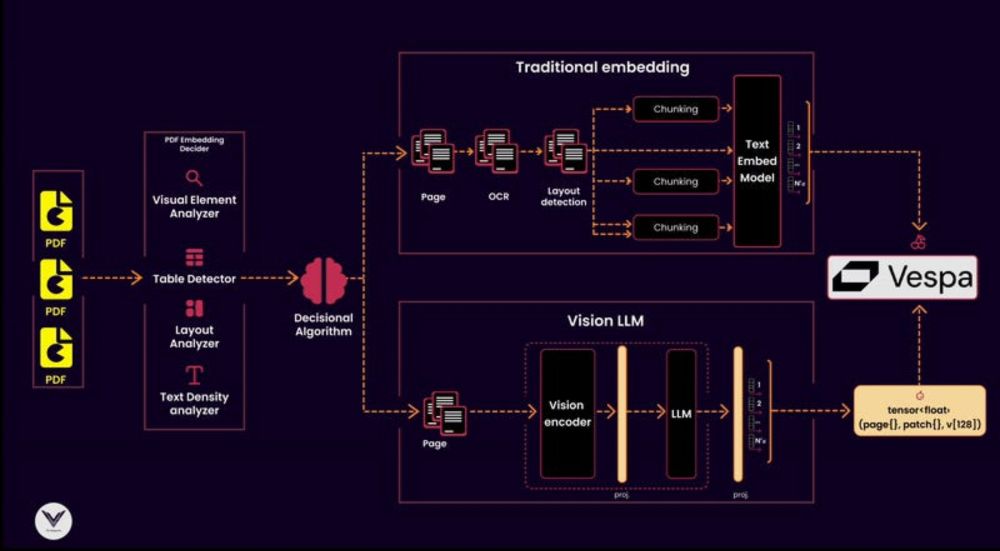
A vector database like Vespa store sembeddings and enable allowing similarity searches. They also use metadata to improve relevance by associating vectors with key attributes like document type, page number, or detected visual features.
7/7
A vector database like Vespa store sembeddings and enable allowing similarity searches. They also use metadata to improve relevance by associating vectors with key attributes like document type, page number, or detected visual features.
7/7
March 24, 2025 at 12:18 PM
6. Vector Database
A vector database like Vespa store sembeddings and enable allowing similarity searches. They also use metadata to improve relevance by associating vectors with key attributes like document type, page number, or detected visual features.
7/7
A vector database like Vespa store sembeddings and enable allowing similarity searches. They also use metadata to improve relevance by associating vectors with key attributes like document type, page number, or detected visual features.
7/7
5. Chunking Strategy
Splits documents into manageable chunks for embedding:
- Layout-based chunking is for visual embeddings.
- Text density and structure for traditional embeddings. This preserving context without overloading the vector database
6/7
Splits documents into manageable chunks for embedding:
- Layout-based chunking is for visual embeddings.
- Text density and structure for traditional embeddings. This preserving context without overloading the vector database
6/7
March 24, 2025 at 12:18 PM
5. Chunking Strategy
Splits documents into manageable chunks for embedding:
- Layout-based chunking is for visual embeddings.
- Text density and structure for traditional embeddings. This preserving context without overloading the vector database
6/7
Splits documents into manageable chunks for embedding:
- Layout-based chunking is for visual embeddings.
- Text density and structure for traditional embeddings. This preserving context without overloading the vector database
6/7
4. Embedding Models
For converting document content into vectors.
- Traditional embeddings for documents with clean text extracted via OCR.
- Vision Language Models (VLM) handle multimodal documents with complex visual structures like tables, charts, and diagrams.
5/7
For converting document content into vectors.
- Traditional embeddings for documents with clean text extracted via OCR.
- Vision Language Models (VLM) handle multimodal documents with complex visual structures like tables, charts, and diagrams.
5/7
March 24, 2025 at 12:18 PM
4. Embedding Models
For converting document content into vectors.
- Traditional embeddings for documents with clean text extracted via OCR.
- Vision Language Models (VLM) handle multimodal documents with complex visual structures like tables, charts, and diagrams.
5/7
For converting document content into vectors.
- Traditional embeddings for documents with clean text extracted via OCR.
- Vision Language Models (VLM) handle multimodal documents with complex visual structures like tables, charts, and diagrams.
5/7
3. Decisional Algorithm
The algorithm is centralized, making informed decisions based on input from the embedding decider.
- Text-heavy documents are processed with OCR and text embedding models.
- Documents with complex layouts use visual language models (eg ColPali) instead, skipping OCR.
4/7
The algorithm is centralized, making informed decisions based on input from the embedding decider.
- Text-heavy documents are processed with OCR and text embedding models.
- Documents with complex layouts use visual language models (eg ColPali) instead, skipping OCR.
4/7
March 24, 2025 at 12:18 PM
3. Decisional Algorithm
The algorithm is centralized, making informed decisions based on input from the embedding decider.
- Text-heavy documents are processed with OCR and text embedding models.
- Documents with complex layouts use visual language models (eg ColPali) instead, skipping OCR.
4/7
The algorithm is centralized, making informed decisions based on input from the embedding decider.
- Text-heavy documents are processed with OCR and text embedding models.
- Documents with complex layouts use visual language models (eg ColPali) instead, skipping OCR.
4/7
2. PDF Embedding Decider
This decider analyzes the document's structure, using tools like a layout analyzer, visual element detector, or text density analyzer, to classify whether a traditional text embedding or a multimodal vision embedding is appropriate.
3/7
This decider analyzes the document's structure, using tools like a layout analyzer, visual element detector, or text density analyzer, to classify whether a traditional text embedding or a multimodal vision embedding is appropriate.
3/7
March 24, 2025 at 12:18 PM
2. PDF Embedding Decider
This decider analyzes the document's structure, using tools like a layout analyzer, visual element detector, or text density analyzer, to classify whether a traditional text embedding or a multimodal vision embedding is appropriate.
3/7
This decider analyzes the document's structure, using tools like a layout analyzer, visual element detector, or text density analyzer, to classify whether a traditional text embedding or a multimodal vision embedding is appropriate.
3/7
1. PDF Reader
The starting point of any pipeline is the PDF reader. Its job is to extract pages and pass them downstream. A high-quality reader ensures no lost information, whether the content is text-heavy, image-dense, or filled with tables and graphs.
2/7
The starting point of any pipeline is the PDF reader. Its job is to extract pages and pass them downstream. A high-quality reader ensures no lost information, whether the content is text-heavy, image-dense, or filled with tables and graphs.
2/7
March 24, 2025 at 12:18 PM
1. PDF Reader
The starting point of any pipeline is the PDF reader. Its job is to extract pages and pass them downstream. A high-quality reader ensures no lost information, whether the content is text-heavy, image-dense, or filled with tables and graphs.
2/7
The starting point of any pipeline is the PDF reader. Its job is to extract pages and pass them downstream. A high-quality reader ensures no lost information, whether the content is text-heavy, image-dense, or filled with tables and graphs.
2/7