



Hyperplane
@hyperplane.bsky.social
Your weekly read. From POC to Production, at scale.
🫵 Follow our substack: https://thehyperplane.substack.com/
👀 Our Ebook: https://hyperplane.gumroad.com/l/fine-tuning-stt-on-edge
🫵 Follow our substack: https://thehyperplane.substack.com/
👀 Our Ebook: https://hyperplane.gumroad.com/l/fine-tuning-stt-on-edge
Finally made it! It’s been a long ride, but the first real STT guide for kids’ voices on edge devices is here. Check it out on Gumroad if you're curious!
the link for the book mlvanguards.gumroad.com/l/fine-tunin... (it's free)
the link for the book mlvanguards.gumroad.com/l/fine-tunin... (it's free)

April 2, 2025 at 2:05 PM
Finally made it! It’s been a long ride, but the first real STT guide for kids’ voices on edge devices is here. Check it out on Gumroad if you're curious!
the link for the book mlvanguards.gumroad.com/l/fine-tunin... (it's free)
the link for the book mlvanguards.gumroad.com/l/fine-tunin... (it's free)
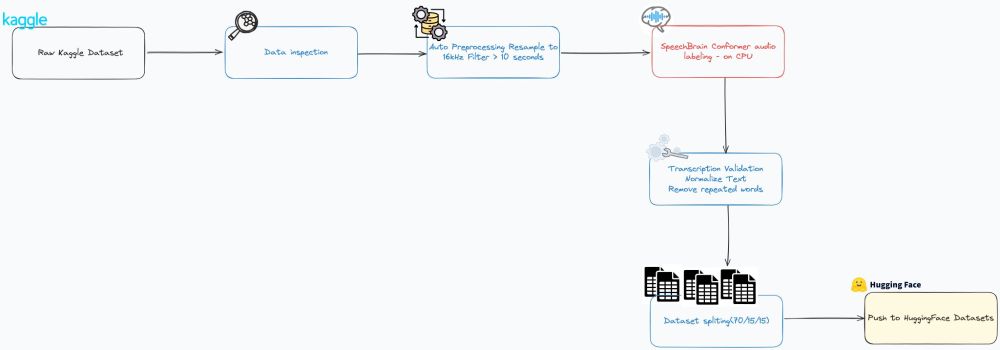
In less than 24 hours, we turned 5K messy files (from @kaggle.com) into a clean dataset of ~3.9K audio+transcription pairs.
Here’s how:
- Resample & filter (standardize to 16kHz, cut long/empty clips)
- Auto-transcribe with SpeechBrain (ran it on CPU — I'm GPU poor 😅)
1/2
Here’s how:
- Resample & filter (standardize to 16kHz, cut long/empty clips)
- Auto-transcribe with SpeechBrain (ran it on CPU — I'm GPU poor 😅)
1/2
March 26, 2025 at 10:55 AM
In less than 24 hours, we turned 5K messy files (from @kaggle.com) into a clean dataset of ~3.9K audio+transcription pairs.
Here’s how:
- Resample & filter (standardize to 16kHz, cut long/empty clips)
- Auto-transcribe with SpeechBrain (ran it on CPU — I'm GPU poor 😅)
1/2
Here’s how:
- Resample & filter (standardize to 16kHz, cut long/empty clips)
- Auto-transcribe with SpeechBrain (ran it on CPU — I'm GPU poor 😅)
1/2
We're launching an ebook on 28th this week 😳
Regular speech-to-text tech struggles with kids’ voices since they’re higher-pitched and less predictable.
We worked on that by creating a smaller, more accurate model that works well with children’s speech, even in noisy or low-power settings.
Regular speech-to-text tech struggles with kids’ voices since they’re higher-pitched and less predictable.
We worked on that by creating a smaller, more accurate model that works well with children’s speech, even in noisy or low-power settings.

March 24, 2025 at 8:42 PM
We're launching an ebook on 28th this week 😳
Regular speech-to-text tech struggles with kids’ voices since they’re higher-pitched and less predictable.
We worked on that by creating a smaller, more accurate model that works well with children’s speech, even in noisy or low-power settings.
Regular speech-to-text tech struggles with kids’ voices since they’re higher-pitched and less predictable.
We worked on that by creating a smaller, more accurate model that works well with children’s speech, even in noisy or low-power settings.
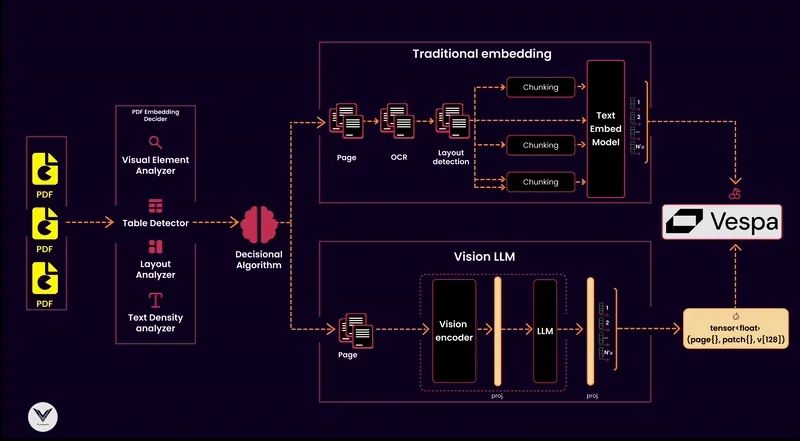
The principles of an indexing pipeline:
1/7
1/7
March 24, 2025 at 12:18 PM
The principles of an indexing pipeline:
1/7
1/7