



Reposted by Gilles Puy

🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
November 24, 2025 at 5:00 AM
🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
Reposted by Gilles Puy

The PhD graduation season in the team goes on!
Today, Corentin Sautier is defending his PhD on "Learning Actionable LiDAR Representations without Annotations".
Good luck! 🚀
Today, Corentin Sautier is defending his PhD on "Learning Actionable LiDAR Representations without Annotations".
Good luck! 🚀
Another great event for @valeoai.bsky.social team: a PhD defense of Corentin Sautier.
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).


October 7, 2025 at 1:40 PM
The PhD graduation season in the team goes on!
Today, Corentin Sautier is defending his PhD on "Learning Actionable LiDAR Representations without Annotations".
Good luck! 🚀
Today, Corentin Sautier is defending his PhD on "Learning Actionable LiDAR Representations without Annotations".
Good luck! 🚀
Reposted by Gilles Puy
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀

October 6, 2025 at 12:09 PM
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Update: ResearchGate has investigated the case, and, as far as I can see, all the suspicious papers (~200) have now been removed. Many thanks to the @researchgate.bsky.social team!
Discovered that our RangeViT paper keeps being cited in what might be LLM-generated papers. Number of citations increased rapidly in the last weeks. Too good to be true.
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
September 24, 2025 at 12:23 PM
Update: ResearchGate has investigated the case, and, as far as I can see, all the suspicious papers (~200) have now been removed. Many thanks to the @researchgate.bsky.social team!
Reposted by Gilles Puy

If you're interested in human pose estimation and mesh recovery from LiDAR data, we have this massive survey: arxiv.org/abs/2509.12197
Salma and Nermin put a tremendous amount of work in it, there's everything: the tasks, all the methods organized, datasets, numbers, challenges and opportunities.
Salma and Nermin put a tremendous amount of work in it, there's everything: the tasks, all the methods organized, datasets, numbers, challenges and opportunities.

3D Human Pose and Shape Estimation from LiDAR Point Clouds: A Review
In this paper, we present a comprehensive review of 3D human pose estimation and human mesh recovery from in-the-wild LiDAR point clouds. We compare existing approaches across several key dimensions, ...
arxiv.org
September 16, 2025 at 5:15 AM
If you're interested in human pose estimation and mesh recovery from LiDAR data, we have this massive survey: arxiv.org/abs/2509.12197
Salma and Nermin put a tremendous amount of work in it, there's everything: the tasks, all the methods organized, datasets, numbers, challenges and opportunities.
Salma and Nermin put a tremendous amount of work in it, there's everything: the tasks, all the methods organized, datasets, numbers, challenges and opportunities.
Discovered that our RangeViT paper keeps being cited in what might be LLM-generated papers. Number of citations increased rapidly in the last weeks. Too good to be true.
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
September 16, 2025 at 10:20 AM
Discovered that our RangeViT paper keeps being cited in what might be LLM-generated papers. Number of citations increased rapidly in the last weeks. Too good to be true.
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Reposted by Gilles Puy

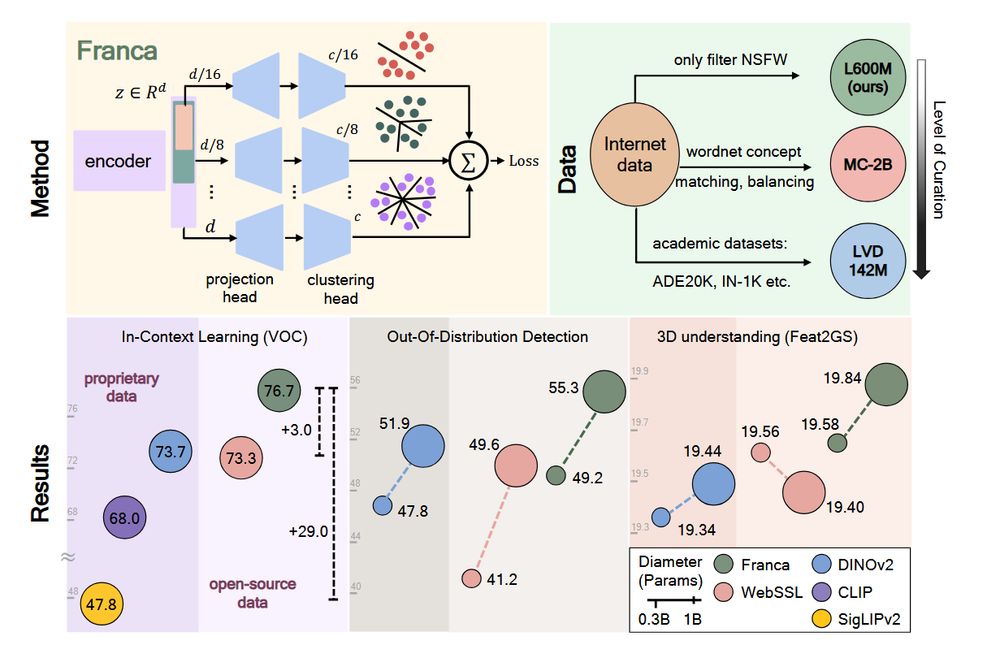
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
July 21, 2025 at 2:47 PM
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
Reposted by Gilles Puy

We just released the code of #LiDPM, go ahead and play with it (and don't forget to star 🤭🤩)!
Training and inference code available, along with the model checkpoint.
Github repo: github.com/astra-vision...
#IV2025
Training and inference code available, along with the model checkpoint.
Github repo: github.com/astra-vision...
#IV2025
June 25, 2025 at 8:05 PM
We just released the code of #LiDPM, go ahead and play with it (and don't forget to star 🤭🤩)!
Training and inference code available, along with the model checkpoint.
Github repo: github.com/astra-vision...
#IV2025
Training and inference code available, along with the model checkpoint.
Github repo: github.com/astra-vision...
#IV2025
Reposted by Gilles Puy

1/n 🚀New paper out - accepted at #ICCV2025!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!

June 25, 2025 at 7:21 PM
1/n 🚀New paper out - accepted at #ICCV2025!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Reposted by Gilles Puy
Presenting our project #LiDPM in the afternoon oral session at #IV2025!
Project page: astra-vision.github.io/LiDPM/
w/ @gillespuy.bsky.social, @alexandreboulch.bsky.social, Renaud Marlet, Raoul de Charette
Also, see our poster at 3pm in the Caravaggio room and AMA 😉
Project page: astra-vision.github.io/LiDPM/
w/ @gillespuy.bsky.social, @alexandreboulch.bsky.social, Renaud Marlet, Raoul de Charette
Also, see our poster at 3pm in the Caravaggio room and AMA 😉


June 23, 2025 at 10:12 AM
Presenting our project #LiDPM in the afternoon oral session at #IV2025!
Project page: astra-vision.github.io/LiDPM/
w/ @gillespuy.bsky.social, @alexandreboulch.bsky.social, Renaud Marlet, Raoul de Charette
Also, see our poster at 3pm in the Caravaggio room and AMA 😉
Project page: astra-vision.github.io/LiDPM/
w/ @gillespuy.bsky.social, @alexandreboulch.bsky.social, Renaud Marlet, Raoul de Charette
Also, see our poster at 3pm in the Caravaggio room and AMA 😉
Reposted by Gilles Puy
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇

March 3, 2025 at 10:19 AM
🚨 New preprint!
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
How far can we go with ImageNet for Text-to-Image generation? w. @arrijitghosh.bsky.social @lucasdegeorge.bsky.social @nicolasdufour.bsky.social @vickykalogeiton.bsky.social
TL;DR: Train a text-to-image model using 1000 less data in 200 GPU hrs!
📜https://arxiv.org/abs/2502.21318
🧵👇
Reposted by Gilles Puy
We @imagineenpc.bsky.social are slowly but surely entering our proposals for master's degree internships here: docs.google.com/document/d/1...
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.

2025 IMAGINE Internships
2025 Internship proposals at IMAGINE IMAGINE is a top research group on computer vision and machine learning. It is part of the LIGM lab and hosted at École des Ponts ParisTech (ENPC), about 25 min f...
docs.google.com
December 12, 2024 at 10:08 AM
We @imagineenpc.bsky.social are slowly but surely entering our proposals for master's degree internships here: docs.google.com/document/d/1...
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.
These are 6 months projects that typically correspond to the end-of-study project in the French curriculum.
Probably more offers to come, check it regularly.