



Björn Michele
@bjoernmichele.bsky.social
Research Scientist | Naver Labs Europe | Prev.: Ph.D. Student @ valeo.ai & IRISA OBELIX | Interested in the intersection of computer vision and frugal learning.
Website: bjoernmichele.com
Website: bjoernmichele.com
Pinned
🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
November 24, 2025 at 6:40 AM
For more details
📝 Paper: bmva-archive.org.uk/bmvc/2025/a...
💻 Code: github.com/valeoai/muddos
This is a joint work with my great co-authors @alexandreboulch.bsky.social, @gillespuy.bsky.social, @tuanhungvu.bsky.social, Renaud Marlet, @ncourty.bsky.social and myself.
📝 Paper: bmva-archive.org.uk/bmvc/2025/a...
💻 Code: github.com/valeoai/muddos
This is a joint work with my great co-authors @alexandreboulch.bsky.social, @gillespuy.bsky.social, @tuanhungvu.bsky.social, Renaud Marlet, @ncourty.bsky.social and myself.

GitHub - valeoai/muddos: Official repository of the BMVC 2025 paper "Improving Multimodal Distillation for 3D Semantic Segmentation under Domain Shift"
Official repository of the BMVC 2025 paper "Improving Multimodal Distillation for 3D Semantic Segmentation under Domain Shift" - valeoai/muddos
github.com
November 24, 2025 at 5:00 AM
For more details
📝 Paper: bmva-archive.org.uk/bmvc/2025/a...
💻 Code: github.com/valeoai/muddos
This is a joint work with my great co-authors @alexandreboulch.bsky.social, @gillespuy.bsky.social, @tuanhungvu.bsky.social, Renaud Marlet, @ncourty.bsky.social and myself.
📝 Paper: bmva-archive.org.uk/bmvc/2025/a...
💻 Code: github.com/valeoai/muddos
This is a joint work with my great co-authors @alexandreboulch.bsky.social, @gillespuy.bsky.social, @tuanhungvu.bsky.social, Renaud Marlet, @ncourty.bsky.social and myself.
Key findings:
1️⃣ The LiDAR backbone architecture has a major impact on cross-domain generalization.
2️⃣ A single pretrained backbone can generalize to many domain shifts.
3️⃣ Freezing the pretrained backbone + training only a small MLP head gives the best results.
1️⃣ The LiDAR backbone architecture has a major impact on cross-domain generalization.
2️⃣ A single pretrained backbone can generalize to many domain shifts.
3️⃣ Freezing the pretrained backbone + training only a small MLP head gives the best results.
November 24, 2025 at 5:00 AM
Key findings:
1️⃣ The LiDAR backbone architecture has a major impact on cross-domain generalization.
2️⃣ A single pretrained backbone can generalize to many domain shifts.
3️⃣ Freezing the pretrained backbone + training only a small MLP head gives the best results.
1️⃣ The LiDAR backbone architecture has a major impact on cross-domain generalization.
2️⃣ A single pretrained backbone can generalize to many domain shifts.
3️⃣ Freezing the pretrained backbone + training only a small MLP head gives the best results.
We systematically study how to best exploit vision foundation models (like DINOv2) for UDA on LiDAR data and identify practical “recipes” that consistently give strong performance across challenging real-world domain gaps.
November 24, 2025 at 5:00 AM
We systematically study how to best exploit vision foundation models (like DINOv2) for UDA on LiDAR data and identify practical “recipes” that consistently give strong performance across challenging real-world domain gaps.
🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
November 24, 2025 at 5:00 AM
🚗🌐 Working on domain adaptation for 3D point clouds / LiDAR?
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
We'll present MuDDoS at BMVC: a method that boosts multimodal distillation for 3D semantic segmentation under domain shift.
📍 BMVC
🕚 Monday, Poster Session 1: Multimodal Learning (11:00–12:30)
📌 Hadfield Hall #859
Reposted by Björn Michele

and Aniruddha Kembhavi, Adrien Gaidon, Nicolas Mansard, and Justin Carpentier as afternoon ones




November 21, 2025 at 8:38 PM
and Aniruddha Kembhavi, Adrien Gaidon, Nicolas Mansard, and Justin Carpentier as afternoon ones
Reposted by Björn Michele

One of those internships is on Gromov $\delta$-hyperbolicity for GNNs, and will be cosupervised together with Nicolas, myself and Laetitia Chapel. Take a look and spread the words !

I have several offers for Master internships / PhDs on graph ML funded by ERC MALAGA for 2026. Don't hesitate to contact me to apply!
All infos here: nkeriven.github.io/malaga/
All infos here: nkeriven.github.io/malaga/

MALAGA: Reinventing the Theory of Machine Learning on Large Graphs (ERC StG)
nkeriven.github.io
November 7, 2025 at 1:45 PM
One of those internships is on Gromov $\delta$-hyperbolicity for GNNs, and will be cosupervised together with Nicolas, myself and Laetitia Chapel. Take a look and spread the words !

Reposted by Björn Michele

Our recent research will be presented at @iccv.bsky.social! #ICCV2025
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...

October 17, 2025 at 10:10 PM
Our recent research will be presented at @iccv.bsky.social! #ICCV2025
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
We’ll present 5 papers about:
💡 self-supervised & representation learning
🌍 3D occupancy & multi-sensor perception
🧩 open-vocabulary segmentation
🧠 multimodal LLMs & explainability
valeoai.github.io/posts/iccv-2...
Reposted by Björn Michele

Come say hi to our poster October 21st at 11:45 poster session 1 (#399)! We introduce unsupervised post-training of ViTs that enhances dense features for in-context tasks.
First conference as a PhD student, really excited to meet new people.
First conference as a PhD student, really excited to meet new people.
1/n 🚀New paper out - accepted at #ICCV2025!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!

October 18, 2025 at 7:22 PM
Come say hi to our poster October 21st at 11:45 poster session 1 (#399)! We introduce unsupervised post-training of ViTs that enhances dense features for in-context tasks.
First conference as a PhD student, really excited to meet new people.
First conference as a PhD student, really excited to meet new people.
Reposted by Björn Michele

Aloha #iccv25 – here we come! Excited to be presenting new *St3R models PANSt3R, HAMSt3R & HOSt3R. We're also introducing ‘Geo4D' and ‘LUDVIG’ 🫢 giving invited talks and mentoring! Full @iccv.bsky.social
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
programme below (or tinyurl.com/asbn5b5d) 🧵1/9

ICCV 2025
5 papers, invited speaker, WiCV sponsor and Challenge sponsor
tinyurl.com
October 18, 2025 at 6:56 AM
Aloha #iccv25 – here we come! Excited to be presenting new *St3R models PANSt3R, HAMSt3R & HOSt3R. We're also introducing ‘Geo4D' and ‘LUDVIG’ 🫢 giving invited talks and mentoring! Full @iccv.bsky.social
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
Reposted by Björn Michele

Another great event for @valeoai.bsky.social team: a PhD defense of Corentin Sautier.
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).


October 7, 2025 at 12:29 PM
Another great event for @valeoai.bsky.social team: a PhD defense of Corentin Sautier.
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).
His thesis «Learning Actionable LiDAR Representations w/o Annotations» covers the papers BEVContrast (learning self-sup LiDAR features), SLidR, ScaLR (distillation), UNIT and Alpine (solving tasks w/o labels).
Thank you @skamalas.bsky.social ! Looking Forward to my Journey in Grenoble !
October 6, 2025 at 10:16 PM
Thank you @skamalas.bsky.social ! Looking Forward to my Journey in Grenoble !
Reposted by Björn Michele
So excited to attend the PhD defense of @bjoernmichele.bsky.social at @valeoai.bsky.social! He’s presenting his research results of the last 3 years in 3D domain adaptation: SALUDA (unsupervised DA), MuDDoS (multimodal UDA), TTYD (source-free UDA).


October 6, 2025 at 12:18 PM
So excited to attend the PhD defense of @bjoernmichele.bsky.social at @valeoai.bsky.social! He’s presenting his research results of the last 3 years in 3D domain adaptation: SALUDA (unsupervised DA), MuDDoS (multimodal UDA), TTYD (source-free UDA).
Reposted by Björn Michele
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀

October 6, 2025 at 12:09 PM
It’s PhD graduation season in the team!
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Today, @bjoernmichele.bsky.social is defending his PhD on "Domain Adaptation for 3D Data"
Best of luck! 🚀
Reposted by Björn Michele
Congratulations to our lab colleagues who have been named Outstanding Reviewers at #ICCV2025 👏
Andrei Bursuc @abursuc.bsky.social
Anh-Quan Cao @anhquancao.bsky.social
Renaud Marlet
Eloi Zablocki @eloizablocki.bsky.social
@iccv.bsky.social
iccv.thecvf.com/Conferences/...
Andrei Bursuc @abursuc.bsky.social
Anh-Quan Cao @anhquancao.bsky.social
Renaud Marlet
Eloi Zablocki @eloizablocki.bsky.social
@iccv.bsky.social
iccv.thecvf.com/Conferences/...
2025 ICCV Program Committee
iccv.thecvf.com
October 2, 2025 at 3:28 PM
Congratulations to our lab colleagues who have been named Outstanding Reviewers at #ICCV2025 👏
Andrei Bursuc @abursuc.bsky.social
Anh-Quan Cao @anhquancao.bsky.social
Renaud Marlet
Eloi Zablocki @eloizablocki.bsky.social
@iccv.bsky.social
iccv.thecvf.com/Conferences/...
Andrei Bursuc @abursuc.bsky.social
Anh-Quan Cao @anhquancao.bsky.social
Renaud Marlet
Eloi Zablocki @eloizablocki.bsky.social
@iccv.bsky.social
iccv.thecvf.com/Conferences/...
Reposted by Björn Michele

Discovered that our RangeViT paper keeps being cited in what might be LLM-generated papers. Number of citations increased rapidly in the last weeks. Too good to be true.
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
September 16, 2025 at 10:20 AM
Discovered that our RangeViT paper keeps being cited in what might be LLM-generated papers. Number of citations increased rapidly in the last weeks. Too good to be true.
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Papers popped up on different platforms, but mainly on ResearchGate with ~80 papers in just 3 weeks.
[1/]
Reposted by Björn Michele

SKADA-Bench : Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation On Diverse Modalities, has been published published in TMLR today 🚀. It was a huge team effort to design (and publish) an open source fully reproducible DA benchmark 🧵1/n. openreview.net/forum?id=k9F...
SKADA-Bench: Benchmarking Unsupervised Domain Adaptation Methods...
Unsupervised Domain Adaptation (DA) consists of adapting a model trained on a labeled source domain to perform well on an unlabeled target domain with some data distribution shift. While many...
openreview.net
July 29, 2025 at 12:54 PM
SKADA-Bench : Benchmarking Unsupervised Domain Adaptation Methods with Realistic Validation On Diverse Modalities, has been published published in TMLR today 🚀. It was a huge team effort to design (and publish) an open source fully reproducible DA benchmark 🧵1/n. openreview.net/forum?id=k9F...
Reposted by Björn Michele

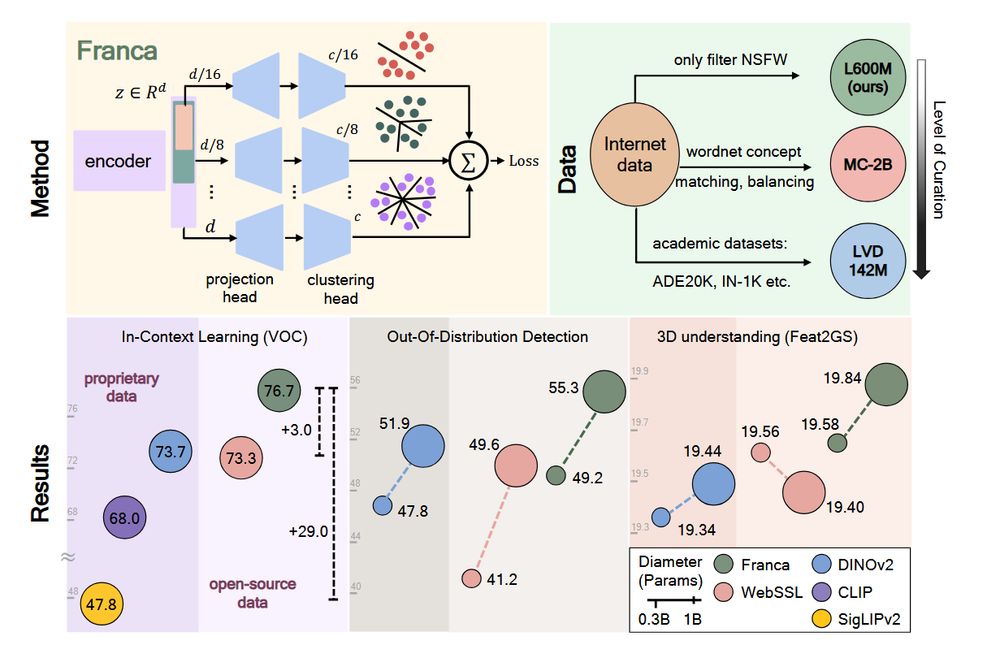
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
July 21, 2025 at 2:47 PM
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
The visualisation of the shifts is really great! Although finishing a thesis on domain adaptation for 3D, these shifts in the formal definition always remain a bit abstract for me, whereas with the visualisation in the space(s) it is much clearer.
July 2, 2025 at 7:18 AM
The visualisation of the shifts is really great! Although finishing a thesis on domain adaptation for 3D, these shifts in the formal definition always remain a bit abstract for me, whereas with the visualisation in the space(s) it is much clearer.
Reposted by Björn Michele
The most important aspect when facing data shift is the type of shift present in the data. I will give below a few examples of shifts and some existing methods to compensate for it.🧵1/6

July 1, 2025 at 9:39 AM
The most important aspect when facing data shift is the type of shift present in the data. I will give below a few examples of shifts and some existing methods to compensate for it.🧵1/6
I really enjoyed it! Generating the dataset myself, made it very easy to start and play with. Also while knowing on a high level the ideas of flow matching, it was great to do it once myself and to see also the steps in the code.
June 29, 2025 at 2:56 PM
I really enjoyed it! Generating the dataset myself, made it very easy to start and play with. Also while knowing on a high level the ideas of flow matching, it was great to do it once myself and to see also the steps in the code.
Reposted by Björn Michele

I wrote a notebook for a lecture/exercice on image generation with flow matching. The idea is to use FM to render images composed of simple shapes using their attributes (type, size, color, etc). Not super useful but fun and easy to train!
colab.research.google.com/drive/16GJyb...
Comments welcome!
colab.research.google.com/drive/16GJyb...
Comments welcome!

June 27, 2025 at 4:53 PM
I wrote a notebook for a lecture/exercice on image generation with flow matching. The idea is to use FM to render images composed of simple shapes using their attributes (type, size, color, etc). Not super useful but fun and easy to train!
colab.research.google.com/drive/16GJyb...
Comments welcome!
colab.research.google.com/drive/16GJyb...
Comments welcome!
Looks great ! I am sure some of your colleagues in the lab would also be interested to have a look in a lunch break on these handhelds 😅
June 29, 2025 at 10:16 AM
Looks great ! I am sure some of your colleagues in the lab would also be interested to have a look in a lunch break on these handhelds 😅
Reposted by Björn Michele
1/n 🚀New paper out - accepted at #ICCV2025!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
June 25, 2025 at 7:21 PM
1/n 🚀New paper out - accepted at #ICCV2025!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!
Introducing DIP: unsupervised post-training that enhances dense features in pretrained ViTs for dense in-context scene understanding
Below: Low-shot in-context semantic segmentation examples. DIP features outperform DINOv2!